



Datensicherung |
| Übersicht |


|
Die regelmäßige Sicherung des Datenbestandes zählt zu den wichtigsten Aufgaben eines Systemverwalters. Ein Datenverlust kann verschiedene Ursachen haben. Sei es durch einen Hardwareausfall, durch einen Softwarefehler, sei der Grund eine Fehlbedienung oder ein Virus oder es zeichnet sich gar eine dubiose Gestalt mit böswilligen Manipulationen dafür verantwortlich. Nach Murphy's Gesetz ereilt einen das Schicksal stets im unpassendsten Augenblick. Glück für denjenigen, der durch eine besonnene Strategie der Datensicherung den Schaden in Grenzen halten konnte.
Die Begriffe »Backup« und »Archiv« verwenden wir im weiteren Verlauf synonym. Allgemein bezeichnen wir als ein Archiv einen Container von Daten, der aufbewahrt wird, um genau auf diese Daten später zugreifen zu können. Archive legt man an, um momentan nicht benötigte Daten von der Festplatte zu verbannen oder um sie von einem Rechner auf einen anderen zu kopieren...
Die Motivation zu einem Backup resultiert aus anderen Überlegungen. Hier ist die Absicht, einen bestimmten Systemzustand aufzuzeichnen. Dabei bezieht man sich nicht auf den konkreten Inhalt einer Datei - wie bei Archiven - sondern ordnet eine Datei in die Schublade »wichtig« oder »unwichtig« ein, je nachdem, ob sie von meiner Backupstrategie betroffen sein wird oder nicht.
Grundsätzlich werden zwei Arten des Backups unterschieden. Das volle Backup sichert stets den kompletten Bestand an Daten, während das inkrementelle Backup nur Daten archiviert, die innerhalb einer bestimmten Periode modifiziert wurden. Dabei steht die Periode meist für den Zeitraum seit der letzten Sicherung.
Ein volles Backup ist wegen des hohen Bedarfs an Zeit (die Sicherung erfolgt meist auf ein Bandmedium) weniger für den täglichen Einsatz geeignet, deswegen entscheidet man sich heute meist für eine Mischform aus voller und inkrementeller Datensicherung. Hierbei wird zu einem Zeitpunkt der komplette Datenbestand gesichert und nachfolgend - in regelmäßigen Abständen - archiviert man nur die modifizierten Daten.
Die tatsächlich gewählte Strategie des inkrementellen Backups hängt stark von der »Statik« der Daten und vom Sicherheitsbedürfnis des Administrators ab. Im einfachsten Fall betrifft das Backup jeweils alle modifizierten Daten seit dem letzten vollen Backup bis hin zum aktuellen Zeitpunkt. Das umgekehrte Verfahren ist die Aufzeichnung der Änderungen seit der letzten inkrementellen Sicherung. Während in ersterem Fall nur die Archive des vollen und letzten inkrementellen Backups aufbewahrt werden müssen, sind beim zweiten Vorgehen das volle Backup und sämtliche inkrementellen Datensicherungsarchive aufzuheben. In der Praxis findet man auch Archivierungsformen zwischen den beiden beschriebenen Extremen (Multilevel-Backups).
Bedenken Sie, dass ein Festplattenfehler Sie auch während der Aufzeichnung eines Backups ereilen kann. Überschreiben Sie daher niemals ihre aktuelle Sicherungskopie.
Bei der Vorstellung der Backup-Werkzeuge beschränken wir uns auf Programme, die der GPL oder einer ähnlichen Lizenz unterstehen. In vielen Fällen lassen sie die Bedienfreundlichkeit kommerzieller Produkte vermissen, jedoch ist es durchaus möglich - die notwendigen Kenntnisse vorausgesetzt - diese in Skripten so zu kapseln, dass sie zum einen die Funktionalität und zum anderen die einfache Benutzbarkeit ausgereifter Werkzeuge erreichen.
| Medien für die Datensicherung |
|
Wohin mit den ganzen Daten?
Zunächst ist einfach nachvollziehbar, dass die Speicherkapazität des Backupmediums dem aufkommenden Datenvolumen entsprechen muss. Ein volles Backup könnte man durchaus auch auf Disketten vornehmen, jedoch wird man des Wechsels sicherlich bald überdrüssig und die Diskette ist selbst schon Quelle des lauernden Datenverlusts. Wer kennt nicht das leidige »Can't read sector xxx.«? Besser geeignet - vor allem bei dem geringeren Datenaufkommen des inkrementellen Backups - sind ZIP-Disketten.
Traditionell sind Magnetbänder (Quarter-Inch- und DAT-Streamer) weit verbreitet. Sowohl Kapazität als auch Zuverlässigkeit sprechen für dieses Medium. Leider lässt sich auf einem Band kein Dateisystem einrichten, so dass die Daten mit Hilfe spezieller Programme sequentiell auf dieses abgelegt werden müssen. Im Falle eines »Restores« muss demnach der gesamte Bandinhalt zurückgespielt werden, da ein wahlfreier Zugriff nicht möglich ist. Ein Magnetband muss vor dem Zugriff zurückgespult werden, hierzu nutzt man das Kommando mt mit der Option rewind:
| user@sonne> mt -f <Device> rewind |
Es ist außerdem möglich, mehr als ein Archiv auf einem Band unterzubringen, immer vorausgesetzt, die Speicherkapazität setzt keine Schranken:
|
# Band zur ersten Dateiende-Markierung spulen user@sonne> mt -f <Device> fsf 1 # Band zur dritten Dateiende-Markierung spulen user@sonne> mt -f <Device> fsf 3 # Band zur letzten Dateiende-Markierung spulen user@sonne> mt -f <Device> eof |
Waren früher die Medien für einem Streamer die preiswerteste Alternative, so geht heute nichts über eine Festplatte. Dem System eigens für die Datensicherung eine eigene Platte zu spendieren, mag auf den ersten Blick befremdend erscheinen, jedoch erhält man für den Preis eines Streamers eine Menge Festplattenspeicher. Die weiteren Vorteile liegen im wahlfreien und wesentlich zügigerem Zugriff. Allerdings schützt die eingebaute Festplatte nur mäßig vor mutwilliger Sabotage, hier kann eine Datensicherung auf einem anderen Rechner (über das Netz) Abhilfe bringen. Die durch RAID-Systeme realisierbare Datenredundanz schützt nur vor Hardwareausfall einer Festplatte, hat also nichts mit einem Backup zu tun!
Während sich die »normale« CD-ROM bzw. DVD wegen der nur einmaligen Beschreibbarkeit eher als Medium zur reinen Archivierung eignet, kann die CD-RW und vor allem die DVD-RW durchaus für die alltägliche Datensicherung eingesetzt werden. Allerdings erfordern umfangreiche Backups, die die Kapazität einer einzelnen CD-ROM übersteigen, die Anwesenheit des Administrators.
| Welche Daten sind Kandidaten? |
|
Es lohnt sich, etwas Zeit in den Plan zu investieren, welche Daten denn überhaupt den Aufwand eines Backups rechtfertigen.
Vielleicht beginnen wir mit Daten, die sichere Kandidaten sind. Da wären:
- Die Daten unter /home. Klar, die Benutzer ziehen sich ja täglich neue Daten aus dem Netz.
- Die Daten unter /etc. Oder haben Sie Interesse, Ihr System komplett neu konfigurieren zu müssen?
- Die Daten unter /var. Hier liegen Protokolle, Mails, Druckaufträge... also Daten, die i.d.R. permanenter Änderung unterliegen.
- Projektverzeichnisse, Datenbanken, ...???
Als Daten, deren Aufzeichnung Sie sich getrost sparen können, sind all jene zu nennen, die ohnehin auf einem anderen Medium vorhanden sind, z.B. die Daten der Linuxdistribution, die auf CD-ROM im Schrank liegen. Ebenso sollten Dateisysteme, die von entfernten Rechnern gemountet wurden, besser von dessen Backup-Strategie erfasst werden.
Aber letztlich ist es die Ermessensfrage des Administrators, welche Daten er für sicherungswürdig erachtet. Eine Neuinstallation von Linux hat ja manchmal auch den Vorteil, etwas Ordnung im System zu schaffen..
| Backup mit tar |
|
Der Tape Archiver ist das verbreitetste Werkzeug zur Datensicherung in Unix-Systemen. Ursprünglich rein zur Datenübertragung auf Bänder konzipiert, mit deren Hilfe der Datenaustausch zwischen verschiedenen Computern zu Zeiten fehlender Netzwerke ermöglicht werden sollte, hat sich gerade durch die Eignung von Bändern als Backupmedium das Programm quasi zum Standardwerkzeug für das Backup in kleineren Netzwerken etabliert, trotz des Fehlens einer brauchbaren Unterstützung von inkrementellen Backups.
Als Werkzeug zur Archivierung wurde tar im Kapitel Nutzerkommandos bereits vorgestellt. Hier soll nun der Schwerpunkt auf den Einsatz des Kommandos zum Backup von Daten liegen.
| Aufruf: tar [ OPTION... ] [ DATEI... ] |
tar arbeitet auf Dateiebene, kann also beliebige Dateien und Verzeichnisse in eine einzige Zieldatei verpacken. Zieldatei kann dabei alles bedeuten, was unter Unix als Datei betrachtet wird, also ein Gerät, eine normale Datei, eine Pipe...
Die drei wichtigsten Optionen sind c zum Erzeugen eines Archivs, t zum Betrachten des Archivinhalts und x zum Entpacken desselben.
Volles Backup
tar wird alle angegebenen Dateien (oder rekursiv den Inhalt von Verzeichnissen) in ein Archiv verpacken. Per Voreinstellung versucht das Kommando das Archiv auf einen Streamer zu schreiben (/dev/tape oder /dev/rmt0), ist kein solcher im System installiert, schreibt tar das Ergebnis auf die Standardausgabe. Um das Archiv in einer Datei zu sichern, ist die Option -f Datei zu wählen.
Eine angenehme Eigenschaft ist der Umgang mit »Multivolumes« (Option -M). Speichert man z.B. das Archiv auf eine Diskette und reicht deren Speicherkapazität nicht aus, so fordert tar automatisch zum Wechsel des Mediums auf:
| user@sonne> tar -Mcf /dev/fd0h1440
~/Books/ tar: Removing leading `/' from absolute path names in the archive Prepare volume #2 for /dev/fd0h1440 and hit return: Prepare volume #3 for /dev/fd0h1440 and hit return: Prepare volume #4 for /dev/fd0h1440 and hit return: |
Im Beispiel schreibt tar die Daten auf eine (unformatierte) Diskette, weswegen dem Kommando genau mitgeteilt werden muss, wie groß die Speicherkapazität dieser ist (es ist das entsprechende Device anzugeben). Als erstes entfernt tar in allen Pfadnamen den führenden Slash (-P forciert die Verwendung absoluter Pfadnamen), so dass das Archiv bei einem späteren Entpacken an beliebiger Stelle im Dateisystem extrahiert werden kann - bei Beibehaltung der Verzeichnisstruktur. Nachfolgend wird der Benutzer zum Wechsel der Disketten aufgefordert. Alternativ zu »-M« kann mit -L Anzahl der Medienwechsel nach Archivierung von Anzahl Bytes erzwungen werden.
Es ist allerdings furchtbar uneffizient, das Archiv unkomprimiert abzulegen. tar kann zum Glück mit mehreren Packern zusammen arbeiten. Mit -z wird das Archiv mit gzip komprimiert; -Z nutzt das (veraltete) Werkzeug compress und -j (alt: -I) den derzeit effektivsten Packalgorithmus des Kommandos bzip2. Wurde ein Archiv einmal gepackt, ist bei allen weiteren Operationen die Option für den jeweiligen Packer anzugeben! Das Packen funktioniert allerdings nicht bei Multilevel-Archiven. Ein Ausweg wäre das »vorab«-Komprimieren einer jeden Datei (z.B. mittels eines Skripts) mit anschließender Archivierung.
Inkrementelles Backup
tar unterstützt nur eine rudimentäre Variante des inkrementellen Backups, in dem Daten zur Archivierung ausgewählt werden können, die »neuer« als ein anzugebendes Datum sind. Das Datum (-n Datum) ist hierbei im Format »Jahr-Monat-Tag« anzugeben. Um z.B. alle Dateien zu erfassen, die in den letzten 7 Tagen (ab aktuellem Zeitpunkt) modifiziert wurden, kann folgender Kommandoaufruf verwendet werden:
| user@sonne> tar -n $(date -d "now 7 days ago" +%Y-%b-%d) -czf /tmp/backup.tgz ~/Books/ |
Im Beispiel wurde bewusst die etwas verwirrende Kalkulation des Datums mit Hilfe von date gewählt, da dessen Einsatz das Schreiben eines Skripts zum automatischen Erzeugen von inkrementellen Backups vereinfacht.
Überprüfung des Archives
Um sich von einer ordnungsgemäßen Archivierung zu überzeugen, sollte das resultierende Archiv einem Test unterzogen werden. Da der Slash automatisch entfernt wurde, ist zuvor ins Wurzelverzeichnis zu wechseln oder das Arbeitsverzeichnis mit -C Pfad zu ändern und (in Bezug auf obiges Beispiel) Folgendes aufzurufen:
| user@sonne> tar -C / -d -f /dev/fd0h1440 |
tar überzeugt sich nun, dass alle Dateien des Archivs auch im Dateisystem existieren. Sobald eine Unstimmigkeit festgestellt wird, wird das Kommando den Fehler ausgeben:
|
# Um einen Fehler zu provozieren, wurde eine Datei verschoben user@sonne> tar -df /dev/fd0h1440 home/user/Books/linuxfibel.pdf: File does not exist |
Recovery
Zu einem Backup gehört natürlich auch eine Möglichkeit, dieses wieder zurückzuspielen. Hier gelangt die Option -x (extract) zum Einsatz. Im Falle von relativen Pfadangaben im Archiv wird die Verzeichnisstruktur unterhalb des aktuellen Verzeichnisses erzeugt. Sie sollten also entweder zuvor ins Zielverzeichnis wechseln, oder dieses mit -C Pfad explizit angeben:
| user@sonne> tar -C / -x -f /dev/fd0h1440 |
Handelt es sich um ein auf mehrere Medien verteiltes Archiv, muss die Option -M angegeben werden. tar fordert dann zum Medienwechsel auf.
Möchten Sie nur einzelne Dateien extrahieren, sind deren Namen mit vollständiger Pfadangabe auf der Kommandozeile anzugeben. Hier hilft eventuell die Option -t, um den korrekten Namen, so wie er im Archiv gespeichert ist, zu erfahren:
|
user@sonne> tar tf /dev/fd0h1440 home/user/Books/access.htm home/user/Books/index.htm home/user/Books/stuff.htm home/user/Books/test.htm ... user@sonne> tar -C / -x -f /dev/fd0h1440 home/user/Books/index.htm |
Grafische Verpackung: kdat
Mit dem Programm kdat steht den KDE-Benutzern eine grafische Oberfläche zur Backupverwaltung mit tar zur Verfügung. Leider wird als Backupmedium derzeit nur das Tape unterstützt.

Abbildung 1: Backups mit kdat
Nach dem Start von kdat sollte unter dem Menüpunkt »Bearbeiten![]() Einstellungen« der Typ
des Tapes (Speicherkapazität, Device, Blockgröße) angepasst werden.
Einstellungen« der Typ
des Tapes (Speicherkapazität, Device, Blockgröße) angepasst werden.
Anschließend muss das Tape gemountet werden, wobei kdat testet, ob das Band formatiert ist und ggf. zu einer Formatierung auffordert (Vorsicht: eventueller Datenverlust). Das vorgeschlagene »Label« kann übernommen werden, es ist ein eindeutiger Name für das Backup.
Im Hauptfenster ist der Verzeichnisbaum u.a. des Rechners dargestellt. Jedes zu
sicherne Verzeichnis bzw. jede Datei ist durch Klick mit der rechten Maustaste zu
selektieren. Ein Verzeichnis schließt dabei die enthaltenen Dateien/Verzeichnisse
ein, wobei diese wiederum von einer Sicherung ausgeschlossen werden können. Ein
markierter Eintrag ist hervorgehoben dargestellt. Über das Sichern-Symbol (oder
»Datei![]() Sichern«) werden alle selektierten Dateien und Verzeichnisse auf das Tape
geschrieben.
Sichern«) werden alle selektierten Dateien und Verzeichnisse auf das Tape
geschrieben.
Um nicht bei jedem Aufruf die Dateien einzeln markieren zu müssen, können beliebig viele Sicherungsprofile angelegt werden. Jedes Profil enthält eine Liste der zu sichernden Daten.
| Backup mit cpio |
|
cpio (cpio in/out) besitzt einen ähnlichen Funktionsumfang wie das zuvor beschriebene Kommando tar, so dass wohl eher die Vorliebe des Benutzers das eine oder andere Werkzeug favorisiert. Ein Vorteil wäre dennoch zu nennen: cpio verzweifelt nicht an beschädigten Archiven und vermag zumindest den unversehrten Teil komplett wieder herzustellen.
| Aufruf: cpio MODUS [ OPTIONEN ] |
cpio kennt drei Betriebsarten:
- copy in zum Extrahieren von Dateien aus einem Archiv: Option -i
- copy out zum Erzeugen eines Archivs: Option -o
- pass througth als Kombination aus den obigen Modi erlaubt das Kopieren ganzer Verzeichnisbäume: Option -p
Volles und inkrementelles Backup
Um Dateien in einem cpio-Archiv zu speichern, müssen deren Namen dem Kommando mitgeteilt werden. cpio erwartet allerdings, dass jeder Dateiname auf einer neuen Zeile erscheint. Deshalb füttert man das Kommando am einfachsten über eine Pipe:
|
user@sonne> ls *.txt | cpio -o > /dev/fd0 11 blocks |
Das Beispiel sichert alle auf ".txt" endenden Dateien des aktuellen Verzeichnisses auf die Diskette. Die Ausgabeumleitung ist wichtig, da sonst die Dateiinhalte auf dem Bildschirm landen würden.
Hiermit kennen Sie nun das Prinzip des Backups mit cpio; zur Implementierung eines inkrementellen Backups bietet sich die Nutzung der Möglichkeiten des Kommandos find an, mit dem nach den verschiedensten Kriterien nach Dateien gefahndet werden kann. So archiviert der Aufruf von:
|
user@sonne> find /etc -maxdepth 2 -depth | cpio -o > /dev/fd0 319 blocks |
alle Dateien aus dem Verzeichnis /etc, wobei alle Unterverzeichnisse, nicht aber die darin befindlichen Unterverzeichnisse berücksichtigt werden. Die Option »-depth« von find bewirkt, dass der Name eines Verzeichnisses selbst erst nach den enthaltenden Daten ausgegeben wird. Bei eventuellem Zurückschreiben der Daten, wird nun der häufige Fehler verhindert, dass ein Verzeichnis mit »falschen« Zugriffsrechten erzeugt wurde und anschließend das Übertragen der Daten in dieses scheitert. Durch die hier gewählte Reihenfolge wird mit der ersten Datei aus dem Verzeichnis dieses mit den korrekten Rechten gesetzt (mit Rechten, die das Schreiben der Datei ermöglichen).
Im Sinne eines inkrementellen Backups ist aber sicher die Suche nach Dateien, die innerhalb einer bestimmten Zeitspanne geändert wurden, interessant. Der nächste Aufruf findet alle Dateien des Verzeichnisses /etc, deren Modifikationszeit nicht älter als 5 Tage ist:
|
root@sonne> find /etc -mtime -5 -maxdepth 2 -depth | cpio -o > /dev/fd0 112 blocks |
Überprüfung des Archives
Um sich eine Liste der Dateien eines Archives zu betrachten, ruft man das Kommando im »copy in«-Modus auf:
|
user@sonne> cpio -itvI /dev/fd0 -rw-r--r-- 1 root root 270 Aug 15 07:07 /etc/mtab -rw-r--r-- 1 root root 2510 Aug 10 13:49 /etc/logfiles -rw-r--r-- 1 root root 37911 Aug 15 07:06 /etc/ld.so.cache -rw-r--r-- 1 root root 271 Aug 10 15:27 /etc/hosts.allow -rw-r--r-- 1 root root 5762 Aug 10 15:27 /etc/inetd.conf -rw-r--r-- 1 root root 3349 Aug 14 12:18 /etc/printcap -rw------- 1 root root 60 Aug 15 07:06 /etc/ioctl.save -rw-r--r-- 1 root root 3799 Aug 15 09:10 /etc/XF86Config -rw------- 1 root root 512 Aug 15 07:07 /etc/ssh_random_seed -rw-r--r-- 1 root root 3309 Aug 14 12:18 /etc/printcap.old -rw-rw---- 1 lp lp 1244 Aug 14 12:05 /etc/apsfilterrc.ljet4 -rw-rw---- 1 lp lp 1261 Aug 14 12:37 /etc/apsfilterrc.lj4dith -rw-r--r-- 1 root root 88 Aug 15 09:38 /etc/dumpdates drwxr-xr-x 30 root root 0 Aug 15 08:28 /etc 112 blocks |
Die Option -t bewirkt die Anzeige des Archivinhalts und verhindert das Entpacken. -v bringt die Rechte der Dateien zum Vorschein und -I Archiv lässt cpio die Daten aus dem Archiv anstatt von der Standardeingabe lesen.
Ein Vergleich der Dateien im Archiv mit den Dateien im Verzeichnisbaum ist nicht direkt möglich. Hier kann nur ein Entpacken der Daten in ein separates Verzeichnis mit anschließendem Dateivergleich (z.B. mit diff) helfen.
Recovery
Schließlich möchte man die Daten auch wieder zurückschreiben können. Hierzu ist cpio im »copy-in«-Modus wie folgt zu starten:
|
root@sonne> cpio -id /etc/mtab < /dev/fd0 cpio: /etc/mtab not created: newer or same age version exists 112 blocks |
Im Beispiel stellt cpio nur fest, dass die gewünschte Datei nicht älter ist als die im Archiv enthaltene Version. Also tut das Kommando nichts. -d erzwingt das Anlegen von Verzeichnissen, falls diese nicht schon existieren, die nachfolgende Angabe von zu rekonstruierenden Dateien kann entfallen, dann werden alle Dateien aus dem Archiv extrahiert.
| Backup mit dump und restore |
|
tar und cpio enthalten wenige Eigenschaften, die man sich von einem guten Backup-Werkzeug wünscht. Zwar sind beide effektiv zum Erzeugen voller Backups geeignet, jedoch besitzen sie von Haus aus keinerlei Unterstützung inkrementeller Datensicherungsstrategien. Allerdings passen sie mit ihrer Philosophie ideal in das Kommandokonzept von Unix, wo jedes Standardkommando einen »sinnvollen« Funktionsumfang mit sich bringen sollte und alle komplexeren Aufgaben durch Kombination der Grundbausteine realisiert werden. Ein Backup wird auch heute häufig auf Basis von Shellskripten und unter Verwendung der bereits vorgestellten Kommandos implementiert.
dump hingegen verdient die Bezeichnung eines Backup-Werkzeuges. Es vermag sowohl mit vollen als auch mit inkrementellen Backups umzugehen, wobei letztere in bis zu 9 Abstufungen vorgenommen werden können.
Multilevel-Backups
Ein Multilevel-Backup bezeichnet eine Strategie, wobei ein volles Backup mit inkrementellen Backups kombiniert wird. Im einfachsten Fall wird einmal in einem Monat ein volles Backup des Datenbestandes vorgenommen und anschließend werden täglich nur die modifizierten Dateien gesichert. Dem vollen Backup wird hierbei das Level 0 zugeordnet und die weiteren Sicherungen erhalten das Level 1. Nach Ablauf des Monats wiederholt sich der Vorgang.
Eine Verallgemeinerung führt nun beliebig viele Level ein, wobei bei einem Backup des Levels x alle geänderten Daten im Zeitraum seit der letzten Sicherung desselben Levels berücksichtigt werden.
Der Sinn solcher Level ist die Einsparung von Speichermedien bei gleichzeitiger Verlängerung der Backup-Historie. Möchten Sie bspw. die Daten über den Zeitraum dreier Monate aufbewahren, so benötigen Sie bei Realisierung mittels zweier Level ca. 92 Bänder (1 Band für das volle Backup und für jeden Tag ein weiteres). Ein anderes Vorgehen wäre ein anfängliches volles Backup (Level 0, 1 Band), jeden Monat ein Backup Level 1 (2 Bänder, der 3. Monat wird vom kommenden vollen Backup erfasst), jede Woche ein Backup Level 2 (4 Bänder) und schließlich ein viertes Level zur Speicherung der täglichen Daten (6 Bänder). Mit 13 Bänder können Sie also jederzeit den Datenbestand auf den Stand des letzten Tages bringen.
Die Verwendung von dump
| Aufruf: dump [ OPTIONEN ] [ DATEISYSTEM ] |
dump vermag derzeit nur mit dem Datensystem ext2 zusammen zu arbeiten. Ein zu sicherndes Dateisystem kann in der Datei /etc/fstab markiert werden, so dass bei einem Aufruf von dump über den gesamten Verzeichnisbaum nur diese Dateisysteme berücksichtigt werden.
dump versucht in der Voreinstellung das Gerät »/dev/st0« zu öffnen. Existiert das Device nicht, fordert das Kommando zur Eingabe eines anderen Ausgabegerätes auf. Mit der Option -f Datei kann die Sicherung in eine beliebige Datei umgelenkt werden.
Dem Kommando ist natürlich mitzuteilen, was zu sichern ist. Hier kann entweder ein Verzeichnis oder das Device angegeben werden. Des Weiteren muss das Backup-Level (0-9) benannt werden. dump selbst ist in der Lage, die Zeiten der letzten Sicherung eines Levels zu notieren und anhand derer zu entscheiden, ob ein erneutes Backup dieses Levels überhaupt notwendig ist. Hierzu schreibt das Kommando, wird es mit der Option -u aufgerufen, die Zeiten in die Datei /etc/dumpdates. Existiert keine Datei, sollte zuvor eine leere von Hand erzeugt werden.
Volles Backup
Um nun ein volles Backup des Verzeichnisses »/etc/rc.d« auf Diskette zu sichern, ist Folgendes einzugeben:
|
root@sonne> dump -0 -u -f /dev/fd0 /etc/rc.d/ DUMP: Date of this level 0 dump: Tue Aug 15 09:38:13 2000 DUMP: Date of last level 0 dump: the epoch DUMP: Dumping /dev/hda5 (/) to /dev/fd0 DUMP: Label: none DUMP: mapping (Pass I) [regular files] DUMP: mapping (Pass II) [directories] DUMP: estimated 652 tape blocks on 0.02 tape(s). DUMP: Volume 1 started at: Tue Aug 15 09:38:13 2000 DUMP: dumping (Pass III) [directories] DUMP: dumping (Pass IV) [regular files] DUMP: DUMP: 725 tape blocks on 1 volumes(s) DUMP: finished in less than a second DUMP: Volume 1 completed at: Tue Aug 15 09:38:13 2000 DUMP: level 0 dump on Tue Aug 15 09:38:13 2000 DUMP: DUMP: Date of this level 0 dump: Tue Aug 15 09:38:13 2000 DUMP: DUMP: Date this dump completed: Tue Aug 15 09:38:13 2000 DUMP: DUMP: Average transfer rate: 0 KB/s DUMP: Closing /dev/fd0 DUMP: DUMP IS DONE |
dump fordert selbständig zum Mediumwechsel auf, wenn dessen Speicherkapazität nicht mehr genügt.
dump hat in obigen Beispiel die letzte Sicherung des zugrunde liegenden Dateisystems in der Datei »/etc/dumpdates« vermerkt. Die Informationen sind dort im Klartext enthalten und können somit editiert werden, um z.B. temporär eine andere Backupstrategie zu wählen. Mit der Option -W zeigt dump die gesicherten Dateisysteme mit Datum und letztem Backuplevel an und gibt zusätzlich noch Empfehlungen, welches Dateisystem eine erneute Sicherung vertragen könnte:
|
root@sonne> dump -W Last dump(s) done (Dump '>' file systems): /dev/hda5 ( /) Last dump: Level 1, Date Tue Aug 15 13:38 |
Inkrementelles Backup
Um nun eine Level-2-Archivierung desselben Dateisystems vorzunehmen, gibt der Administrator folgende Zeile ein:
| root@sonne> dump -2 -u -f /dev/fd0 /etc/rc.d/ |
Die eigentliche Aufgabe beim Backup ist es nun, die verschiedenen Level-Sicherungen in sinnvollen Zeiträumen anzuordnen, z.B.
- Level-0-Backup einmal in 3 Monaten
- Level-1-Backup monatlich
- Level-2-Backup wöchentlich
- Level-3-Backup täglich
Es bietet sich an, ein solches Schema per cron-Job automatisch zu realisieren. Die Aufgabe des Administrators reduziert sich damit auf das rechtzeitige Wechseln der Bänder.
Überprüfung des Archives mit restore
Um einen Vergleich der im Archiv vorhandenen mit den installierten Dateien vorzunehmen, dient das Kommando restore in Verbindung mit der Option -C. Wird kein weiteres Argument angegeben, versucht restore das Archiv von /dev/st0 zu lesen. Wir verweisen es deshalb auf eine andere Datei (Option -f Datei):
|
root@sonne> restore -C -f /dev/fd0 Dump date: Tue Aug 15 15:38:38 2000 Dumped from: the epoch Level 0 dump of / on sonne:/dev/hda5 (dir /etc/rc.d) Label: none filesys = / ./lost+found: (inode 11) not found on tape ./usr: (inode 2049) not found on tape ... |
Die angeblich fehlenden Dateien sind auf einen Link im archivierten Verzeichnis zurückzuführen und können ignoriert werden.
Recovery mit restore
Zum Recovery der Daten wird im einfachsten Fall ein Archiv mittels recover und der Option -r zurückgeschrieben. Beachten Sie, falls Sie alle Daten durch ihre Kopie aus den Archiven ersetzen wollen, alle Archive in der Reihenfolge ihrer Aufzeichnung einzuspielen, d.h. Sie spielen zunächst das volle Backup (Level 0) ein, dann alle Backups des Levels 1 usw.
| root@sonne> restore -r -f /dev/fd0 |
Eine Besonderheit von recover ist der interaktive Modus (Option -i), der die Selektion einzelner Dateien aus einem Archiv ermöglicht.
|
root@sonne> restore -i -f /dev/fd0 Verify tape and initialize maps Tape block size is 32 Dump date: Tue Aug 15 15:38:38 2000 Dumped from: the epoch Level 0 dump of / on dev17:/dev/hda5 (dir tmp) Label: none Extract directories from tape Initialize symbol table. restore > help Available commands are: ls [arg] - list directory cd arg - change directory pwd - print current directory add [arg] - add `arg' to list of files to be extracted delete [arg] - delete `arg' from list of files to be extracted extract - extract requested files setmodes - set modes of requested directories quit - immediately exit program what - list dump header information verbose - toggle verbose flag (useful with ``ls'') help or `?' - print this list If no `arg' is supplied, the current directory is used restore > ls .: 2 ./ 2 ../ 6145 tmp/ restore > verbose verbose mode off restore > ls .: tmp/ restore > quit |
Die Kommandos ls, cd und pwd besitzen gleiche Bedeutung wie in der Shell, wobei als Argument für ls nur Dateinamen mit enthaltenen Metazeichen jedoch keine Optionen zulässig sind.
Um nun eine Liste der zu extrahierenden Dateien zu erstellen, werden Dateien mit add hinzugefügt und mittels delete entfernt. In der Ausgabe von ls erscheint eine Markierung vor den in der Liste enthaltenen Dateien.
Mit extract werden schließlich die markierten Dateien aus dem Archiv ins System eingespielt, wobei recover zunächst zur Eingabe der Volumenummer auffordert (also das Band, auf dem sich die Datei befindet). Ein Beispieldialog könnte wie folgt aussehen:
|
restore > add boot* restore > ls boot* *bootsec.lin restore > extract You have not read any tapes yet. Unless you know which volume your file(s) are on you should start with the last volume and work towards the first. Specify next volume #: 1 Mount tape volume 1 Enter ``none'' if there are no more tapes otherwise enter tape name (default: /dev/fd0) resync restore, skipped 64 blocks set owner/mode for '.'? [yn] n restore > |
| Backup mit Taper |
|
Von den vorgestellten Backup-Werkzeugen besitzt Taper die freundlichste Benutzerschnittstelle. Es unterstützt die volle Palette an Backupmedien (Tapes, Festplatte, SCSI, Floppy). Wesentlich ist die zusätzliche Speicherung des Inhatlsverzeichnisses eines Archivs, das die Suche vor allem in großen Datenbeständen enorm beschleunigt.
Start von Taper
Der erste Aufruf erfordert die Angabe des Backup-Mediums. Taper speichert die Angaben, so dass bei folgenden Anwendungen der Kommandoaufruf ohne Argumente genügt:
| # Verwendung einer Diskette root@sonne> taper -T removable -b /dev/fd0 # Verwendung eines Tapes root@sonne> taper -T tape -b /dev/tape # Verwendung einer Partition einer SCSI-Platte root@sonne> taper -T scsi -b /dev/sdb3 # Verwendung einer Datei root@sonne> taper -T file -b /home/backup/my_backup |
Nach dem Start befinden wir uns im Hauptmenü.
Backup mit Taper

Abbildung 2: Taper Startmenü
Backup-Module: Zunächst sind der Titel des Backups und des Volumes anzugeben bzw. die vorgeschlagenen Werte eines vorangegangenen Taperlaufes zu bestätigen. Bei einem existierenden Backuparchiv besteht die Wahl, diesem Daten hinzuzuführen oder das bestehende Archiv zu überschreiben.
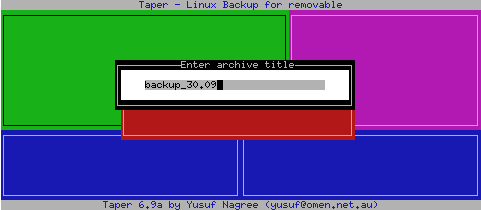
Abbildung 3: Anlegen eines neuen Backuparchivs
Das folgende Fenster ist in vier Bereiche aufgeteilt, zwischen denen mit [Tab] gewechselt werden kann. Links oben befindet sich die Verzeichnisansicht. Mit den Cursortasten kann die Selektion verändert werden. Ein [Enter] auf einem Verzeichniseintrag wechselt in dieses.
Um einen selektierten Eintrag zum Archiv hinzuzufügen, ist [i] zu drücken. Handelt es sich um ein Verzeichnis, werden alle enthaltenen Dateien/Unterverzeichnisse automatisch zum Archiv hinzugefügt. Um einzelne Dateien/Verzeichnisse vom Archiv zu verbannen, sind diese zu selektieren und [u] einzugeben. Bei indirekt zum Backup markierten Einträgen (die durch Auswahl des übergeordneten Verzeichnisses selektiert wurden) ist zum Ausschluss dieser [e] (anstatt [u]) zu einzugeben.
Nähere Informationen zu einer selektierten Datei / einem Verzeichnis erhält man mittels [d].
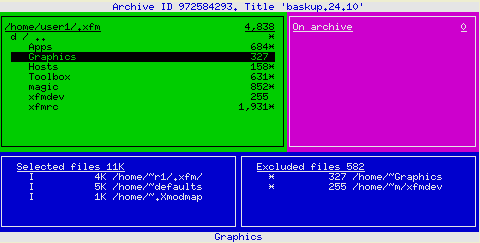
Abbildung 4: Selektion der zu sichernden Daten
Im Fenster rechts oben wird der aktuelle Inhalt des Archivs (Dateien, die zuvor archiviert wurden) angezeigt. Links unten stehen die zum Backup selektierten und rechts unten die vom Backup ausgeschlossenen Dateien. Um solch eine explizit ausgeschlossenen Datei wieder für die Archivierung vorzusehen, ist in das Fenster zu wechseln ([Tab]) und die Datei aus der Auswahl zu entfernen ([u]). Durch Betätigen von [h], [?] oder einer beliebigen, nicht mit einer Funktion versehenen Taste erhält man eine Hilfe zu Taper:
Abbildung 5: Kurzhilfe zu Taper
Das Erzeugen des Backups wird mit Eingabe von [f] begonnen. Ist die Kapazität eines Backupmediums erschöpft, fordert Taper zum Wechsel dessen auf. Nach Abschluss des Vorgangs erscheint ein Statusbericht auf dem Bildschirm:
Abbildung 6: Statusbericht zu einem Backup
Alle getroffenen Änderungen können durch Eingabe von [q] verworfen werden.
Backup-Modi
Der default-Modus von Taper ist ein inkrementelles Backup. D.h. Taper schaut vor dem Archivieren der selektierten Dateien nach, ob diese im verwendeten Archiv bereits existiert. Die dortige Datei wird nur ersetzt, falls sie älteren Datums ist, als der selektierte Eintrag. Ebenso werden Dateien, die 0 Bytes enthalten, ignoriert.
Beim vollen Backup hingegen, wird eine Datei prinzipiell ersetzt, unabhängig davon, ob die Version im Archiv ggf. gleichen oder gar neuerem Datums ist oder ob ihr Inhalt leer ist.
Das voreingestellte Backup-Verhalten kann entweder per Kommandozeilenoption
(inkrementelles Backup mittels --incremental-on (+u); volles Backup mittels
--incremental-off (-u)) oder in den Preferences (Change preferences ![]() Backup preferences 2) eingestellt
werden.
Backup preferences 2) eingestellt
werden.
|
# Start mit erzwungenem vollen Backup root@sonne> taper -T removable -b /dev/fd0 --incremental-off |
Die Dateien lassen sich ebenso gepackt im Archiv ablegen. Taper kennt hierzu
drei Typen von Kompressionen. Typ 1 verwendet das Unix-Kommando gzip (wer
Taper aus dem Quellen selbst übersetzt, kann in »defaults.h« auch ein
anderes Kompressionsprogramm eintragen). Typ 2 ist ein Taper-eigenes
compress-ähnliches Verfahren und Typ 3 ist »gzip« nachempfunden.
Die internen Verfahren arbeiten schneller, liefern aber i.A. schlechtere Packraten. Der
Typ der Komprimierung kann wiederum in den Preferences eingestellt (Change preferences
![]() Backup preferences 1)
oder per Kommandozeile (--compress-typ Typnummer bzw. -c
Typnummer) mitgegeben werden.
Backup preferences 1)
oder per Kommandozeile (--compress-typ Typnummer bzw. -c
Typnummer) mitgegeben werden.
|
# Archivierung ohne Komprimierung root@sonne> taper -T removable -b /dev/fd0 --compress-type 0 |
Restore mit Taper
Im Hauptmenü ist der Eintrag Restore Module zu wählen.
Taper präsentiert eine Liste aller Archive. Das zu rekonstruierende ist zu selektieren und die Wahl mit [Enter] zu bestätigen. Taper fragt nun nach dem Verzeichnis, in das die Daten aus dem Backup eingespielt werden sollen. Ist das Ziel dasselbe Verzeichnis, aus dem die Daten des Backups gewonnen wurden, kann auf die Eingabe verzichtet werden.
Das Restore-Fenster des Programmes ist wiederum in 4 Bereiche unterteilt. Links oben sind alle Dateien aus dem Archiv dargestellt. Rechts oben wird das komplette Archiv dargestellt, also einschließlich der vom Backup ausgeschlossenen Daten (in runden Klammern). Links unten stehen alle zur Wiederherstellung vorgesehenen Dateien; das rechte untere Fenster bleibt leer.

Abbildung 7: Restore mit Taper
Die Auswahl der Dateien erfolgt analog zum Backup-Modul: Mit [i] wählen Sie eine Datei/Verzeichnis aus (ein Verzeichnis schließt wiederum die enthaltenen Dateien/Verzeichnisse ein); ein [u] verwirft einen zuvor selektierten Eintrag. Mit [f] wird die Wiederherstellung begonnen bzw. mittels [q] verworfen.
| Low Level Backup mit dd |
|
Was tun, wenn das Dateisystem zerstört ist, ein aktuelles Backup aber nicht zur Verfügung steht? Bevor die Flinte ist Korn geworfen wird, kann ein Reparaturversuch des Dateisystems nicht schaden. Doch Vorsicht! Wir bewegen uns auf einem sehr unsicherem Terrain, eine unbeholfene Aktion und all die Daten sind unwiderruflich pfutsch...
Da sollte man sich doch besser zuvor ein Backup vom zerstörten System erstellen, um im Falle eines Falles weitere Versuche unternehmen zu können. Aber welches der Backup-Kommandos ist schon in der Lage, zerstörte Dateien aufzuzeichen? Keines, hier kommt dd zum Einsatz, das einfach ab einem bestimmten Startpunkt eine bestimmte Menge »roher« Daten liest und diese 1:1 in eine Zieldatei oder auf ein Zielgerät überträgt. Diese Eigenschaft erlaubt es auch, Dateien beliebiger Dateisysteme zu sichern, selbst wenn Linux diese gar nicht lesen kann...
| Aufruf: dd if=QUELLE of=ZIEL [ OPTIONEN ] |
QUELLE und ZIEL können hierbei sowohl ein Device als auch eine Datei sein. Werden keine weiteren Optionen angegeben, so werden Daten im Umfang von QUELLE kopiert. Handelt es sich bei QUELLE um eine Partition, wird deren gesamter Inhalt kopiert:
| root@sonne> dd if=/dev/hda of=/dev/hdc |
Im Beispiel wird die gesamte erste IDE-Festplatte (/dev/hda) des Systems auf die dritte (/dev/hdc) kopiert. Es sollte jedem bewusst sein, dass der alte Inhalt der dritten Festplatte damit überschrieben wird. Auch sollte diese über die gleiche Kapazität wie die erste Platte verfügen (sonst muss man sich die Anzahl der kopierten Bytes merken). Um die Daten später zurückzuspielen, vertauscht man die Angaben von QUELLE und ZIEL.
Ist das Ziel einer Kopieraktion eine Datei, könnte bei Kernel-Versionen <2.4 die Beschränkung der Dateigröße von 2 GB unser Vorhaben zunichte machen, in einem solchen Fall muss die QUELLE auf mehrere Zieldateien aufgeteilt werden. Hierzu benötigt dd mehrere Optionen. Mit bs=BYTES muss die Anzahl Bytes, die in einem Schritt zu lesen oder schreiben sind, angegeben werden. Wieviele Schritte getätigt werden sollen, legt die Option count=ANZAHL fest. Um bspw. den Masterbootsektor (Mbr) der ersten Festplatte in eine Datei zu schreiben, könnte man folgenden Aufruf verwenden:
| root@sonne> dd if=/dev/hda of=/tmp/mbr.save bs=512 count=1 |
Um jetzt den Superblock (1 k groß) der ersten Partition zu sichern, müssen sowohl Mbr als auch der 512 Bytes lange Bootsektor (also zwei Blöcke) übersprungen werden. Hierzu verwendet man die Option skip=ANZAHL.
| root@sonne> dd if=/dev/hda of=/dev/superblock.save bs=512 count=2 skip=2 |
Das Beispiel demonstriert zwei Sachen: Zum einen, wie ein Abbild auf mehrere Dateien verteilt werden kann und zum anderen, dass die Sache verdammt kompliziert ist. Deswegen wird man dd niemals als Werkzeug für ein regelmäßiges Backup einsetzen, sondern nur in außergewöhnlichen Situationen, wie eingangs beschrieben.
| Amanda |

|
AMANDA (Advanced Maryland Automatic Network Disk Archiver) ist ein auf den Kommandos dump bzw. tar basierendes Backup-System, das die Datensicherung in einem Netzwerk unterstützt. Hierzu wird ein Rechner als Backup-Server eingerichtet, der neben verschiedenen Unix-Clients über den Samba-Service auch die Daten eines Windows-Rechner zu verwalten vermag.
Installation
Die Aktualität der Programmversionen sollte bei jeder modernen Distribution gewährleistet sein. Als Programme müssen installiert sein:
Bei den meisten Distributionen wird man um die Erzeugung der Programme aus den Quelltexten nicht umhin kommen, deshalb soll das Vorgehen hier kurz skizziert werden (im Basisverzeichnis der Quellen finden Sie die Dateien README und INSTALL mit weitergehenden Informationen).
Im Quellverzeichnis befindet sich das Skript configure, das die Steuerdateien für den folgenden Kompilierungsvorgang erzeugt. Einige Optionen für configure sind zwingend erforderlich:
--with-user=Amanda_Benutzer
--with-group=Amanda_Gruppe
--prefix=Verzeichnis
Unterhalb des Basisverzeichnisses für die Amandainstallation werden die Server-Programme in ein Verzeichnis »sbin«, die Client-Programme unter »libexec«, die dynamischen Bibliotheken unter »lib« usw. eingespielt. Jeder dieser voreingestellten Pfade lässt sich über eine Option separat modifizieren. Rufen Sie configure --help auf, um eine vollständige Liste der Optionen zu erhalten.
Im Zusammenhang mit durch Firewalls geschützten Systemen kann die Konfigurationsoption --portrange=TCP-Port1[,TCP-Port2...] erforderlich werden, um den Datentransfer auf die genannten TCP-Ports zu beschränken. Eine Firewall darf aber niemals den UDP-Port 10080 sperren, der dem Server zu Anfragen an die Clients dient.
Der nachfolgende Aufruf sollte für zahlreiche Fälle genügen:
| root@sonne> ./configure --prefix=/usr
\ --libexecdir=/usr/lib/amanda \ --sysconfdir=/etc \ --localstatedir=/var/lib \ --with-user=amanda --with-group=disk |
Der Übersetzungsvorgang und die anschließende Installation werden durch zwei make-Aufrufe eingeleitet:
| root@sonne> make; make install |
Anmerkung: Die nachfolgende Beschreibung geht von obigen Angaben aus, d.h. für alle nicht genannten configure-Optionen gelten die Default-Einstellungen. Dies gilt insbesondere für den Namen der verwendeten Konfiguration (Voreinstellung »DailySet1«; überschreibbar durch die Option --with-config=...), der serverseitig als Verzeichnisname dient.
Der Backup-Server
Zunächst sollten Sie die Verzeichnisse anlegen, die der Server nachfolgend für Status- und temporäre Dateien verwendet. Dies sind im Einzelnen
| root@sonne> mkdir -p
/etc/amanda/DailySet1 root@sonne> mkdir -p /var/amanda/DailySet1 root@sonne> mkdir -p /dump/amanda root@sonne> mkdir -p /var/lib/amanda/gnutar-lists root@sonne> chown -R amanda /var/lib/amanda |
Die Namen der beiden ersten Verzeichnisse korrespondieren mit der Bezeichnung der Konfiguration. »DailySet1« ist die Voreinstellung, falls Sie bei der Kompilierung nichts anderes angegeben haben. Unter /etc landen die Setup-Daten; in /var werden Protokolldateien und Datenbanken abgelegt.
/dump/amanda dient als Zwischenlager. Hier sammelt der Server zunächst die zu archivierenden Daten. Erst wenn sie komplett sind, schreibt er sie aufs Band.
Informationen zur Aktualität der Archive hält der Server in einer Datei /etc/amandates, die noch erzeugt werden sollte:
| root@sonne> touch /etc/amandates |
Ein Backup macht erst wirklich Sinn, wenn ein solches regelmäßig vorgenommen wird. So ist ein Eintrag in den Terminkalender dringend zu empfehlen:
| root@sonne> su - amanda amanda@sonne> crontab -e 0 16 * * 1-5 /usr/sbin/amcheck -m DailySet1 45 0 * * 2-6 /usr/sbin/amdump DailySet1 |
Da es sich bei Amanda um einen Netzwerkdienst handelt, werden einige Einträge in Konfigurationsdateien notwendig. Tragen Sie die folgenden Zeilen in die /etc/services ein:
| root@sonne> grep amanda
/etc/services amanda 10080/udp amandaidx 10082/tcp amidxtape 10083/tcp |
Beachten Sie, dass der UDP-Port zwingend 10080 sein muss. Die TCP-Ports können ggf. angepasst werden.
amandaidx und amidxtape sind Dienste, die den Zugriff auf die Kataloge und das Backup-Bandlaufwerk ermöglichen. amanda ist der Backup-Client. Da sicher auch auf dem Server eine Datensicherung erwünscht ist, sollte dieser Eintrag nicht fehlen. Damit sie bei Bedarf aktiviert werden, sind Einträge in der Datei /etc/inetd.conf (bei Verwendung von inetd) oder in /etc/xinetd.conf (xinetd) erforderlich:
| root@sonne> grep -i amanda
/etc/inetd.conf # Amanda Backup-Client-Service amanda dgram udp wait amanda /usr/lib/amanda/amandad amandad # Amanda Katalog-Service amandaidx stream tcp nowait amanda /usr/lib/amanda/amindexd amindexd # Amanda Tape-Service amidxtape stream tcp nowait amanda /usr/lib/amanda/amidxtaped amidxtaped |
Der Eintrag der fünften Spalte entspricht dabei dem Namen, der mittels »configure --with-user=...« vereinbart wurde. Auch müssten Sie eventuell die Pfade der Programme (Spalte 6) korrigieren, falls Sie bei der Konfiguration andere Einstellungen vorgenommen haben.
Im folgenden Schritt muss die Konfigurationsdatei des Servers angelegt werden. Die den Quellen beiliegende Beispieldatei kann als Ausgangspunkt dienen:
| root@sonne> cp
$AMANDA_SRC_DIR/examples/amanda.conf /etc/amanda/DailySet1 |
Editieren Sie die Datei DailySet1 und passen folgende Einträge an Ihre Gegebenheiten an:
org
mailto
dumpuser
dumpcycle
runspercycle
tapecycle
runtapes
tapedev
tapetype
netusage
labelstr
Der entsprechende Auszug der Konfigurationsdatei könnte so ausschauen:
| root@sonne> cat
/etc/amanda/DailySet1/amanda.conf # # amanda.conf - Eine minimale Konfiguration # org "DailySet1" mailto "amanda" dumpuser "amanda" netusage 600 Kbps dumpcycle 4 weeks runtapes 1 runspercycle 20 tapecycle 25 tapes tapedev "/dev/nst0" tapetype HP-DDS3 labelstr "^DailySet1-[0-9][0-9]*$" ... |
Nachfolgend sollten Sie ein erstes Band für die Verwendung mit Amanda vorbereiten:
| root@sonne> su - amanda amanda@sonne> amlabel DailySet1 DailySet1-01 rewinding, reading label, not an amanda tape rewinding, writing label DailySet1-01, done. |
Entsprechend des Eintrags tapecycle in /etc/amanda/DailySet1/amanda.conf müssen Sie obigen Schritt für die weiteren Bänder wiederholen. Erhöhen Sie einzig die Nummerierung »01« fortlaufend.
Die Backup-Clients
Für jeden Client, der auf einem vom Server abweichenden Rechner installiert wird, müssen Sie zunächst die Einträge in /etc/services und /etc/inetd.conf vornehmen. Gehen Sie wie beim Server vor mit der Ausnahme, dass in den Dateien einzig die mit »amanda« beginnenden Zeilen aufzunehmen sind.
Legen Sie auf den Clients den Benutzer amanda und die Gruppe disk an (bzw. die Namen, die Sie bei der Konfiguration gewählt haben). Der Server muss sich nun ohne Angabe eines Passworts auf dem Client einloggen dürfen. Um dies zu konfigurieren, können Sie entweder im Heimatverzeichnis des Benutzers eine Datei .rhosts (Voreinstellung) oder, falls Sie »configure --amandahosts« wählten, .amandahosts anlegen:
| amanda@client> cat .rhosts sonne.galaxis.de amanda sonne.galaxis.de root sonne.galaxis.de |
Beide Dateien dürfen nur den Eigentümer zum Lesen und Schreiben berechtigen!
Das wär's schon auf Seiten des Clients. Nun muss nur noch auf dem Server eine Datei mit der Beschreibung der zu sichernden Verzeichisse oder Partitionen angelegt werden.
Ein Eintrag der Datei disklist besitzt immer folgende Gestalt:
| <Clientname> <Verzeichnis> <Backuptyp> |
Als Clientname wird der volle Rechnername empfohlen. Verzeichnis kann eben ein solches sein oder aber der Name eines Devices (/dev/hda...).
Mit dem Backuptyp soll an dieser Stelle nur auf Standardtypen eingegangen werden. Der Eintrag selbst beschreibt, mit welchen Mitteln das Backup erzeugt werden soll. In der Datei amanda.conf lassen sich eigene Typen deklarieren, die mehrere Standardtypen zusammenfassen (ein Beispiel folgt im Anschluss). Die wichtigsten Typen sind:
comprate Wert1 [, Wert2]
compress Modus
Als Modi sind möglich:
- none keine Komprimierung
- client best Komprimierung findet auf dem Client statt bei Verwendung des besten Algorithmus
- client fast Komprimierung findet auf dem Client statt bei Verwendung des schnellsten Algorithmus
- server best Komprimierung findet auf dem Server statt bei Verwendung des besten Algorithmus
- server fast Komprimierung findet auf dem Server statt bei Verwendung des schnellsten Algorithmus
Ohne explizite Modusangabe gilt "client fast".
exclude
holdingdisk [yes|no]
index
program [DUMP|GNUTAR]
record [yes|no]
Ein benutzerdefinierter Backuptyp wird in der Datei amanda.conf wie folgt vereinbart:
| ... define dumptype >root-tar { global program "GNUTAR" comment "root partitions dumped with tar" compress none index exclude list "/usr/lib/amanda/exclude.gtar" priority low } ... |
Eine einfache Datei disklist sieht somit wie folgt aus:
| amanda@sonne> cat
/etc/amanda/DailySet1/disklist sonne.galaxis.de /home root-tar |
Erster Test
Ein erster Test soll den korrekten Verlauf der bisherigen Installation beweisen. Als Root wird zunächst der Server begutachtet:
| root@sonne> amcheck DailySet1 Amanda Tape Server Host Check ----------------------------- /dumps/amanda: 2531432 KB disk space available, that's plenty. NOTE: skipping tape-writable test. Tape DailySet1-01 label ok. Server check took 0.052 seconds. Amanda Backup Client Hosts Check -------------------------------- Client check: 1 host checked in 0.108 seconds, 0 problems found. (brought to you by Amanda 2.4.1p1) |
"0 problems found" ist keine schlechte Antwort...
Vorläufig stoßen wir ein Backup von Hand an. Später, wenn die Installation perfekt ist, sollte ein Cronjob die Aufgabe erledigen:
| root@sonne> su - amanda amanda@sonne> amdump DailySet1 |
Eine Mail sollte dem festgelegten Report-Empfänger bald ins Haus stehen. Mit etwas Glück sieht sie ähnlich der folgenden aus (stark gekürzt):
| From amanda@sonne.galaxis.de Sun Jan 21 02:49:35 2001 ... These dumps were to tape DailySet1-01. Tonight's dumps should go onto 1 tape: a new tape. FAILURE AND StrANGE DUMP SUMMARY: sonne /home lev 0 StrANGE STATISTICS: Total Full Daily -------- -------- -------- Dump Time (hrs:min) 0:42 0:41 0:00 (0:02 start, 0:00 idle) Output Size (meg) 718.2 718.2 0.0 Avg Compressed Size (%) 28.9 28.9 -- Tape Used (%) 6.0 6.0 0.0 Filesystems Dumped 1 1 0 Avg Dump Rate (k/s) 300.5 300.5 -- Avg Tp Write Rate (k/s) 300.4 300.4 -- ... NOTES: planner: Adding new disk sonne:/u01. taper: tape DailySet1-01 kb 735456 fm 1 [OK] DUMP SUMMARY: DUMPER STATS TAPER STATS HOSTNAME DISK L ORIG-KB OUT-KB COMP% MMM:SS KB/s MMM:SS KB/s -------------------------- -------------------------------------- -------------- sonne /u01 0 2542390 735424 28.9 40:48 300.5 40:48 300.4 (brought to you by Amanda version 2.4.1p1) |
Der nächste Schritt provoziert einen Fehler, da das Band die Datenmenge nicht aufnehmen kann:
| amanda@sonne> /usr/sbin/amcheck -m DailySet1 |
In der Mail äußert sich der Fehler wie folgt (Ausschnitt):
| Amanda Tape Server Host Check ----------------------------- /dumps/amanda: 2523880 KB disk space available, that's plenty. ERROR: cannot overwrite active tape DailySet1-01. (expecting a new tape) NOTE: skipping tape-writable test. Server check took 33.920 seconds. |
Es genügt nun, ein neues Band für die Nutzung durch Amanda vorzubereiten. Amanda wird später an der Stelle fortfahren, an der das letzte Schreiben wegen des Bandendes stoppte (ein neues Band wurde zuvor eingelegt):
| amanda@sonne> /usr/sbin/amlabel
DailySet1 DailySet1-02 rewinding, reading label, not an amanda tape rewinding, writing label DailySet1-02, done. amanda@sonne> /usr/sbin/amcheck -m DailySet1 |
Die nächste uns erreichende Mail sollte wieder einen Erfolg verkünden.
Weitere wichtige Kommandos für Amanda
Für die tägliche Arbeit bringt das Amanda-Paket eine Reihe von Hilfsprogrammen mit, deren Zweck knapp erläutert sein soll:
amcheckdb <Konfiguration>
amoverview [-config <Konfiguration>]
amcleanup <Konfiguration>
amverify <Konfiguration><Slot>
amtape <Konfiguration> Kommando
amadmin <Konfiguration> Kommando
amrmtape <Konfiguration> <Label>
amstatus <Konfiguration>
Restauration - oder der Fall der Fälle
Für das Wiederherstellen von Daten mit Amanda gibt es drei prinzipielle Wege. Welcher beschritten werden muss, hängt von den in der Praxis vorkommenden Eventualitäten ab:
- Dateien oder Verzeichnisse sind "plötzlich" verschwunden bzw. beschädigt und müssen wiederhergestellt werden
- Eine Festplatte musste ersetzt werden, weil sie nach dem letzten Power-off nicht wieder angelaufen ist. Sie sollte nun komplett in den inhaltlichen Zustand der alten Platte versetzt werden
- Die Platte mit dem kompletten System - und vielleicht gar die komplette Amanda-Installation - haben sich verabschiedet und sollen nun von einem Not-System wieder restauriert werden. Dies geschieht dann i.A. ohne Amanda
Wiederherstellen von Daten mit Amanda
Zum Wiederherstellen einzelner Dateien, Verzeichnisse oder kompletter Festplatten dient das Kommando amrestore:
| amrestore [ -r | -c ] [ -p ] [ -h ] tapedevice [ hostname [ diskname [ datestamp [ hostname [ diskname [ datestamp ... ]]]]]] |
Der Einsatz der Optionen wirkt sich dabei hierarchisch von oben aus, d.h. wenn der Plattenname (»diskname«) nicht angegeben wird, werden alle Backups für den vorangestellten Rechner (»hostname«) zurück gespielt. Ist kein Zeitstempel (»datestamp«) gesetzt, werden alles Backups für das zugehörige Rechner-Platten-Paar zurück gespielt. Wurde keiner der Parameter angegeben, finden alle zur Verfügung stehenden Backups bei der Wiederherstellung Verwendung.
Während des Zurückholens der Daten vom Band mit amrecover werden diese nicht direkt auf die Datenträger an ihre ursprünglichen Plätze (die sie zum Zeitpunkt des Backups inne hatten) zurück gespielt. Stattdessen werden einzig die Archive vom Band zurück gelesen, welche mittels amflush auf dieses Band geschrieben wurden. Dabei werden Dateien erzeugt, deren Namen folgender Konvention entsprechen:
| # hostname.diskname.datestamp.dumplevel sonne._u01.20010204.3 |
Eine alternative Realisierung gestattet die Verwendung der Option -p (von "Pipe"), wodurch die Inhalte der Archive unmittelbar an ihre ursprünglichen Positionen entpackt werden.
Die Option -c (»compression«) legt die Archivdateien komprimiert auf der Festplatte ab, unabhängig davon, ob sie auf dem Band komprimiert vorliegen oder nicht.
Mittels der Option -r (»raw«) interpretiert amrestore die Daten auf dem Band als 1:1-Kopien der gesicherten Daten und schreibt sie unverändert zurück.
-h bringt einzig die Header der Archive auf dem Band zum Vorschein. So kann bspw. die Archivierungsmethode ermittelt werden, mit der ein Archiv angelegt wurde.
Ein Beispiel:
Aus einem unerfindlichen Grund ist uns der Überblick über die Inhalte unserer Backup-Bänder abhanden gekommen. Leider zwingt ein Datenfehler zur Restauration einiger Dateien, doch wo liegen sie?
Finden sich in unseren grauen Zellen noch diffusive Ahnungen ob des richtigen Backups, sollten wir das vermutete Band einlegen und amrestore mit möglichst detaillierten Parametern zu Rechnername, Plattenname und Zeitstempel ausstatten. Ist der Schleier der Erinnerung gar zu undurchsichtig, hilft ein Versuch mit bloßer Angabe des Rechnernamens:
| amanda@sonne> amrestore /dev/nst0 sonne |
Nach einiger Zeit der Suche auf dem Band sollte eine Dateiliste erscheinen:
| amanda@sonne> ls /u01/recover . sonne._u01.20010204.3 sonne._u01.20010210.3 .. sonne._u01.20010205.3 sonne._u01.20010211.3 sonne._u01.20010131.3 sonne._u01.20010206.3 sonne._u01.20010203.3 sonne._u01.20010208.3 |
Welches Format sich hinter den Dateien verbirgt, offenbart ein Aufruf des Kommandos file:
| amanda@sonne> file /u01/recover/* sonne._u01.20010131.3: GNU tar archive sonne._u01.20010203.3: GNU tar archive sonne._u01.20010204.3: GNU tar archive sonne._u01.20010205.3: GNU tar archive sonne._u01.20010206.3: GNU tar archive sonne._u01.20010208.3: GNU tar archive sonne._u01.20010210.3: GNU tar archive sonne._u01.20010211.3: GNU tar archive |
Da es sich im Beispiel um tar-Archive handelt, hilft tar, um in den Archiven nach den zu restaurierenden Dateien zu suchen:
| amanda@sonne> tar -tvf - /u01/recover/sonne._u01.20010131.3 ... |
Als Hilfe zum Wiederherstellen von Dateien und Verzeichnissen empfiehlt sich das Kommando amrecover. Dieses Programm bietet eine Benutzerschnittstelle, die auf Indexdaten zugreift, welche für Dumptypen mit eingeschalteter Index-Option beim Backup erstellt wurden (Option index bei define dumptype... aus /etc/amanda.conf). Die Schnittstelle erlaubt eine bequeme Navigation durch die verschiedenen Versionen von gesicherten Dateien und Verzeichnissen. Zu restauriende Einträge lassen sich selektieren und der Vorgang der Wiederherstellung aus dem Programm heraus anstossen.
Wiederherstellen von Daten ohne Amanda
Ein Verlust wichtiger Daten bei gleichzeitiger Zerstörung der Amanda-Installation könnte man als Supergau der Datensicherung betrachten. Was nun?
Ein Blick hinter die Kulissen lohnt sich. Unsere Kulissen sind die Bänder mit den Sicherungsarchiven, die hoffentlich unbeschädigt in Griffweite stehen. Amanda hatte die verwendeten Bänder vorab formatiert und genau dieses Format machen wir uns zu Nutze, um an die begehrten Daten zu gelangen.
Die erste Datei liegt im Klartext vor (plain text) und ist das so genannte Volume Label. Sie enthält die Volume Serial Number (VSN) und den Zeitstempel der Formatierung durch Amanda.
Unmittelbar dem Volume Label folgt eine Liste von Dateien. Bekannt ist nun, dass jede dieser Dateien in Blöcken zu je 32 kByte abgelegt ist, wobei der erste Block (Header) von Amanda gespeicherte Statusinformationen umfasst.
Einem Header folgen unmittelbar die Blöcke mit den Daten der Datei. Daran schließt sich der Header der folgenden Datei an, dem wiederum die Datenblöcke folgen. Eine Restauration ohne amrestore läuft somit nach folgendem Schema ab:
- Rücksetzen des Bandes
- Einlesen der ersten Datei (Volume Label)
- Solange noch Blöcke auf dem Band sind:
-
- Lies den nächsten Block (Header einer Datei)
- Lies alle Blöcke, die zu dieser Datei gehören
- Tue etwas mit den Daten (bspw. ins System einspielen)
Anhand eines Beispiels sollen die einzelnen Schritte begangen werden:
-
Rücksetzen des Bandes:
amanda@sonne> mt rewind -
Auslesen der Datei mit dem Volume Label:
# Spulen an den Anfang der nächsten (also ersten) Datei:
amanda@sonne> mt fsf NN
# Im ersten Block (Amanda-Header) steht, mit welchem Programm das Archiv erzeugt wurde:
amanda@sonne> dd if=/dev/nst0 bs=32k
AMANDA: FILE 20010131 sonne /u01 lev 3 comp .gz program /bin/gtar To restore, position tape at start of file and run: dd if= bs=32k skip=1 | /usr/bin/gzip -dc | bin/gtar -f... -
1+0 records in
1+0 records out
-
Dann die Images:
# Wir nutzen den Aufruf, den Amanda im Header speicherte (siehe oben):
amanda@sonne> dd if= bs=32k skip=1 | /usr/bin/gzip -dc | bin/gtar -fv -
Nach diesem Schema lassen sich fortlaufend die Images vom Band ziehen und ins aktuelle Verzeichnis entpacken.

 Korrekturen, Hinweise?
Korrekturen, Hinweise?