



Programmierung der Bourne Again Shell |
| Wege zum Skript |


|
Hello world!
Wohl jede Einführung in eine Programmiersprache beginnt mit einem besonders einfachen Beispiel. Und die wohl beliebteste Anwendung ist das Erstlingswerk, das ein "Hello world!" auf den Bildschirm zaubert. In der Bash sähe das Ergebnis wie folgt aus:
|
#!/bin/sh echo "Hello world!" |
Speichert man die Zeilen in eine Datei namens »hello« und führt diese zur Ausführung einer Bash zu, so erscheint - welch ein Wunder - die vermutete Antwort:
|
user@sonne> bash hello Hello world! |
Für die Zukunft werden wir ein solches Shellskript gleich mit den Ausführungsrechten versehen, so dass sich der Aufruf verkürzt:
|
user@sonne> chmod +x hello user@sonne> ./hello Hello world! |
Wer sich jetzt fragt, was der »Kommentar« auf der ersten Zeile in unserem Beispiel zu suchen hat, der sei in seiner Ansicht bestätigt, dass jede Zeile, die mit einem Doppelkreuz beginnt, ein Kommentar ist. Außer... dem Kommentarzeichen folgt ein Ausrufezeichen. In dem Fall versucht die Shell, den Inhalt der Datei mit dem in dieser Zeile angegebenen Interpreter auszuführen. In diesem Abschnitt wird es sich bei dem Interpreter durchweg um die Bash handeln. Geben Sie den Interpreter immer mit vollständigem Zugriffspfad an, sonst ernten Sie nur verwirrende Fehlerhinweise:
|
user@sonne> cat hello #!bash echo "Hello world!" user@sonne> ./hello bash: ./hello: Datei oder Verzeichnis nicht gefunden |
Vermögen Sie es, aus der Fehlermitteilung auf den wahren Grund zu schließen (Hinweis: Der Inhalt von $PATH wird hier nicht betrachtet.)?
Vielleicht haben Sie schon bemerkt, dass das Shellskript auch ohne diese erste Zeile brav seinen Dienst verrichtet? Dem sollte auch so sein, denn jede Unix-Shell interpretiert diese einfache »echo«-Ausgabe gleich. Gewöhnen Sie sich dennoch an, die Shell, für die Ihr Skript verfasst wurde, auf diese Art zu spezifizieren. So können Sie das Shellskript auch innerhalb anderer Shells (z.B. csh) aufrufen, die womöglich mit der Syntax ihre Probleme hätten.
Von der Idee zum Skript
Jede Aneinanderreihung von Befehlen, die Sie in eine Datei schreiben, formt ein Shellskript. Der Aufwand lässt sich für wiederkehrende Arbeiten auf diese Art und Weise drastisch verringern und dennoch ist der Nutzen von Skripten oft nicht unmittelbar ersichtlich.
Wer sich intensiv mit Unix beschäftigt, wird vielfach simple Werkzeuge vermissen. Warum hat wohl noch niemand jenes programmiert? Vielleicht ja, weil Unix von Haus aus die Mittel mit sich bringt, dass ein jeder - ein geringes Grundwissen vorausgesetzt - durch geschickte Kombination existenter Programme ein solches Hilfsmittel modellieren könnte.
Im vorangegangenen Abschnitt zur Bash haben Sie alles Notwendige kennen gelernt, um munter drauf los »skripten« zu können. Die Beherrschung der Unix-Werkzeuge grep, sed und awk ist für viele elegante Lösungen erforderlich. Was Ihnen nun vermutlich noch fehlt, ist ein konkreter Plan, wie Sie Ihr Problem elegant und effizient in ein Shellprogramm fassen können.
Was Ihr Problem ist (ich meine das jetzt hinsichtlich der Computerfragen), vermögen wir nicht vorherzusehen, aber wozu die Bash fähig ist - im positiven Sinne - sollen die nachfolgend vorgestellten Lösungen zu (oft) praxisnahen Anwendungen verdeutlichen.
Was die Bash nicht kann
Wozu benötigt man »höhere« Programmiersprachen, wenn die Bash das Problem auch behandeln könnte? Weil das Programm der Bash interpretiert wird und schon allein aus diesem Grund wesentlich langsamer abläuft, als es ein kompiliertes Programm vermag. Aber auch bei komplexeren Problemen erschöpfen sich rasch die Mittel der Bash.
Aufgaben, für die Sie ein Shellskript keinesfalls in Betracht ziehen sollten, sind:
- Zeitkritische Abläufe (tiefe Rekursionen)
- Hardwarenahe Programmierung (geht definitiv nicht)
- Wirklich große Anwendungen
- Erweiterte Dateizugriffe, die über das serielle Lesen und Schreiben der Daten hinaus gehen
- Grafische Oberflächenprogrammierung (nur »Pseudografik« in Verbindung mit dem Kommando »dialog«)
- Zugriff auf Sockets
| Fehlersuche |
|
Reale Skripte sind um Einiges komplexer, als es das einführende "Hello World" vermittelte. Und Fehler bleiben leider nicht aus. Syntaktischen Ungereimtheiten kommt die Bash schnell auf die Schliche. Aber nicht immer sind die Mitteilungen über die Fehlerursache aussagekräftig:
|
user@sonne> cat script_with_an_error #!/bin/sh if ["$1" -eq "" ] then echo "Missing an argument." exit 1 fi user@sonne> ./script_with_an_error foo ./script_with_an_error: [foo: command not found |
Command not found ist nun wirklich keine hilfreiche Mitteilung...
Wie expandiert die Bash eine Anweisung?
In der Testphase erweist sich die Shelloption xtrace als äußerst nützlich, da jede Kommandozeile eines Skripts nach ihrer Expansion ausgegeben und erst anschließend ausgeführt wird. Setzen Sie set -x an den Anfang des obigen Fehlerskripts, so entlarvt sich der Fehler von selbst:
| user@sonne> cat
script_with_an_error #!/bin/sh set -x ... user@sonne> ./script_with_an_error foo + '[foo' -eq '' ']' ./script_with_an_error: [foo: command not found |
Welche Anweisung wurde gerade bearbeitet?
Obige Ausgabe führt bei kürzeren Skripts sofort zur Fehlerquelle; dennoch wäre es wünschenswert, wenn die gerade betrachtete Kommandoanweisung nochmals ausgegeben werden würde. Mit der Shelloption verbose (set -v) entlockt man der Bash etwas konkretere Informationen.
| user@sonne> cat fakultaet.sh #!/bin/sh set -xv # xtrace und verbose aktivieren declare -i zahl=$1 declare -i fakultaet while [ $zahl -gt 1 ]; do fakultaet=$fakultaet*$zahl zahl=$zahl-1 done echo "Fakultät = " $fakultaet |
Erkennen Sie den Fehler im Skript? Ein Lauf offenbart ihn schnell:
| user@sonne> ./fakultaet.sh 5 declare -i zahl=$1 + declare -i zahl=5 declare -i fakultaet + declare -i fakultaet while [ $zahl -gt 1 ]; do fakultaet=$fakultaet*$zahl zahl=$zahl-1 done + '[' 5 -gt 1 ']' + fakultaet=*5 ./schnelltest.sh: *5: syntax error: operand expected (error token is "*5") echo "Fakultät = " $fakultaet + echo 'Fakultät = ' Fakultät = |
Die letzte Anweisung vor dem Fehler betraf die while-Schleife. Der Fehler selbst resultiert aus der Verwendung der nicht initialisierten Variable "$fakultaet". Ändert man die Zeile "declare -i fakultaet" in "declare -i fakultaet=1", liefert das Skript das erwartete Resultat.
Fehler und deren Folgen
Letztes Beispiel weist schon auf ein mögliches Problem hin, das in bestimmten Skripten zu durchaus drastischen Folgen führen kann. Obiges Skript läuft selbst im Fehlerfall weiter. Mitunter wird durch eine fehlgeschlagene Anweisung ein gänzlich anderer Kontrollfluss durchlaufen. Was, wenn nun zum Beispiel Daten einer Dateiliste entfernt werden, wobei die Berechnung der Liste den Fehler verantwortete?
Kritische Skripte - die Änderungen im Dateisystem vornehmen - sollten zunächst ausgiebig getestet und erst bei erwiesener syntaktischer Korrektheit eingesetzt werden. Setzen Sie während der Entstehungsphase eines Skripts die Shelloption noexec (set -n), so wird die Bash die meisten syntaktischen Fallen erkennen, ohne die Anweisungen tatsächlich auszuführen.
Ein fehl geschlagenes einfaches Kommando führt in der Standardeinstellung der Shell ebenso wenig zum Ende eines Skripts. Erst errexit (set -e) stoppt die weitere Bearbeitung. Allerdings nützt die Option nichts, wenn das Kommando innerhalb einer Schleife (while bzw. until) oder als Bestandteil logischer Konstrukte (if, ||, &&) scheitert.
Logische Fehler
Denkfehlern ist wesentlich aufwändiger auf die Schliche zu kommen. Einzig auf nicht-gesetzten Variablen basierende Fallstricke kann die Shelloption nounset (set -u) durchtrennen.
Das Allheilmittel lautet echo. Bauen Sie an allen kritischen Stellen Ihrer Skripte Ausgaben ein und verifizieren Sie die Belegung der Variablen. Werden Ergebnisse in Pipelines verarbeitet, kann das Kommando tee dazu dienen, die Daten der Zwischenschritte zu inspizieren.
Entwickeln Sie die Skripte schrittweise. Testen Sie Funktionen zunächst mit statischen Eingabedaten, bevor Sie sie in komplexeren Anwendungen verwenden. Stellen Sie sicher, dass keine unerlaubten Argumente Ihr Skript auf Abwege bringt.
| Endreinigung |
|
Ein unfreiwilliger Abgang
In manchen Skripten wird es erforderlich, gewisse Systemressourcen zu reservieren. Das einfachste Beispiel ist die Ablage von Daten in temporären Dateien. Vor Beendigung des Skripts wird dieses sicherlich dafür Sorge tragen, den nicht mehr benötigten Datenmüll zu entsorgen.
Was aber, wenn Ihr Skript gar nicht das Ende erreichte? Vielleicht bootet Ihr Administrator soeben mal den Rechner neu und "schießt" Ihr Skript mir nichts dir nichts ab? Oder Sie selbst vereiteln die Vollendung, weil die Dauer der Berechnung nun doch Ihre Geduld strapaziert. Was ist mit den temporären Daten?
Tatsächlich erachten es die wenigsten Skripte für sinnvoll, im Falle des expliziten Abbruchs diesen abzufangen und ein abschließendes Groß-Reine-Machen vorzunehmen.
Erinnern wir uns, dass die asynchrone Interprozesskommunikation unter Unix im Wesentlichen über Signale realisiert wird. Einem Prozess, dessen Ende man bewirken will, wird man zuvorkommend das Terminierungssignal (SIGTERM) oder - im Falle eines Vordergrundprozesses - den Tastaturinterrupt ([Ctrl]-[C], SIGINT) senden. Erst wenn dieser nicht reagiert, sollte per SIGKILL das Ableben erzwungen werden. Tatsächlich wird beim Herunterfahren des Systems zunächst SIGTERM an einen jeden Prozess gesendet und erst anschließend ein SIGKILL.
Ein Programm kann mit Ausnahme von SIGKILL jedes Signal abfangen und die übliche Bedeutung dessen verbiegen. In der Bash werden Signale mit dem eingebauten Kommando trap maskiert.
Fallstudie: Ein simples Backup-Skript
Ob Hardwareausfall oder Bedienfehler... früher oder später wird jeder einmal mit einem unbeabsichtigten Datenverlust konfrontiert. Eine Sicherungskopie wichtiger Daten sollte daher in keiner Schreibtischschublade fehlen. Jedoch verfügt nicht jeder Rechner über Streamer, CD-Brenner oder andere geeignete Backupmedium.
Aber ein Diskettenlaufwerk werden wohl die wenigsten Boliden missen. Nur passen selten alle interessanten Daten auf eine einzige Magnetscheibe, sodass ein so genanntes Multi-Volume-Backup von Nöten wird. Das Kommando tar unterstützt zwar von Haus aus die Verteilung großer Archive auf mehrere Medien, allerdings muss in jenem Fall auf eine Komprimierung des Archivs verzichtet werden.
Nach diesen Vorbetrachtungen notieren wir uns die Fähigkeiten, die unser einfaches Backup-Skript mit sich bringen soll:
- Es soll alle Konfigurationsdateien aus /etc sichern (eine Erweiterung bleibt dem Leser überlassen)
- Die Dateien sollen mit bzip2 gepackt werden
- Ein Aufruf "Scriptname -c" erzeugt das Archiv
- Ein Aufruf "Scriptname -r" spielt die Dateien zurück
Kopfzerbrechen sollte dem geübten Bash-Anwender einzig das Packen bereiten. Die Lösung, die unser Skript verwenden wird, ist das Packen jeder einzelnen Datei, wobei diese zunächst in einem temporären Verzeichnis abgelegt wird. Abschließend wird tar das Archiv anhand dieses Verzeichnisses erzeugen. Die Wiederherstellung der Daten verläuft genau umgekehrt. Das Skript entpackt das Archiv in ein temporäres Verzeichnis und entpackt erst anschließend die Daten an ihren angestammten Ort.
Um endlich den Bezug zur Überschrift des Abschnitts herzustellen, soll unser Skript auch dafür Sorge tragen, dass keine temporären Dateien im Dateisystem verbleiben, falls das Skript abgebrochen werden sollte.
Das Rahmenprogramm
Die Auswertung der Kommandozeilenoption (-r bzw. -c sollen zulässig sein) überlassen wir dem eingebauten Kommando getopts (wird später behandelt). Der Rahmen des Skripts sieht wie folgt aus:
| #!/bin/sh function benutze() { echo "Unbekannte oder fehlende Option!" echo "Anwendung: $0 -c|-r" exit 1 } function archiviere() { !: # noch zu schreiben } function restauriere() { !: # noch zu schreiben } while getopts rc Optionen; do case $Optionen in c) # Aufruf der Archivierungsfunktion archiviere ;; r) # Aufruf der Wiederherstellungsfunktion restauriere ;; *) # Unbekannte Option benutze ;; esac done test "$OPTIND" == "1" && benutze # kein Argument auf der Kommandozeile |
Die Archivierungs-Funktion
Für die Zwischenablage der gepackten Dateien benötigen wir ein Verzeichnis. Um die temporäre Natur dessen zu unterstreichen, wird es in /tmp erzeugt. Als (hoffentlich) eindeutigen Namen wählen wir "etcProzessnummer". Die entsprechende Anweisung in der Funktion lautet somit:
| mkdir /tmp/etc$$ |
Die Suche nach den regulären Dateien wird mittels find realisiert. Das Packen erfolgt in einer Schleife über die einzelnen Dateien. Zunächst wird die Datei - sofern wir Leserechte besitzen - kopiert und anschließend komprimiert:
| for i in `find /etc -type f -maxdepth
1`; do test -r $i || continue cp $i /tmp/etc$$ bzip2 /tmp/etc$$/`basename $i` done |
Die Vorbereitungen sind abgeschlossen, fehlt nur noch das Archivieren auf Diskette (/dev/fd0):
| tar -Mcf /dev/fd0 /tmp/etc$$ |
Mit dem abschließenden Löschen von /tmp/etc$$ nimmt die komplette Funktion folgende Gestalt an:
| function archiviere() { test -e /tmp/etc$$ || mkdir /tmp/etc$$ for i in `find /etc -type f -maxdepth 1`; do test -r $i || continue cp $i /tmp/etc$$ bzip2 /tmp/etc$$/`basename $i` done tar -Mcf /dev/fd0 /tmp/etc$$ rm -r /tmp/etc$$ } |
Die Wiederherstellungs-Funktion
Wir überlassen die Realisierung dem Leser. Vergessen Sie nicht das abschließende Entfernen des Verzeichnisses mit den komprimierten Dateien!
Behandlung von Signalen
Um unser Skript vor vorschnellem Abbruch durch Signale zu schützen, müssen wir diese abfangen und behandeln. Unsere Reaktion wird sein, dass wir rasch alle temporären Dateien/Verzeichnisse löschen und anschließend das Skript verlassen. Bei den Signalen beschränken wir uns auf SIGINT (Nummer 2; Tastaturinterrupt) und SIGTERM (15). Ein trap-Aufruf zu Beginn unseres Skripts ist alles, was wir tun müssen:
| #!/bin/sh trap 'test -e /tmp/etc$$ && rm -r /tmp/etc$$; exit 0' 2 15 |
Wann immer eines der beiden Signale auf den Prozess einherfällt, wird trap das temporäre Verzeichnis samt Inhalt entfernen - falls es existiert - und das Skript beenden.
Sie können trap ebenso verwenden, um bestimmte Signal zu ignorieren. Wählen Sie hierfür eine der beiden Syntaxvarianten:
| trap "" 2 3 15 19 # Alternative Angabe: trap : 2 3 15 19 |
Um in einem Skript die Behandlung von Signalen wieder zuzulassen, ist ein Aufruf von trap ohne Argumente erforderlich.
| Korrekte Eingaben |
|
Eine Binsenweisheit der Programmierer besagt, dass die ergiebigste Fehlerquelle vor dem Bildschirm sitzt. Benutzer zeigen oft Verhaltensmuster, die jeglicher Logik entbehren. Ein mit Nutzereingaben arbeitendes Programm sollte deshalb fehlerbehaftete Eingaben erkennen und darauf vernünftig reagieren.
Prüfung der Eingabe
Von einer Eingabe erwarten wir i.A., dass sie von einem bestimmten Typ ist. Wir möchten wissen, ob die eingegebene Zeichenkette ein Datum im geforderten Format ist, ob sie eine Zahl ist, ob eine Zahl im geforderten Bereich liegt...
Sicher stellen lässt sich dies jedoch nur durch eine Prüfung im Anschluss an die Eingabe. Für zwei verbreitete Fälle möchten wir Lösungen oder Lösungsansätze präsentieren:
Ganze Zahl
Eine gültige ganze Zahl darf mit oder ohne Vorzeichen angegeben werden. Führende oder nachfolgende Leerzeichen sollten ebenso akzeptiert werden, wie Zwischenräume zwischen Vorzeichen und Zahl. Folgende Angaben stellen demnach korrekte Eingaben dar (zur Veranschaulichung von Leerzeichen werden die Zahlen in Anführungsstriche eingeschlossen):
| "1928888" "-12" "+ 332 " " - 0" |
Lösung 1: Indem eine solche Zahl einer mit "declare -i" typisierten Variable zugewiesen wird, lässt sich anhand des Inhalts der Variablen prüfen, ob eine korrekte Eingabe vorliegt:
| user@sonne> declare -i var=" - 1234" user@sonne> echo $var -1234 user@sonne> var=" + 1bla" bash: + 1bla: value too great for base (error token is "1bla") user@sonne> var=" + bla1" user@sonne> echo $var 0 |
Aus den Beispielen sind zwei Probleme ersichtlich:
- Die Zuweisung eines fehlerhaften Wertes bewirkt eine Fehlermeldung der Shell, wenn der Wert mit einer (vorzeichenbehafteten) Ziffer beginnt.
- Die Zuweisung eines fehlerhaften Wertes bewirkt keine Fehlermeldung, wenn der Wert mit keiner Ziffer beginnt.
Die Konsequenz aus (1) ist, dass wir in einem Shellskript Fehlerausgaben abfangen sollten. Ob ein Fehler auftrat, lässt sich anhand des Rückgabewertes verifizieren:
| # Die Meldung kommt von der Shell! Deshalb Wertzuweisung in einer Subshell: user@sonne> (var=" + 1bla") 2>/dev/null || echo "Fehler in Zuweisung" |
Die Ursache für (2) ist, dass die Bash Zeichenketten bei Bedarf intern zu "0" konvertiert. Da "0" gleichzeitig ein akzeptierter Eingabewert ist, sollte man sich zusätzlich versichern, dass tatsächlich "0" in der Eingabe stand (Zeichenkettenvergleich)!
Lösung 2: Mit Hilfe der Parametersubstitution scannen wir die Eingabe:
|
user@sonne> Eingabe="+ 1992" user@sonne> var=${Eingabe##*[^0-9,' ',-]*} user@sonne> echo $var 1992 |
Viele Leser werden den obigen Ausdruck wohl kaum interpretieren können, außerdem "übersieht" er eine Art Eingabefehler (Finden Sie ihn selbst heraus!). Analog zur "Lösung 1" muss auch hier eine zweite Überprüfung herhalten, um sämtliche Fälle abzudecken.
Lösung 3: Wir greifen auf das Kommando (e)grep zurück und suchen nach "einem Muster" (alternativ lässt sich auch der Stream Editor verwenden):
|
user@sonne> Eingabe="+ 1992 12" user@sonne> echo $Eingabe | egrep -q '^[[:space:]]*[+-]?[[:space:]]*[[:digit:]]+[[:space:]]*$' || echo "Fehler" Fehler |
Zugegeben, die Definition des Suchmusters ist nicht leicht zu verdauen. Dafür deckt sie tatsächlich alle Eventualitäten ab.
(Ganze) Zahl aus einem Bereich
Die Prüfung erfolgt zweckmäßig in zwei Schritten:
- Handelt es sich um eine gültige (ganze) Zahl?
- Liegt sie im Intervall?
Bei solchen komplexen Tests bietet es sich an, diese in eine Funktion auszulagern:
| function CheckRange() { test -z "$1" && return 1 echo "$1" | egrep -q '^[[:space:]]*[+-]?[[:space:]]*[[:digit:]]+[[:space:]]*$' || return 2 [ "$1" -lt "-10" -o "$1" -gt "+10" ] && return 3; return 0 } |
Die Funktion testet in drei Schritten. Zuerst wird der korrekte Funktionsaufruf geprüft (mit Argument). Fehlt dieses, wird die Funktion mit dem Fehlercode "1" beendet. Schritt 2 umfasst die Prüfung auf eine ganze Zahl. Bei Fehler wird mit dem Status 2 zurück gekehrt. In Schritt 3 findet schließlich die Bereichsüberprüfung statt (hier von -10 bis +10). Auch hier wird im Fehlerfall ein eigener Rückgabewert (3) verwendet. Wurden alle Tests erfolgreich absolviert, wird "0" geliefert.
Die Anwendung der Funktion kann nach folgendem Schema erfolgen:
| user@sonne> Eingabe="0815" user@sonne> CheckRange $Eingabe || echo "Fehlercode $?" |
Reelle Zahl
Betrachten wir zuvor die Darstellungsmöglichkeiten für reelle Zahlen:
| +.12993 120.02 11 -0E2 1.44e-02 2. |
Eine solche Fülle von Varianten lässt sich nur schwerlich in einen einzigen Regulären Ausdruck pressen. Unsere Funktion wird deshalb die Eingabe der Reihe nach mit Mustern für die einzelnen Syntaxarten vergleichen. Wird ein Test bestanden, wird mit dem Status "0" zurück gekehrt. Wurden alle Tests negativ durchlaufen, signalisiert eine "2" einen Syntaxfehler:
| function CheckRealNumber() { test -z "$1" && return 1 # Gleitkommadarstellung mit Nachkommastellen ".01", " - 10.1 " ... echo "$1" | egrep '^[[:space:]]*[+-]?[[:space:]]*[[:digit:]]*\.?\ [[:digit:]]+[[:space:]]*$' && return 0 # Gleitkommadarstellung ohne Nachkommastellen "1.", " - 10 " ... echo "$1" | egrep '^[[:space:]]*[+-]?[[:space:]]*[[:digit:]]+\.?\ [[:space:]]*$' && return 0 # Exponentialdarstellung mit Nachkommastellen " + 0.01e01"... echo "$1" | egrep '^[[:space:]]*[+-]?[[:space:]]*[[:digit:]]*\.\ [[:digit:]]+[Ee][+-]?[[:digit:]][[:digit:]]?[[:space:]]*$' && return 0 # Exponentialdarstellung ohne Nachkommastellen " + 1e-1"... echo "$1" | egrep '^[[:space:]]*[+-]?[[:space:]]*[[:digit:]]+[Ee]\ [+-]?[[:digit:]][[:digit:]]?[[:space:]]*$' && return 0 return 2 } |
Wie Sie erkennen, erfordern scheinbar einfache Aufgaben bereits komplexe Lösungen. Der Aufwand rechtfertigt sich auf jeden Fall, wenn Sie in zahlreichen Skripten derartige Funktionen benötigen. Sammeln Sie solche Funktionen in einer eigenen Datei, so kann jedes Skript darauf zugreifen, indem es mittels . Datei_Name bzw. source Datei_Name diese "Bibliotheksdatei" einbindet.
Die präsentierten Lösungen sollten Ihnen die Fähigkeit verleihen, Funktionen zu schreiben, um jede beliebige Eingabe - ob per Kommandozeilenoption oder mittels Interaktion mit dem Benutzer - hinsichtlich ihrer Korrektheit zu testen. Nicht nur in der Shellprogrammierung sind unerwartete Eingaben die häufigste Ursache für einen unkontrollierten Programmablauf.
Parsen der Kommandozeilenargumente
Wie ein konkreter Wert auf Herz und Nieren geprüpft werden kann, sollte nun bekannt sein. Wenden wir uns nun den Möglichkeiten zu, die Argumente der Kommandozeile auszuwerten.
Nachfolgend bezeichnen wir als Argument jedes dem Kommando folgende Token auf der Kommandozeile. Von einer Option sprechen wir, wenn das Token durch ein führendes Minus eingeleitet wird; alle anderen Token sind Parameter.
| # Kommandozeile user@sonne> ./mein_skript -c 10 40 -f eingabe -rt # Kommando user@sonne> ./mein_skript -c 10 40 -f eingabe -rt # Argumente user@sonne> ./mein_skript -c 10 40 -f eingabe -rt # Optionen user@sonne> ./mein_skript -c 10 40 -f eingabe -rt # Parameter user@sonne> ./mein_skript -c 10 40 -f eingabe -rt |
Uns interessiert, ob
- die korrekte Anzahl Argumente angegeben wurde
- die Anordnung der Argumente richtig ist (manche Option erwartet noch einen oder mehrere Parameter, bspw. einen Dateinamen)
- keine unbekannten Optionen angegeben wurden
- die Parameter den erwarteten Typ besitzen (Siehe: "Prüfen der Eingabe")
Anzahl der Argumente
Im Sprachgebrauch der Bash ist oft von Positionsparametern die Rede. Und die Anzahl jener ist in der Variable $# gespeichert.
In einem Skript könnte eine Überprüfung folgendermaßen realisiert werden:
| if [ "$#" -lt "3" ]; then echo "Das Skript erwartet mindestens 3 Argumente" exit 1 fi # Andere Schreibweise: [ "$#" -lt "3" ] && { echo "Das Skript erwartet mindestens 3 Argumente"; exit 1; } |
Ist eine konkrete Anzahl Argumente erforderlich, bietet sich eine andere Lösung an. Wir testen, ob das letzte erwartete Argument angegeben wurde (die Methode schützt nicht vor zu vielen Angaben):
| Variable=${2:?"Anwendung: $0 Argument_1 Argument2"} |
Die Anwendung ist zu lesen als: "Ist $2 (2. Argument) gesetzt, so weise den Wert an "Variable" zu. Sonst gib die Meldung aus und beende das Skript". Die verwendete Substitution erklärt der Abschnitt Parameter- und Variablenexpansion der Bash.
Reihenfolge der Argumente und unbekannte Optionen
Beide Prüfungen lassen sich einfach in einem "Aufwasch" erledigen.
Im Zusammenhang mit den eingebauten Kommandos der Bash wurde die Anwendung von getopts anhand eines Beispiels erläutert. Ein Programmausschnitt, der die Optionen "-a", "-l", "-f Dateiname" und "-F" akzeptiert, sieht wie folgt aus:
| while getopts alf:F Optionen; do case $Optionen in a) echo "Option a";; l) echo "Option l";; f) echo "Option f Argument ist $OPTARG";; F) echo "Option F";; esac done |
getopts kümmert sich selbst um unzulässige Optionen (keine Parameter!), indem es mit einer Fehlermeldung abbricht. Die akzeptierten Optionen folgen dem Kommando; ist einer Option ein Parameter zugeordnet, wird dies durch einen der Option nachgestellten Doppelpunkt ausgedrückt.
Unbefriedigend sind allerdings zwei Tatsachen. Zum einen ist das die von getopts generierte Fehlermeldung, die wir vielleicht in Skripten vermeiden und durch eigene Ausgaben ersetzen möchten. Zum Zweiten ist das automatische Fortfahren mit der der getopts-Anweisung folgenden Zeile (im Beispiel gehts hinter "done" weiter) meist unerwünscht.
Problem Nummer 1 verschieben wir schlicht und einfach nach /dev/null (Umleitung der Fehlerausgabe). Das 2. Makel beseitigen wir, indem wir den Fall innerhalb der case-Anweisung berücksichtigen. Denn im Fehlerfall liefert getopts ein Fragezeichen ? als Resultat. Somit könnte ein Kommandozeilentest so ausschauen:
| while getopts alf:F Optionen 2>/dev/null;
do case $Optionen in a) echo "Option a";; l) echo "Option l";; f) echo "Option f Argument ist $OPTARG";; F) echo "Option F";; ?) echo "Unerwartete Option" # tue etwas... ;; esac done |
Schwachpunkte besitzt das Konzept noch immer. getopts vermag keine Parameter zu testen, sondern "nur" Optionen in Verbindung mit einem folgenden Parameter. Dieser Parameter steht zum Zeitpunkt der Bearbeitung der betreffenen Option in OPTARG. OPTIND enthält allerdings schon den Index des nächsten Kommandozeilenarguments. Um eine Option mit zwei (oder mehr) Parametern mit getopts zu realisieren, kann man mit $OPTARG auf den ersten Parameter und mit "eval echo `echo $OPTIND`" auf den folgenden zugreifen. Allerdings sollte bei dem resultierenden Wert getestet werden, ob es sich tatsächlich um einen Parameter (und nicht etwa um eine Option) handelt. Auch lassen sich lange Optionen "--version" keinesfalls durch getopts behandeln.
Ohne Verwendung von getopts hangeln wir uns durch die Liste der Positionsparameter. Ein Beispielcode, der dieselbe Funktionalität wie obiges getopts-Beispiel besitzt, lässt sich so notieren:
| while [ "$#" -gt "0" ]; do case $1 in -a) echo "Option a" shift;; -l) echo "Option l" shift;; -f) echo "Option f Argument ist $2" shift 2;; -F) echo "Option F" shift;; *) echo "Unerwartete Option" # tue etwas... ;; esac done |
Der Trick hierbei ist der Zugriff auf das jeweils erste Element der Positionsliste. Wurde dieses erfolgreich verarbeitet, so verschieben wir die Liste nach links (shift), sodass der ehemalige zweite Eintrag nun der erste ist. Eintrag 1 fällt einfach raus. Im Falle eines Parameters lesen wir die folgenden Listeneinträge aus und verschieben die Liste um die jeweilige Anzahl Elemente.
Bleibt noch anzuraten, Parameter stets auf den korrekten Typ hin zu überprüfen. Auch sollten Sie bei Skripten, die Argumente erfordern, eingangs verifizieren, dass tatsächlich welche angegeben wurden, sonst wird die "while"-Schleife gar nicht erst betreten.
Interaktive Eingaben
In Bashskripten fordern Sie mit Hilfe des Kommandos read den Benutzer zu Eingaben auf. Im Abschnitt zur Bash wurde die Anwendung des Kommandos durch mehrere Beispiele untermauert, sodass der Einsatz in Skripten klar sein sollte.
read wartet, bis der Benutzer seine Eingabe mit einem Zeilenumbruch ([Enter]) abgeschlossen hat. Wird read kein Argument (Variablenname) mitgegeben, so wird die gelesene Zeile der Shellvariablen REPLY zugewiesen. Folgen dem Kommando ein oder mehrere Variablennamen, so wird der Reihe nach das erste Token der Eingabe der ersten Variable zugewiesen, das zweite Token der zweiten Variable usw. Stehen mehr Token als Variablen zur Verfügung, erhält die letzte Variable alle noch nicht zugewiesenen Token. Sind es weniger Token, bleiben die überschüssigen Variablen unbelegt.
Ein read-Aufruf blockiert, es sei denn mit der Option -t Sekunden (erst ab Bash 2.04!) wurde eine Zeitspanne vereinbart, nach der das Kommando spätestens zurück kehrt, selbst wenn noch keine Eingabe durch den Benutzer erfolgte. Anhand des Rückgabestatus kann entschieden werden, ob der Timeout die Rückkehr bedingte.
Der Schwerpunkt dieses Abschnitt liegt auf "korrekte Eingaben", d.h. uns interessiert, ob die mittels read eingelesenen Werte im "grünen" Bereich liegen. Wie dies geht, sollte nach Studium des weiter oben stehenden Textes bereits bekannt sein.
Was wir hier demonstrieren möchten, ist eine Variante zur Positionierung des Cursors, sodass nach einer fehlerhaften Eingabe diese vom Bildschirm verschwindet.
Zum Umgang mit den Eigenschaften es Terminals kann das Kommando tput recht nützlich sein. Es erlaubt u.a. das Löschen des gesamten Bildschirms, die Platzierung des Cursors oder die Ausgabe in fetter Schrift. Für unsere Zwecke sind folgende Aufrufe interessant:
| tput bel | Alarmton ausgeben |
| tput clear | Löscht den Bildschirm |
| tput cols | Gibt die Anzahl Spalten des Terminals zurück |
| tput cup x y | Setzt den Cursor auf Zeile x, Spalte y |
| tput home | Entspricht "tput cup 0 0" |
| tput el | Zeile ab Cursorposition löschen |
| tput ed | Bildschirm ab Cursorposition löschen |
Im folgenden Skriptfragment wird zur Eingabe einer Zahl aufgefordert. Solange die Eingabe nicht dem erwarteten Typ entspricht, springt der Cursor an die Eingabeposition zurück:
| function writeln() { tput cup $1 $2 # Cursor positionieren tput el # Rest der Zeile löschen shift 2 # Parameter für die Koordinaten entfernen echo -n $*" " # Rest der Parameterliste ausgeben } tput clear writeln 3 5 "Beliebige Zahl eingeben:" while :; do writeln 3 30 read wert echo $wert | egrep -q '[[:digit:]]+' && break tput bel done echo "Eingabe war: $wert" |
Möchten Sie die Eingaben am Bildschirm verbergen (Passworteingabe etc.), so hilft die Terminalsteuerung über das Kommando stty weiter. Der folgende Programmausschnitt schaltet die Anzeige der eingegebenen Zeichen ab:
| echo -n "Passwort :" stty -echo read $password stty echo |
Bei der Anwendung von Passwortabfragen in Shellskripten sollten Sie niemals das unverschlüsselte Passwort im Skript speichern, da das Skript von jedem, der es ausführen darf, auch gelesen werden kann.
| Rekursion |
|
Vorab möchte ich deutlich heraus stellen, dass Rekursion kein Konzept der Bash, sondern eine allgemeine Programmiermethode darstellt.
Man bezeichnet eine Funktion als rekursiv, wenn sie sich selbst aufruft. Das mag verwirrend klingen, führt aber in zahlreichen Fällen zu besser strukturiertem - weil kürzerem - Kode. Aber Beispiele verdeutlichen ein Prinzip oft besser, als es die Sprache vermag - aus jenem Grund lassen wir Beispiele sprechen.
Arbeit im Verzeichnisbaum
Stünden Sie vor der Aufgabe, in jedem Verzeichnis unterhalb eines gegebenen Startverzeichnisses irgendwelche Maßnahmen vorzunehmen, so würden Sie vermutlich mittels find alle Verzeichnisse aufspüren und das Ergebnis einer Liste zuführen. In einer auf der Liste arbeitetenden Schleife würden Sie dann die Arbeiten für jedes einzelne Verzeichnis verrichten. Ihr Lösungsansatz wäre durchaus praktikabel und könnte wie folgt aussschauen:
| user@sonne> cat doit_in_dir #!/bin/sh verzeichnis=${1:-./} for i in `find $verzeichnis -type d`; do cd $i echo "Prozess $$ ist in `pwd`" cd - done |
Nun versuchen Sie einmal, das Skript einzig mit ls und den eingebauten Kommandos der Bash zu realisieren. Mit den so genannten iterativen Programmiermethoden wird die Größe Ihres Skripts um Einiges zunehmen. Per Rekursion hingegen schrumpft der Aufwand:
| user@sonne> cat
doit_in_dir_recursiv #!/bin/sh cd ${1:-./} for i in `ls`; do test -d $i && $0 $i done echo "Prozess $$ ist in `pwd`" |
Obiges Skript funktioniert nur, wenn es mit vollständigem Pfadnamen gestartet wird. An einer Erweiterung auf relative Pfadnamen kann sich der Leser versuchen; wir werden später im Text eine Lösung präsentieren.
Die Ausgabe wurde in den Beispielen bewusst um die Prozessnummer erweitert, um den Unterschied zwischen beiden Skripten zu kennzeichen. Die rekursive Variante generiert für jedes Verzeichnis einen eigenen Prozess, der die Bearbeitung für diesen Teil des Verzeichnisbaumes übernimmt. Da Systemressourcen allerdings nur begrenzt verfügbar sind, sollte die Rekursion über Programme nur bei "geringen" Rekursionstiefen angewandt werden. In der Hinsicht ist obiges Beispiel sicher schlecht gewählt. Aber bekanntlich heiligt der Zweck die Mittel.
Berechnung der Fakultät (rekursiv)
Eingebettet in den Hinweisen zur Fehlersuche in Skripten, wurden Sie bereits mit einer iterativen Lösung zur Berechnung der Fakultät konfrontiert. Hier zeigen wir Ihnen nun die rekursive Variante, die - sieht man einmal von den Variablendeklarationen ab - mit ganzen zwei Zeilen auskommt. Zum einen die Überprüfung, ob die Abbruchbedingung erreicht wurde und zum anderen ein Rechenschritt:
| user@sonne> cat fac_rec_bad #!/bin/sh declare -i Resultat=${2:-1} declare -i Fakultaet=$1 test "$Fakultaet" -le "1" && { echo "Ergebnis = $Resultat"; exit 0; } $0 $Fakultaet-1 $Resultat*$Fakultaet |
Lässt man sowohl die iterative als auch die rekursive Variante der Berechnung gegeneinander antreten, wird man schnell bemerken, dass letztere deutlich mehr Laufzeit beansprucht. Überdeutlich tritt der durch die Prozesserzeugungen notwendige Wasserkopf zu Tage. Deshalb gilt die Maxime: Vermeiden Sie, wann immer es möglich ist, die Rekursion auf Programmebene. Realisieren Sie Rekursion besser mit Funktionen:
| user@sonne> cat fac_rec_good #!/bin/sh function factorial() { local value=${1:=1} [ "$value" -le "1" ] && { echo 1; return; } echo $(($value * `factorial $value-1` )) } factorial $1 |
Weitere Anwendungen rekursiver Funktionen werden uns im Verlauf des Abschnitts noch begegnen.
| Erwärmung |
|
Beginnend mit kleinen Aufgabenstellungen versucht dieser Abschnitt, Ihnen einen effizienten Stil der Programmierung nahezulegen. Viele der Beispiele eignen sich durchaus zur Aufnahme in Bibliotheken, sodass zumeist die Realisierung als Funktion bevorzugt vorgestellt werden soll. Zum Ende hin schrauben wir den Anspruch allmählich nach oben, um den Grundstein für aufwändige Skriptprojekte zu legen.
Absolute Pfadnamen
Skripte, die Dateinamen übergeben bekommen, benötigen diesen häufig mit vollständiger Pfadangabe. Man könnte die Forderung auch an den Nutzer weiter leiten, aber mit den Mitteln der Bash ließe sich ebenso der absolute Name zu einer relativen Angabe ermitteln:
| function GetAbsolutePathName() { test -z "$1" && exit Pfad=${1%/*} Datei=${1##*/} echo `cd $Pfad 2>/dev/null && pwd || echo $Pfad`/$Datei } |
Eine Funktion in der Bash kann im eigentlichen Sinne keinen Funktionswert zurück liefern, deshalb schreibt sie das Ergebnis auf die Standardausgabe. Die Umleitung der Fehlerausgabe von cd ist notwendig, falls der Parameter einen nicht existierenden Pfad enthält. Somit gibt die Funktion im Fehlerfall den Eingangswert unverändert zurück.
Eine andere Realisierung ermöglicht die Verwendung der Kommandos dirname und basename zum Extrahieren von Datei- bzw Pfadnamen. Allerdings arbeitet die bashinterne Parametersubstitution durch Vermeidung neuer Prozesse schneller.
| user@sonne> GetAbsolutePathName
../user /home/user |
Zeichenkettenfunktionen
Obige Funktion zur Generierung des absoluten Dateinamens enthält eine Parametersubstitution. So kompliziert deren Anwendung auch ist, so wichtig ist sie für die Shellprogrammierung. Wann immer es etwas an Zeichenketten zu manipulieren gibt, wird man auf diesen Mechanismus zurück greifen.
Einem C-Programmierer werden Funktionen wie strcpy, strncpy, strcat... bekannt vorkommen. Wir betrachten nachfolgend, wie solche Funktionen mit Mitteln der Bash simuliert werden können.
strcpy dient zum Kopieren von Zeichenketten. Als Parameter soll die Funktion zwei Variablennamen übergeben bekommen. Die erste Variable enthält später eine exakte Kopie des Inhalts der zweiten Variable. Eine Variablenzuweisung in eine Funktion zu packen, erscheint nicht sonderlich schwierig. Jedoch erweist sich die Aufgabe als erstaunlich verzwickt:
| function strcpy() { eval "$1"=\'"${!2}"\' } |
Vermutlich verstehen Sie jetzt gar nichts. Und genau das ist der Sinn der Übung. Zunächst sollte klar sein, dass auf die beiden Parameter in der Funktion über $1 und $2 zugegriffen werden kann. $1 enthält dabei den Namen der Variablen, der die Kopie zugewiesen werden soll und $2 ist der Name der Variablen mit der Quellzeichenkette.
Würde eval die Zeile nicht zieren, so expandiert der Ausdruck links des Gleichheitszeichens ($1) zum Namen der Variablen. Alles rechts expandiert zum Inhalt der durch $2 benannten Variablen. Diese Indirektion wird durch das Ausrufezeichen hervorgerufen. Nach erfolgter Expansion betrachtet die Bash das Resultat als den Namen eines Kommandos. Würde sie es nun starten, wäre ein Fehler die Konsequenz:
| user@sonne> strcpy_buggy() { "$1"=\'"${!2}"\'} user@sonne> var2=foo; strcpy_buggy var1 var2 bash: var1='foo': command not found |
Erst eval sorgt für eine nochmalige Expansion durch die Bash. Diese führt nun die Variablenzuweisung aus und startet das resultierende Kommando. Da aus einer Zuweisung aber nichts resultiert, wird die Bash nichts tun...
strncpy kopiert nun maximal n Zeichen aus der Quelle ins Ziel. Die Funktion benötigt also als dritten Parameter die Anzahl maximal zu kopierender Zeichen.
| function strncpy() { local -i n=$3 local str2=${!2} test "${#str2}" -gt "$n" && str2=${str2:0:$n}; eval "$1"=\'"${str2}"\' } |
Die zwei Parameterexpansionen, die im obigen Beispiel hinzu kamen, sind ${#Variable} zum Auslesen der Anzahl in einer Variablen gespeicherten Zeichen und ${Variable:ab:Länge} zum Extrahieren einer Teilzeichenkette einer bestimmten Länge ab einer gegebenen Position.
Die letzte in diesem Zusammenhang präsentierte Zeichenkettenfunktion soll strcat sein, die zwei gegebene Zeichenketten miteinander verkettet und das Ergebnis in der ersten Variablen speichert:
| function strcat() { eval "$1"=\'"${!1}${!2}"\' } |
Ich hoffe mit den Beispielen ihr Verständis für die Zeichenkettenbearbeitung durch bashinterne Mittel ein wenig geschult zu haben. Versuchen Sie sich selbst an einer Funktion strncat, die maximal n Zeichen der Quelle an die Zielzeichenkette anfügt. Schreiben Sie Funktionen strcmp und strncmp, die "0" liefern, falls zwei Zeichenketten (in den ersten "n" Zeichen) übereinstimmen und "1" sonst. Einen Zacken anspruchsvoller sind Funktionen strcasecmp und strncasecmp zu schreiben, die die Groß- und Kleinschreibung nicht berücksichtigen (Tipp: Die Shelloption nocaseglob kann auch innerhalb einer Funktion (de)aktiviert werden.).
Mathematische Funktionen
Sie sollten niemals versuchen, in umfangreichen Skripten die arithmetischen Substitutionen der Bash als Taschenrechner zu missbrauchen. Dass wir es hier dennoch tun, dient einzig der Lehre, da mathematische Algorithmen häufig mittels Schleifen oder durch rekursive Funktionen implementiert werden können.
Beginnen wir mit der Potenzfunktion zur Berechnung von xy. Ohne ein externes Kommando zu bemühen, bietet sich in der Bash eine Schleife an:
| function power() { local -i x=${!1} local -i result=$x for ((i=${!2}; i>1; i--)); do result=$result*$x done echo $result; } |
Die Anwendung obiger Funktion geschieht wie folgt:
| user@sonne> x=2; y=10 user@sonne> power x y 1024 |
Beachten Sie, dass obige Realisierung nur in der Bash ab Version 2.04 korrekt arbeitet; passen Sie sie ggf. auf Ihr System an!
Dieselbe Funktion in der rekursiven Variante könnte wie folgt geschrieben werden:
| function power_rec() { local -i x=${!1} local -i y=${!y}-1 test $y = 0 && { echo $x; return; } echo $(($x * `power_rec x y`)) } |
Andere Algorithmen wie die Berechnung von Fibonacci-Zahlen oder der binomischen Koeffizienten (Pascal'sches Dreieck) lassen sich nach ähnlichem Schema modellieren, solange sie auf ganzen Zahlen operieren.
Was eher eine Bereicherung des Funktionsumfangs der Shell wäre, sind Funktionen, die bestimmte Zahlenformate in andere überführen. Konkret wollen wir eine Funktion entwickeln, die zu einem gegebenen dezimalen Wert die zugehörige Binärdarstellung liefert.
Der Algorithmus klingt in der Theorie recht einfach: "Dividiere die Zahl ganzzahlig sooft durch 2, bis sie kleiner als 1 wird. Ergibt die Division durch 2 in einem Schritt einen Rest, so schreibe eine '1', sonst schreibe eine '0'. Die sich ergebende Zeichenkette ist - rückwärts gelesen - die gesuchte Binärdarstellung."
Um die Funktion übersichtlich zu halten, lagern wir die Entscheidung, ob eine Zahl (un)gerade ist in eine Funktion is_even() aus:
| function is_even() { local -i var=${!1}/2 if [ "${!1}" -eq "$(($var*2))" ]; then echo "0" else echo "1" fi } |
In einer "echten" Programmiersprache hätte eine einfache Bitoperation als Test genügt; in der Bash ist der Aufwand ungleich höher. Die rekursive Lösung der gesuchten Funktion kann damit wie folgt geschrieben werden:
| function dec2bin_recursiv() { local -i var=${!1} test "$var1" -le "1" && { echo $var1; return; } local -i var2=$(($var1/2)) echo "`dec2bin var2``is_even var1`" } |
Die Zeichenkette der Binärdarstellung baut sich bei obiger Anordnung quasi "von hinten" auf.
Die iterative Lösung derselben Aufgabe erfordert den Zugriff auf eine weitere Hilfsfunktion, die die Zeichenkette zunächst in "gedrehter" Reihenfolge generiert:
| function dec2bin_reverse() { local -i var=${!1} for ((i=${!1}; i>0; i=i/2)); do echo -n `is_even i` done } |
Die "Hauptfunktion" realisiert einzig das Drehen der Zeichenkette:
| function dec2bin_iterative() { local -i var=`dec2bin_reverse ${!1}` for ((i=${#var}; i>0; i--)); do echo -n ${var:$(($i-1)):1} done echo "" } |
Der abschließende echo-Aufruf dient einzig dem Einfügen des Zeilenumbruchs.
Die vorgestellten Beispiele demonstrieren zum einen die erstaunlichen Möglichkeiten des Rechnens mit reinen Bash-Werkzeugen; aber auch die gewöhnungsbedürftige Syntax. Versuchen Sie die Lösungen nachzuvollziehen. Eine gesetzte Shelloption xtrace (set -x) kann in vielen Fällen den internen Lauf der Skripte veranschaulichen.
Dateien bearbeiten
Mit Werkzeugen wie awk oder sed stehen mächtige Hilfsmittel zur Verfügung, um Textdateien zu durchsuchen und zu bearbeiten. Beide Programme manipulieren allerdings nicht die Datei selbst, sondern schreiben das Ergebnis auf die Standardausgabe.
Der naive Ansatz, dem mit der Ausgabeumleitung zuvorzukommen, scheitert:
| sed 's/ / /g' datei > datei |
Warum? Wenn Sie keine schlüssige Erklärung parat haben, dann lesen Sie nochmals nach, wie und wann die Bash die Ein- und Ausgabeumleitungen bei einfachen Kommandos organisiert.
Im Skript lässt sich schnell Abhilfe finden:
| ... sed 's/ / /g' datei > /tmp/tmp.$$ mv /tmp/tmp.$$ datei ... |
Damit gelingt aber immer noch kein »wahlfreier« Zugriff auf den Inhalt der Datei. Es gibt genügend Situationen, in denen man »auf die Zeile davor« zugreifen muss, weil gerade die folgende Zeile bestimmten Bedingungen genügte.
Aber auch hierfür lassen sich Lösungen finden, indem eine Datei »in den Speicher« gelesen wird und die eigentliche Arbeit dann auf diesem Speicher erfolgt.
| function readfile() { local File=$1 local SaveTo=$2 local -i counter=0 while read line; do eval "$2[$counter]"=\'$line\' counter=$(($counter+1)) done < $File eval "$3"=$counter } |
Die Funktion readfile() wird mit dem Dateinamen als ersten und der Variable, die die Datei aufnehmen soll als zweitem Parameter gerufen. Als »Rückgabewert« liefert sie im dritten Argument die Anzahl gelesener Zeilen. Dies ist wichtig, da zu einer Feldvariablen nicht entschieden werden kann, wie viele Elemente sie enthält.
Auf die einzelnen Zeilen der Datei können Sie nun mittels Variable[Zeilenummer] zugreifen und irgendwann, wenn die Bearbeitung abgeschlossen ist, möchten Sie die Daten auch wieder zurück schreiben. Hierzu verhilft Ihnen die Funktion writefile(), die als Argumente die Variable mit den Zeilen sowie die Anzahl der Zeilen übergeben bekommt:
| function writefile() { local Array=$1 for ((i=0; i<${!2}; i++)); do eval echo "\${$Array[$i]}" done } |
Angenommen, obige Funktionen stünden in einer Datei mit dem Namen "filehandling.sh", dann könnte in einem Programm so vorgegangen werden:
| #!/bin/sh # Laden der "Bibliotheksdatei" . filehandling.sh # Datei einlesen readfile zu_bearbeitende_Datei FeldVariable Anzahl # Inhalt bearbeiten for ((i=0; i<$Anzahl; i++)); do # Bearbeiten von FeldVariable[$i]... done # Datei schreiben writefile FeldVariable Anzahl > zu_bearbeitende_Datei |
Schlanker Pinguin
Der Begriff des Embedded Linux ist Ihnen sicher schon einmal zu Ohren gekommen. Es geht darum, die Steuerung technischer Geräte, wie Radios, Uhren, Waschmaschinen, Handys... einem Prozessor zu überlassen. Auf so einem Prozessor werkelt natürlich ein Betriebssystem und neuerdings vermehrt auch Linux. Aus Kostengründen werden sowohl für Prozessor als auch für die Peripherie nur Bauelemente mit arg begrenzten Ressourcen eingesetzt. Oft müssen Betriebssystem und "Betriebssoftware" sich in magere 2 MB FlashROM teilen. Wenn Sie jetzt an Ihre Linux-Installation denken, so fragen Sie sich vielleicht, wie Linux soweit abgespeckt werden kann?
Selbst bei Verzicht auf "unnütze" Programme summieren sich die Dienstprogramme auf mehr als 1 Megabyte. Der Kernel lässt sich auf unter 300 kByte drücken, aber damit erschöpft sich das Sparpotenzial fürs erste.
Auf den Einsatz in embedded Systemen zugeschnittene Linux-Versionen erfahren zumeist eine grundlegende Überarbeitung der Quellen. Der Kernel und jedes für das Zielsystem vorgesehene Programm werden somit um nicht benötigte Funktionalität entlastet; Kernel in Größenordnung von 200 kByte inklusive Netzwerkunterstützung werden so erzielt.
Aber uns beschäftigt hier das Thema der Shellprogrammierung und wir möchten anhand einiger Beispiele demonstrieren, wie sich zwingend notwendige Dienstprogramme mit Mitteln der Bash simulieren lassen. Natürlich erfordert dies eine Beschränkung der Optionen, über die das originale Programm verfügt. Aber die meisten davon wendet der Durchschnitts-Benutzer ohnehin niemals an.
Beginnen wir mit head, das in der dynamisch gelinkten Programmvariante immerhin mit 12 kByte zu Buche schlägt. Von den Optionen wird wohl ohnhin nur "-n" in Frage kommen, um die Standardvorgabe von 10 darzustellenden Zeilen abzuändern.
|
#!/bin/sh # Erweiterte Expansion einschalten shopt -s extglob declare -i ANZAHL=10 declare -i DATEIZAEHLER=0 declare -i ZEILENNUMMER=0 Datei= while [ "$#" -gt "0" ]; do case "$1" in -n ) # Option: "-n Zeilen" ANZAHL=$2 [ $ANZAHL = 0 ] && exit 0 shift 2 ;; -+([0-9]) ) # Option: "-Anzahl" ANZAHL=${1:1} [ $ANZAHL = 0 ] && exit 0 shift ;; * ) # Andere Angaben sind Dateinamen (Test auf Existenz!) [ -e "$1" ] || { echo "$0: $1: Datei oder Verzeichnis nicht gefunden"; exit 1; } Datei[$DATEIZAEHLER]="$1" DATEIZAEHLER=$DATEIZAEHLER+1 shift ;; esac done if [ $DATEIZAEHLER = 0 ]; then # Lesen von der Standardeingabe while read line; do echo "$line" ZEILENNUMMER=$(($ZEILENNUMMER+1)) test $ZEILENNUMMER = $ANZAHL && break done else for ((i = 0; i < $DATEIZAEHLER; i++)); do # Für jede Datei beginnt die Zählung von vorn ZEILENNUMMER=0 # Formatierung der Ausgabe gemäß des Originals test "$i" -gt "0" && echo "" test "$DATEIZAEHLER" -gt "1" && echo "==> ${Datei[$i]} <==" while read line; do echo "$line" ZEILENNUMMER=$(($ZEILENNUMMER+1)) test $ZEILENNUMMER = $ANZAHL && break done < ${Datei[$i]} i=$(($i+1)) done fi |
head in Bashfassung arbeitet damit fast exakt wie das originale Kommando, belegt aber gerade mal etwas mehr als 1 KByte Speicherplatz (und der ließe sich durch kürzere Variablennamen weiter reduzieren).
Zur Realisierung des Kommandos tail beschränken wir uns auf eine Diskussion der Vorgehensweisen. Was die Auswertung der Kommandozeilenoptionen betrifft, kann das obige Skript "head" als Vorlage dienen. Einzig um die Option "-f" ist die while-Schleife zu erweitern. Um nun die letzten "n"-Zeilen anzusprechen, bieten sich an:
- Die Umkehr der Eingabedateien mittels tac und weiteres Vorgehen analog zum head-Skript.
- Das Auswerten der Zeilenanzahl in den Dateien mittels wc -l. Anschließend werden alle Zeilen eingelesen, aber nur die letzten "n" ausgegeben.
-
Das Einlesen aller Zeilen, wobei die Zeilen der Reihe nach in ein Feld mit "n" Elementen gespeichert werden. Wurde das "n"-te Element geschrieben, wird der Index auf 0 zurück gesetzt und somit das "n-1"-te Element überschrieben (Ringpuffer). Nach Einlesen der gesamten Datei wird die Ausgabe mit Feldelement nach dem zuletzt geschriebenen begonnen:
...
# Einlesen in ein Feld
while read line; do
FELD[ZEILENNUMMER]=$line
ZEILENNUMMER=$(($ZEILENNUMMER+1))
test $ZEILENNUMMER = $ANZAHL && ZEILENNUMMER=0
done < $Datei
# Ausgabe
declare -i ZAEHLER=$ANZAHL
while [ $ZAEHLER -gt 0 ]; do
echo ${FELD[$ZEILENNUMMER]}
ZEILENNUMMER=$(($ZEILENNUMMER+1))
test $ZEILENNUMMER = $ANZAHL && ZEILENNUMMER=0
ZAEHLER=$(($ZAEHLER-1))
done
Von den skizzierten Lösungen bevorzuge ich die 3., da sie vollends auf Mitteln der Bash basiert.
Ein Problem wird sich dem Leser nun stellen? Wie kann man das Verhalten von tail -f (also die permanente Ausgabe neu hinzukommender Zeilen) realisieren?
Kein Problem! Wird eine Datei fest mit einem Dateideskriptor verbunden, so führt jeder Lesevorgang auf dem Deskriptor (read) zum Verschieben des Zeigers um eine Zeile. Wurde das Dateiende erreicht, kehrt der Leseversuch unverzüglich zurück. Ein erneuter read-Aufruf liest die nächste Zeile aus - sofern sie existiert. Gibt es keine neue Zeile, wird einfach nichts gelesen...
Das nächste Programmfragment demonstriert die Anwendung des Verfahrens:
| # Abfangen der Signale 2 und 15, Schließen des
Deskriptors 3 trap 'exec 3<&-' 2 15 # Die Datei wird mit dem Eingabedeskriptor 3 verbunden: exec 3< Beispiel_Datei # Endlosschleife while:; do while read line; do # Ausgabe der Zeile echo $line done # 1 Sekunde schlafen sleep 1 done |
Obige endlos-while-Schleife kann nur durch ein entsprechendes Signal (meist [Ctrl]-[C]) beendet werden. In dem Fall sollte unbedingt der Dateideskriptor geschlossen werden, was durch Fangen des Signals realisiert wird.
Versuchen Sie sich selbst an der Vollendung des tail-Skripts!
Neben echo erweist sich das Kommando dd als nahezu unentbehrlich. dd kopiert wahlweise die Standardein- auf die Standardausgabe, die Standardeingabe in Dateien, den Dateiinhalt auf die Standardausgabe usw. In Shellskripten kann es damit als Basis für die Simulation zahlreicher anderer Kommandos herhalten.
Da wäre zunächst cat, das sich durch einige wenige Skriptzeilen (wir lassen die Optionen von cat einmal außen vor) ersetzen lässt:
| #!/bin/sh exec 2>&- if [ $# = 0 ]; then dd else for i do dd < $i done fi |
Das Kommando dd fabriziert auf der Standardfehlerausgabe eine abschließende Statusmeldung über die Anzahl kopierter Daten. Um diese zu unterdrücken, wird zu Beginn des Skripts die Standardfehlerausgabe geschlossen.
Ein vereinfachtes cp ist mittels Bash und dd so zu ersetzen:
| #!/bin/sh test -e "$1" || { echo "Quelldatei nicht gefunden"; exit 1; } test -z "$2" && { echo "Aufruf: $0 <Quelldatei> <Zieldatei>"; exit 2; } dd if="$1" of="$2" |
Einen entscheidenden Mangel weist obiges Skript dennoch auf: Die Rechte bleiben nicht erhalten. Um diese zu setzen, bleibt wohl nur der Griff zu chmod übrig. Steht noch die Frage des Auslesens der Rechte der Originaldatei... Unter der Annahme, dass in "embedded Linux"-Varianten ohnehin keine komplexe Benutzerverwaltung sinnvoll ist, können wir uns auf den Erhalt der Schreib- und Ausführungsrechte für den Eigentümer beschränken. Und diese ist per test ermittelbar:
| #!/bin/sh function calc_rights() { mode='u=r' # Ohne Leserecht wird schon das Kopieren scheitern test -w $1 && mode=${mode}w test -x $1 && mode=${mode}x echo $mode } test -e "$1" || { echo "Quelldatei nicht gefunden"; exit 1; } test -z "$2" && { echo "Aufruf: $0 <Quelldatei> <Zieldatei>"; exit 2; } dd if="$1" of="$2" chmod `calc_rights $1` $2 |
Zuletzt noch eine Bash-Implementierung des Kommandos ls. Bei Verzicht auf sämtliche Optionen genügen wenige Kodezeilen:
| function ls() { set -- * for i do echo $i done } |
Ordnung im Dateisystem
Wer sich der Programmierung widmet oder selbst Hand an die Kompilierung von Quellpaketen oder des Kernels legt, der hat bereits Bekanntschaft geschlossen mit Objekt-Dateien. Diese Dateien werden während der Übersetzung von Programmen generiert und sind nach Erzeugung des Binaries oder einer Bibliothek nicht mehr notwendig.
Andere Dateien, denen Sie hin und wieder im Dateisystem begegnen, nennen sich core. Dabei handelt es sich um Speicherauszüge (RAM) von abgestürzten Programmen. Ein Experte könnte anhand solcher Dateien der Fehlerursache auf den Grund gehen ("debuggen"); die meisten Anwender werden aber damit nichts anfangen können.
Die dritte Dateiart, von der wir mit dem nachfolgenden Skript unser Dateisystem bereinigen wollen, endet mit der Tilde (*.~). Zahlreiche Programme kennzeichen so ihre Sicherungskopien; nicht selten wird ihr Dasein bei Programmende schlicht ignoriert.
Wünschenswert wäre ein Skript, das, per Kommandozeilenoptionen ("-c" für Core-, "-o" für Objekt und "-t" für "+~"-Dateien) gesteuert, die entsprechenden Dateien im System ausfindig macht und entfernt. Da Löschen unter Linux gleichbedeutend mit dem unwiderruflichen Datenverlust ist, wäre eine Nachfrage vor dem Löschvorgang nützlich. Auch hierzu soll das Skript eine Option ("-i") kennen.
Zunächst das Skript:
| user@sonne> cat delete_trash #!/bin/sh object= tilde= core= inter= for i do case "$i" in -c ) core=core;; -o ) object=\*.o;; -t ) tilde=\*\~;; -i ) inter=-i;; *) echo "Unbekannte Option" exit 1;; esac done for i in $core $object $tilde; do for x in $(find $(pwd) -name "$i"); do rm $inter $x done done |
Das Skript verwendet einige Kodezeilen, die typisch für einen sauberen Stil sind:
| object= ... |
Die Initialisierung mit "Nichts" garantiert, dass eventuell in der Shell vorhandene globale Variablen gleichen Namens keinen Eingang in das Skript finden.
| ... -o ) object=\*.o;; ... |
Das anschließende Parsen der Kommandozeile sollte verständlich sein. Allerdings belegen wir die Variablen sofort mit den notwendigen Suchmustern. Der Sinn wird in den folgenden Anweisungen klar:
| for i in $core $object $tilde; do for x in $(find $(pwd) -name "$i"); do rm $inter $x done done |
Überlegen Sie, zu welchen Werten die Liste der äußeren for-Schleife expandiert. Angenommen, alle drei Optionen waren gesetzt, so ergibt sich:
| for i in "core" "*.o" "*~"; do |
Die Schleifenvariable i wird demnach der Reihe nach mit den Werten "core", "*.o" und "*~" belegt. Das find der inneren for-Schleife sucht demnach zuerst nach Dateien mit dem Namen "core", im zweiten Duchlauf werden auf .o endende Dateien gesucht...
Schließlich expandiert die Zeile mit dem Kommando rm zu
| rm -i Dateiname |
oder zu
| rm Dateiname |
je nachdem, ob "-i" als Kommandozeilenoption übergeben wurde oder nicht.
| Komplexe Anwendungen |
|
Symbolsuche
Im Allgemeinen werden Computerprogramme nicht in all ihrer Funktionalität neu geschrieben, sondern sie greifen zu nicht unbedeutenden Teilen auf bestehende Bausteine zurück. Solche Bausteine (»Objekt-Kode«) wiederum liegen als Sammlungen in Bibliotheken vor.
Ausführbare Programme lassen sich in zwei Kategorien gliedern. Zum einen die statischen Programme, denen bereits zur Übersetzungszeit alle notwendigen Bausteine aus den Bibliotheken »einverleibt« werden. Die zweite Ausprägung sind die dynamischen Programme (genauer: »dynamisch gelinkte Programme«), die nur die Schnittstellen zum Aufruf solcher Bausteine enthalten; nicht aber deren Implementierung.
Die Dateigröße dynamisch gelinkter Programme fällt somit um ein Vielfaches geringer aus, als die statischer. Allerdings erfordert ihre Ausführung das Vorhandensein der Bibliothek, die die Symbole - ein Baustein kann beliebig viele Symbole definieren oder verwenden - enthält. Und hier fangen die Probleme oftmals an, nämlich dann, falls ein benötigtes Symbol nicht gefunden werden kann:
| # Ursache: Bibliothek wurde nicht
gefunden user@sonne> /opt/kde2/bin/ksplash /opt/kde2/bin/ksplash: error in loading shared libraries: libjpeg.so.62: cannot open shared object file: No such file or directory # Ursache: Symbol wurde nicht gefunden user@sonne> /opt/kde2/bin/ksplash /opt/kde2/bin/ksplash: error in loading shared libraries: /opt/kde2/lib/libkdeui.so.3: undefined symbol: __ti10KDNDWidget |
Die erste Ursache, dass eine solche Bibliothek nicht geöffnet werden konnte, muss nicht zwangsläufig bedeuten, dass diese im System nicht doch existiert. Sie konnte eventuell nur nicht durch den »Dynamischen Lader«, den ldd, gefunden werden. Hieraus ergibt sich eine erste Anforderung an unser Skript: Es soll nach einer Bibliothek suchen und - falls die Suche positiv verlief - Maßnahmen treffen, um den Fehler zu beheben. Diese sind:
- Konfiguration des ldd, sodass er die Bibliothek automatisch findet (erfordert Root-Rechte)
- Setzen der Variablen LD_LIBRARY_PATH (darf jeder) in der Datei ».profile«
Komplizierter ist das Vorgehen bei einem vermissten Symbol. Hier gilt es, die Bibliothek zu finden, in der das Symbol definiert wird. Das Kommando, mit dem Informationen aus einer Bibliothek (oder auch einer Objekt-Datei) ausgelesen werden können, ist nm. Um einen Eindruck vom Aufbau einer Bibliothek zu gewinnen, betrachten wir einen Ausschnitt einer typischen Ausgabe von nm:
| # stark gekürzt... user@sonne> nm /usr/lib/libc.a ... printf.o: 00000020 t Letext 00000000 T _IO_printf 00000000 T printf U stdout U vfprintf ... |
Die für unsere Zwecke interessanten Einträge sind die mit T bzw. U markierten Zeilen. Erste bezeichnen Symbole, die der Baustein (»printf.o«) definiert, letztere sind verwendete Symbole, die ein anderer Baustein bereit stellen muss. Sie sind an dieser Stelle undefiniert. Es gilt nun, zu einem gegebenem Symbol die Bibliothek zu suchen, die dieses definiert. Wird eine solche gefunden, treffen wir dieselben Maßnahmen wie oben beschrieben. Bei negativem Suchergebnis hilft wohl nur die Konsultation einer Suchmaschine im Internet...
Als Anforderungen an unser Skript notieren wir:
- Es soll nach Bibliotheksnamen -n Name suchen (mit Metazeichen)
- Es soll nach der Bibliothek suchen, die ein Symbol -s Symbol definiert
- Ein Startverzeichnis -d Verzeichnis für die Suche kann angegeben werden
Als Aktionen sind möglich:
- Bei erfolgreicher Suche kann der ldd konfiguriert werden -l
- Bei erfolgreicher Suche kann die Variable LD_LIBRARY_PATH exportiert werden -x (der Eintrag erfolgt in .profile)
Bevor Sie sich das Skript zu Gemüte führen noch eine Anmerkung. Der dynamische Lader ldd durchsucht in der Voreinstellung immer die Verzeichnisse /lib und /usr/lib, sodass diese weder in /etc/ld.so.conf noch in LD_LIBRARY_PATH angegeben werden sollten. Nachfolgende Skriptlösung verhindert allerdings den Versuch, solche Verzeichnisse einzubinden, nicht, weshalb Sie die Optionen -l und -x erst nach einem erfolgreichen Durchlauf des Skripts verwenden sollten.
|
#!/bin/sh # Einige Funktionen... function GetAbsolutePathName() { test -z "$1" && exit Pfad=${1%/*} Datei=${1##*/} echo `cd $Pfad 2>/dev/null && pwd || echo $Pfad`/$Datei } function find_symbol_in_lib() { file $1 | fgrep -q 'shared object' || return 1 file $1 | fgrep -q 'not stripped' || return 1 nm $1 | fgrep -qw "T $2" } function Config_LD_LIBRARY_PATH() { . ~/.profile temp=`echo $LD_LIBRARY_PATH | awk 'BEGIN {RS=":"} $0 ~ suche {print $0}' suche="^$1/?[[:space:]]\*$"` test -z $temp || return 0 # schon enthalten => nichts zu tun temp="export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:$1" sed '/.*LD_LIBRARY_PATH.*/d' ~/.profile > ~/.profile.$$ echo $temp >> ~/.profile.$$ mv ~/.profile.$$ ~/.profile } function Config_Ldd() { test "$UID" != "0" && { echo "Option '-l' erfordert Rootrechte"; } cat /etc/ld.so.conf | grep -q ^[[:space:]]*$1/*[[:space:]]*$ test "$?" == "0" && return 0; # Pfad bereits enthalten cat $1 >> /etc/ld.so.conf /sbin/ldconfig } # Das »Hauptprogramm«... Libraries='lib*' Symbol= StartDir=./ ConfigLdd= SetLibraryPath= Path= while getopts n:s:d:lx Optionen; do case $Optionen in n) Libraries=$OPTARG;; s) Symbol=$OPTARG;; d) StartDir=$OPTARG;; l) ConfigLdd=1;; x) SetLibraryPath=1;; *) { echo "$Optionen: Unbekanntes Argument"; exit 1; } esac done test -z $Symbol && { echo "Option: '-s Symbol' erforderlich"; exit 1; } test -d $StartDir || { echo "Startverzeichnis '$StartDir' nicht gefunden"; exit 1; } for i in `find $StartDir -name "$Libraries" 2>/dev/null`; do find_symbol_in_lib $i $Symbol || continue echo "Symbol definiert in $i" Path=$(GetAbsolutePathName `dirname $i`/) done test -z $Path && { echo "Symbol wurde nicht gefunden"; exit 0; } test -z "$SetLibraryPath" || Config_LD_LIBRARY_PATH $Path test -z "$ConfigLdd" || Config_Ldd $Path |
Das Skript ist sicherlich nicht leicht zu verstehen, aber auf die bereits im obigen Text ausgiebig erwähnten Konstrukte möchte ich hier nicht erneut eingehen. Ich beschränke mich daher auf die Arbeitsweise der enthaltenen neuen Funktionen.
find_symbol_in_lib
Das Kommando file bestimmt zu den angegeben Dateinamen (1.Argument) ihren Typ (sofern bekannt). Die Ausgaben sollten bei jeder dynamischen Bibliothek den charakteristischen Text »shared object« enthalten, nach denen wir mittels Fixed grep suchen.
Allerdings hilft es nichts, wenn die Symbolinformationen aus den Bibliotheken entfernt wurden (»stripped«). Bibliotheken dieser recht seltenen Gattung filtert der zweite fgrep-Aufruf heraus.
Aus den Bibliotheken, die obige Tests bestanden, lesen wir mit Hilfe von nm die Symbolinformationen aus und suchen nach einer Zeile, die die Definition zum Symbol (2. Argument) enthält. Beachten Sie, dass der Rückgabewert einer Funktion der Status des zuletzt ausgeführten Kommandos ist!
Config_LD_LIBRARY_PATH
Als einziges Argument erhält die Funktion den Pfad, indem die Bibliothek gefunden wurde. Nun ist es denkbar, dass dieser Pfad bereits in der Variablen »LD_LIBRARY_PATH« enthalten ist. Um sicher zu stellen, dass auch etwaige Konfigurationen aus ».profile« in den nachfolgenden Schritten berücksichtigt werden, wird diese Datei nochmals eingelesen.
Den Inhalt von »LD_LIBRARY_PATH« durchsuchen wir nach dem Pfad. Problematisch ist, dass das Suchmuster (Pfad) in einer Variable steht und dieses auch noch Sonderzeichen der Bash enthält (der Slash). Noch dazu kann dieser Pfad Bestandteil eines anderen Pfades aus »LD_LIBRARY_PATH« sein. Erst der Zeichenkettenvergleich und die Möglichkeit der Angabe eines Zeilentrennzeichens von Awk gestatten die Interpretation des Musters, ohne dass die Substitutionsmechanismen der Bash in die Quere kommen.
Ist der Pfad vorhanden, ist nichts zu tun (Er muss nicht in .profile gesetzt worden sein!).
Im anderen Fall bemühen wir den Stream Editor zum Entfernen des alten LD_LIBRARY_PATH-Eintrag aus der Datei ».profile« und ergänzen die neue Version.
Config_Ldd
In der ersten Zeile testen wir, ob das Skript als Root gestartet wurde. Falls nicht, fehlen für die weiteren Schritte die notwendigen Berechtigungen und das Skript endet.
Da die einzelnen Pfadangaben in der Datei /etc/ld.so.conf auf separaten Zeilen stehen, eignet sich grep zur Suche nach dem Muster. Ist der Pfad bereits enthalten, beenden wir die Funktion.
Im anderen Fall wird der Pfad ans Ende der Datei angefügt und ldconfig gestartet, damit die von ldd verwendete Cache-Datei (ls.so.cache) neu erzeugt wird.
Linuxfibel-Druckversion
Immer wieder werde ich gefragt, warum ich keine Druckversion der Linuxfibel anbiete? Mit Bedauern gebe ich dann zu verstehen, dass ich derzeit eher Wert auf Inhalt als auf Präsentation lege und meine Zeit eh schon zu knapp bemessen ist, um ernsthaft die Vollendung der Linuxfibel voran zu treiben. Und außerdem könnte ein kleines Skript den störenden Navigationsrahmen entfernen und somit eine temporäre brauchbare Lösung schaffen.
Wer sich die Mühe macht und einige html-Quellen der Fibel betrachtet, wird bald die identische Struktur erkennen, die das Skript sich zu nutze macht, um den druckverhindernden Ballast zu entsorgen. Um gleich noch einen Lehreffekt zu erzielen, verwendet das Skript Awk für die wesentlichen Schritte. Die Awk-Programmdatei wird wiederum temporär erzeugt. Hier zunächst das Skript:
|
user@sonne> cat printversion.sh #!/bin/sh linuxfibel_base=${1:-./} awk_script=/tmp/`basename $0`.$$ trap 'test -e $awk_script && rm $awk_script' 2 15 test -d $linuxfibel_base || { echo "Verzeichnis $linuxfibel_base existiert nicht"; exit 1; }
cat > $awk_script << EOF #--------- AWK-SCRIPT BEGINN -------------- #!/usr/bin/awk -f BEGIN { DoPrint="true" IGNORECASE=1 }
if ( DoPrint == "true") { print \$0 } } #--------- AWK-SCRIPT ENDE ---------------- EOF chmod +x $awk_script for i in *.htm; do $awk_script $i > printversion/$i done kill -2 $$ |
Wiederum möchte ich mich bei der Diskussion des Skripts auf die »neuen« Aspekte konzentieren.
| awk_script=/tmp/`basename $0`.$$ |
Dass hier ein eindeutiger Name für das anzulegende Awk-Skript erzeugt wird, sollte klar sein. Weniger einleuchtend ist die Verwendung von »basename $0«. Überlegen Sie sich, wie der Name aussehen würde, wenn das Programm mit relativer oder absoluter Pfadangabe gestartet werden, »basename« aber fehlen würde...
|
Ob es sich beim aktuellen Verzeichnis tatsächlich um ein Linuxfibel-Basisverzeichnis handelt, soll anhand der Existenz einer typischen Datei (hier »vorwort.htm«) sicher gestellt werden. Die beiden folgenden Zeilen legen ein Verzeichnis zur Aufnahme der Druckversionen und in diesem einen Link auf das Bilderverzeichnis an. Natürlich nur, wenn Verzeichnis bzw. symbolischer Link nicht schon existieren...
Das Awk-Skript selbst zu besprechen, wäre hier fehl am Platze. Dessen Prinzip ist die Suche nach charakteristischen Mustern in den html-Dateien und das Ein- bzw. Ausschalten der Ausgabe der aktuell bearbeiteten Zeile. Tatsächlich funktioniert das einizg, weil alle html-Dateien eine identische Struktur und gleichartige Zeilen (HIER BEGINNT DER TEXT etc.) aufweisen. Der Programmiersprache Awk ist ein eigener Abschnitt gewidmet.
| chmod +x $awk_script for i in *.htm; do $awk_script $i > printversion/$i done kill -2 $$ |
Das Awk-Skript wird mit Ausführungsrechten versehen und in einer Schleife über alle html-Dateien aufgerufen. Das Ergebnis des Skripts landet im Verzeichnis »printversion« unter dem selben Namen wie die originale html-Datei. Zuletzt senden wir dem Shellskript selbst das Signal 2, wodurch »trap« zum Zuge kommt.
| Dialog |

|
Genug von Schwarz und Weiß? Dann bringen Sie etwas Farbe in Ihre Skripte. Natürlich vorausgesetzt, Sie sitzen nicht gerade vor einem Monochrombildschirm. Dann kann selbst dialog nicht weiter helfen.
Das Konzept der Dialogboxen ist nicht auf die Bash beschränkt. Sie können das Kommando dialog ebenso in den Skripten der csh oder ksh anwenden.
Anmerkung: Dem Paket »wvdial« liegt ein Kommando lxdialog bei, das sowohl in Syntax als auch in Wirkung exakt dem dialog entspricht. Es kennt allerdings nicht die Optionen »--msgbox«, »--textbox« und »--gauge«.
Ein kleines Beispiel
Während der kleinen Fingerübung (Erwärmung) lernten Sie ein Skript zum komfortablen Löschen von (unnützen) Dateien kennen. Die Art der zu löschenden Dateien musste per Kommandozeilenargument spezifiziert werden. In Zeiten grafischer Oberflächen würde etwas mehr Komfort kaum schaden. Das nachfolgende Programm bettet das schon bekannte Skript in Dialogboxen ein:
| user@sonne> cat
delete_trash_dialog #!/bin/sh trap 'rm /tmp/tmp.$$; exit 0' 2 15 object= tilde= core= inter= dialog --clear --title "$0" --checklist \ 'Dateisystem-Reinigung' 10 70 4 \ '1' 'Core-Dateien' off \ '2' 'Objekt-Dateien' off \ '3' 'Backup-Dateien' off \ '4' 'Nachfrage vor jedem Loeschen?' on 2> ~/tmp.$$ options=$(cat ~/tmp.$$) rm ~/tmp.$$ for i in $options; do case "$i" in \"1\" ) core=core;; \"2\" ) object=.o;; \"3\" ) tilde=\~;; \"4\" ) inter=1;; esac done for i in $core $object $tilde; do for x in $(find $(pwd) -name "*$i"); do if [ $inter ]; then dialog --backtitle "Eine Bestätigung des Dialogs entfernt eine Datei unwiderruflich!" --yesno "Removing $x?" 6 70 if [ $? = 0 ]; then rm $x fi else dialog --infobox "Removing $x" 5 70 rm $x fi done done |
Die folgende Abbildung zeigt den Dialog, der die Abfrage zu löschender Dateien vornimmt. Im Programm zeichnen die Zeilen "dialog --checklist..." dafür verantwortlich:

Abbildung 1: dialog --checkbox
Im Falle des interaktiven Löschens erfolgt für jede einzelne Datei eine Abfrage. Die Option "--yesno" des Kommandos dialog wurde hierbei benutzt:
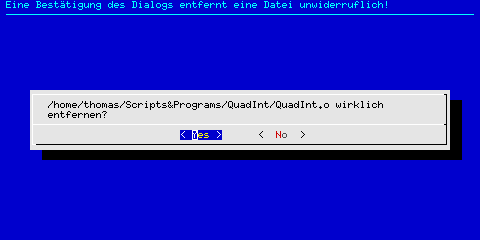
Abbildung 2: dialog --yesno
Die Optionen des Kommandos dialog
Welche Dialogart dialog darstellen soll, wird durch Optionen gesteuert. »Höhe« ist gleich bedeutend mit »Anzahl Zeilen« und »Breite« mit »Anzahl Spalten«.
--backtitle <Text>
In der linken oberen Ecke des blauen Hintergrunds wird der Text eingeblendet (siehe yesno-Dialog im einführenden Beispiel).
--checklist <Text> <Höhe> <Breite> <Listenhöhe> <Tag1> <Eintrag1> <Status1>...
Der »Text« wird oberhalb der Auswahlliste eingeblendet. Ein »Tag« ist eine (eindeutige) Kennzeichnung für einen Eintrag. Ist das jeweils erste Zeichen der Tags eindeutig, kann später über die Taste der Eintrag direkt angesprungen werden. »Eintrag« ist ein beschreibender Text. »Status« kann »on« oder »off« sein, je nachdem, ob die Option in der Voreinstellung gesetzt sein soll oder nicht. Die Anwendung eines checklist-Dialogs zeigt das einführende Beispiel.
--clear
Der Bildschirm wird nach Dialogende gelöscht.
--create-rc <Datei>
In den Beispielen in diesem Abschnitt wird für die Darstellung der Dialogboxen stets die Standardeinstellung gewählt. Diese können durch eine Datei .dialogrc im Heimatverzeichnis eines Benutzers überschrieben werden. Mit dem Aufruf:
| user@sonne> dialog --create-rc
.dialogrc user@sonne> head -15 .dialogrc # # Run-time configuration file for dialog # # Automatically generated by "dialog --create-rc <file>" # # Types of values: # # Number - <number> # String - "string" # Boolean - <ON|OFF> # Attribute - (foreground,background,highlight?) # # Shadow dialog boxes? This also turns on color. use_shadow = ON |
lässt sich eine solche Datei erzeugen und per Editor modifizieren. Die enthaltenen Kommentare sind recht ausführlich und sollten schnell zu einem eigenen Layout führen.
--gauge <Text> <Höhe> <Breite> <Prozent>
Mit dieser Dialogform kann eine Fortschrittsanzeige erzeugt werden. Text wird oberhalb des Fortschrittbalkens eingeblendet. Der Startwert des Balkens, sowohl die der zusätzlichen prozentualen Angabe als Klartext, wird durch Prozent spezifiziert. Zur Aktualisierung der Anzeige erwartet der Dialog die weiteren Werte auf der Standardeingabe. Erst wenn dort End Of File erscheint, ist die Arbeit des Dialogs beendet. Das Simulieren der Eingabe innerhalb eines Skripts erfordert einige Kopfstände und geht am einfachsten durch Umleitung der Ausgabe. Im anschließenden Beispiel finden Sie eine Anwendung des gauge-Dialogs.
--infobox <Text> <Höhe> <Breite>
Analog zu --msgbox dient dieser Dialog der Anzeige eines Textes. Der Dialog wird unverzüglich - ohne Bestätigung durch den Benutzer - beendet. Er wird erst durch das umgebende Shellskript gelöscht, allerdings führen verschiedene Terminal-Einstellungen zum sofortigen Entfernen des Dialogs.
--inputbox <Text> <Höhe> <Breite> [<Init>]
In der Eingabebox können Nutzereingaben erfolgen. Text wird dabei oberhalb des Eingabefeldes angezeigt. Optional lässt sich die Box mit einem Text vorbelegen. Im anschließenden Beispiel finden Sie Beispiele zu Verwendung dieser Dialogbox.
--menu <Text> <Höhe> <Breite> <Menühöhe> <Tag1> <Eintrag1>...
Der Menüdialog ermöglicht die Auswahl aus einem der dargebotenen Einträge. Text wird dabei oberhalb der Auswahlbox platziert. Sie sollten unbedingt darauf achten, dass die Breite des längsten Menüeintrags die Breite der Box nicht übersteigt, da der Überschuss dann einfach abgeschnitten wird. Die (Menü)Höhe spielt nur rein optisch eine Rolle, da in vertikale Richtung gescrollt werden kann. Bei Abschluss des Dialog über »OK« wird der Text des selektierten Eintrags auf die Standardfehlerausgabe geschrieben. Ein Beipiel finden Sie im anschließenden Skript.
--msgbox <Text> <Höhe> <Breite>
Mit einer Nachrichtenbox geben Sie beliebigen Text aus, den der Benutzer mit "OK" bestätigen muss. Dieser Dialog erzeugt keinen Rückgabewert:
| user@sonne> dialog --msgbox "Die nachfolgenden Aktionen könnten etwas dauern. Verlieren Sie bloß nicht die Geduld..." 6 52 |
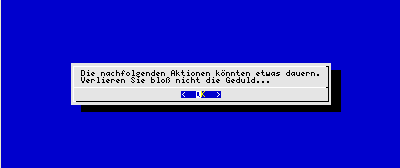
Abbildung 3: dialog --msgbox
--textbox <Datei> <Höhe> <Breite>
Die angegebene Datei wird in einer Box der angegebenen Höhe und Breite
angezeigt. Enthält der Text mehr Zeilen oder Spalten, kann mittels der
Tasten  ,
,  , und der darzustellende Textausschnitt verschoben
werden (angewendet wird eine Textbox im nachfolgenden Beispiel).
, und der darzustellende Textausschnitt verschoben
werden (angewendet wird eine Textbox im nachfolgenden Beispiel).
--title <Text>
Der Text wird zentriert in der oberen Begrenzungslinie eines Dialogs eingeblendet (siehe checklist-Dialog des einführenden Beispiels).
--radiolist <Text> <Höhe> <Breite> <Listenhöhe> <Tag1> <Eintrag1> <Status1>...
radiolist ermöglicht die Auswahl einer Option aus einer Liste. »Tag« sollte dabei einen Eintrag eindeutig kennzeichnen, um mittels der Tastatur diesen anwählen zu können. »Status« kann »on« oder »off« sein, je nachdem, ob der Eintrag in der Voreinstellung selektiert sein soll oder nicht. Es sollte maximal ein einziger Eintrag den Status »on« tragen! Der »Tag« des selektierten Eintrags wird bei Dialogende mittels »OK« auf die Standardfehlerausgabe geschrieben:
| dialog --clear --radiolist "Demonstration" 10 50 4 \ "a" "Option 1" off \ "b" "Option 2" off \ "c" "Option 3" off \ "d" "Option 4" on 2>/tmp/tmp.$$ |
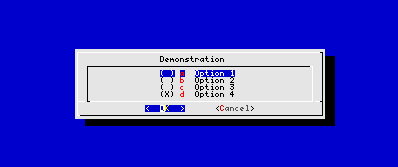
Abbildung 4: dialog --radiolist
--yesno <Text> <Höhe> <Breite>
Der angegebene Text muss durch »ja« oder »nein« bestätigt werden. Bei Auswahl von »ja« gibt der Dialog "0" zurück, sonst »1« (die Anwendung wurde im einführenden Beispiel demonstriert).
Eine komplexere Anwendung
Wohl jeder ist schon einmal in den Genuss gekommen, die verschiedensten Dateien zu durchsuchen, um heraus zu finden, wo denn nun eine bestimmte Variable gesetzt oder ein konkretes Kommando konsultiert wird.
Als Werkzeuge sollten dem Leser sofort find zur Suche nach den Dateien und grep zum Aufspüren des Zeichenmusters in den Sinn gelangen. Je nach Wahl der Optionen lassen sich somit entweder die Zeile mit dem gefundenen Muster oder der Name der Datei, die das Muster enthielt, darstellen. Nicht jedoch die gesamte Datei (genau genommen lassen sich diese in einen Pager pipen, wobei noch immer kein wahlfreier Zugriff gewährleistet ist)...
Erst durch Anwendung der Möglichkeiten von dialog wird eine systematische Suche in »verdächtigen Dateien« möglich. Betrachten Sie zunächst den vollständigen Kode des Skripts. Sie werden viele Konzepte wiederfinden, die im Laufe dieses Abschnitts vorgestellt wurden. Im Anschluss finden Sie Anmerkungen zum Gebrauch der einzelnen Dialog-Elemente:
| user@sonne> cat grep_and_list #!/bin/sh # Standardfehlerausgabe abschalten: exec 2>&- # Signale 2 und 15 abfangen und mit Aufräumarbeiten behandeln trap 'rm /tmp/tmp{1,2,3,4,5,6,7}.$$; clear; exit 0' 2 15 while :; do dialog --clear --title "Dialog Grep" \ --inputbox "Zu suchender Text:" 10 50 \ 2>/tmp/tmp1.$$ Muster=`cat /tmp/tmp1.$$` test -z $Muster || break done while :; do dialog --clear --title "Dialog Grep" \ --inputbox "Startverzeichnis:" 10 50 \ 2>/tmp/tmp2.$$ Startverzeichnis=`cat /tmp/tmp2.$$` test -d $Startverzeichnis && break done dialog --clear --checklist "Suche" 10 60 2\ "1" "Rekursiv in Unterverzeichnissen" off \ "2" "Beachte Klein- und Großschreibung" off \ 2>/tmp/tmp3.$$ maxdepth="-maxdepth 1" ignorecase="-i" for i in `cat /tmp/tmp3.$$`; do case "$i" in \"1\" ) maxdepth= ;; \"2\" ) ignorecase= ;; esac done declare -i Anzahl=`find $Startverzeichnis $maxdepth -type f | tee /tmp/tmp4.$$ | wc -l` declare -i Bearbeitet=0 Dateiliste=`cat /tmp/tmp4.$$` { for i in $Dateiliste; do Bearbeitet=$Bearbeitet+1 echo $(($Bearbeitet * 100 / $Anzahl)) grep $ignorecase -q $Muster $i && echo $i >> /tmp/tmp5.$$ done } | dialog --gauge "Durchsuche Dateien..." 6 40 0 ErgebnisListe=`cat /tmp/tmp5.$$` echo "dialog --clear --title 'Gefundene Dateien' \\" > /tmp/tmp6.$$ echo " --menu 'Auswahl' 15 60 10 \\" >> /tmp/tmp6.$$ for i in $ErgebnisListe; do echo "\"$i\" \"Betrachten\" \\" >>/tmp/tmp6.$$ done echo "\"[Ende]\" \"Programm Ende\" 2>/tmp/tmp7.$$" >>/tmp/tmp6.$$ while :; do bash /tmp/tmp6.$$ Ergebnis=`cat /tmp/tmp7.$$` test "$Ergebnis" == "[Ende]" -o ! -s /tmp/tmp7.$$ && break dialog --clear --textbox $Ergebnis 20 70 done # Aufräumen erzwingen: kill -INT $$ |
Die beiden ersten Anwendungen von dialog im Skript betreffen Eingabeboxen (--inputbox), mit denen der zu suchende Text und das Startverzeichnis anzugeben sind:
| while :; do dialog --clear --title "Dialog Grep" \ --inputbox "Zu suchender Text:" 10 50 \ 2>/tmp/tmp1.$$ Muster=`cat /tmp/tmp1.$$` test -z $Muster || break done |
Wird ein solcher Dialog mit »OK« beendet, schreibt dialog den eingegebenen Text auf die Standardfehlerausgabe. Im Skript wird diese in eine Datei umgeleitet. Deren Inhalt versuchen wir in eine Variable »Muster« zu lesen, die wir anschließend testen. Ist sie leer, wird erneut zur Eingabe aufgefordert. Die folgende Abbildung zeigt den Eingabedialog:
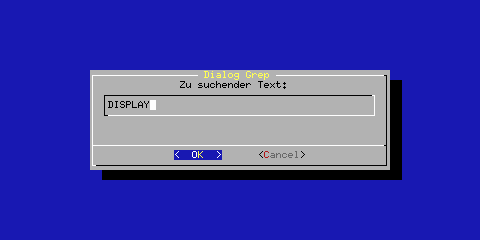
Abbildung 5:dialog --inputbox
Im nachfolgend dargestellten Eingabedialog wird analog verfahren. Einziger Unterschied ist, dass die Variable »Startverzeichnis« dahin gehend getestet wird, dass der gespeicherte Inhalt tatsächlich ein existierendes Verzeichnis beschreibt.
| while :; do dialog --clear --title "Dialog Grep" \ --inputbox "Startverzeichnis:" 10 50 \ 2>/tmp/tmp2.$$ Startverzeichnis=`cat /tmp/tmp2.$$` test -d $Startverzeichnis && break done |
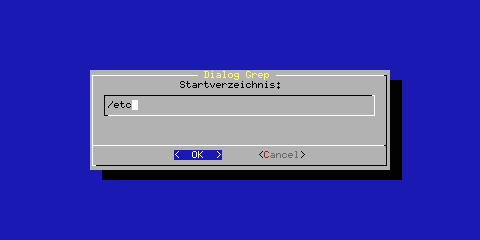
Abbildung 6: dialog --inputbox
Eine Auswahlliste wird benutzt, um die Suche wahlweise auf Unterverzeichnisse auszudehnen bzw. die Schreibweise des Musters zu beachten. Wiederum wird die Auswahl beim Schließen des Dialogs über »OK« auf die Standardausgabe geschrieben, die im Skript in eine Datei umgeleitet wird.
| dialog --clear --checklist "Suche" 10
60 2\ "1" "Rekursiv in Unterverzeichnissen" off \ "2" "Beachte Klein- und Großschreibung" off \ 2>/tmp/tmp3.$$ |
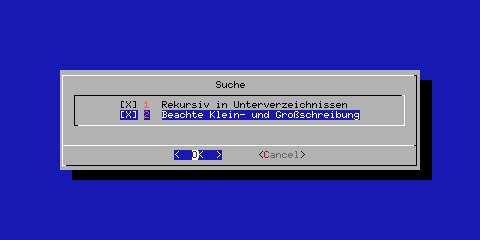
Abbildung 7: dialog --checkbox
Die Auswertung der markierten Boxen des letzten Dialogs und die anschließende Suche nach den Dateien sollten ansich leicht verständlich sein. Die komplex anmutenden Quelltextzeilen resultieren aus den Bestrebungen, die häufig langwierige Suche durch grep mittels einer Fortschrittsanzeige zu visualisieren.
| { for i in $Dateiliste; do Bearbeitet=$Bearbeitet+1 echo $(($Bearbeitet * 100 / $Anzahl)) grep $ignorecase -q $Muster $i && echo $i >> /tmp/tmp5.$$ done } | dialog --gauge "Durchsuche Dateien..." 6 40 0 |
Vor der Schleife ermittelten wir die Anzahl der durch find aufgespürten Dateien. In der Schleife nun ermitteln wir aus diesem Wert und dem gerade bearbeiteten Eintrag der Dateiliste den prozentualen Stand der Bearbeitung. Durch die Klammerung der gesamten Schleife erzeugen alle enthaltenen Kommandos eine einzige Ausgabe, die wir nun dem Kommando dialog über eine Pipe zuführen.

Abbildung 8: dialog --gauge
Was nun kommt, ist eine reichlich trickreiche Anwendung der Ausgabeumleitung:
| echo "dialog --clear --title 'Gefundene
Dateien' \\" > /tmp/tmp6.$$ echo " --menu 'Auswahl' 15 60 10 \\" >> /tmp/tmp6.$$ for i in $ErgebnisListe; do echo "\"$i\" \"Betrachten\" \\" >>/tmp/tmp6.$$ done echo "\"[Ende]\" \"Programm Ende\" 2>/tmp/tmp7.$$" >>/tmp/tmp6.$$ |
Dem Kommando dialog muss man ganz genau sagen, was es darzustellen hat. Dynamisch einen Eintrag hinzuzuschummeln, wird das Kommando eiskalt ignorieren. Wie also sollte man einen Dialog mit den soeben erzielten Ergebnissen erzeugen?
Indem man die Skriptdatei dynamisch generiert. Die beiden ersten echo-Aufrufe des obigen Programmfragments schreiben den dialog-Kopf in eine temporäre Datei. In einer Schleife werden nachfolgend die einzelnen Einträge, bestehend aus dem Dateinamen und dem Wort »Betrachten«, hinzugefügt. Ein weiterer Eintrag »[Ende]« ermöglicht später das Verlassen des Dialogs. Das Ergebnis der Dialogabfrage landet wiederum in einer Datei.
| while :; do bash /tmp/tmp6.$$ Ergebnis=`cat /tmp/tmp7.$$` test "$Ergebnis" == "[Ende]" -o ! -s /tmp/tmp7.$$ && break dialog --clear --textbox $Ergebnis 20 70 done |
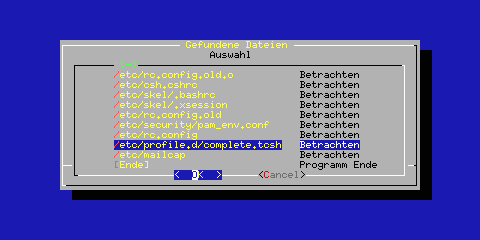
Abbildung 9: dialog --menu
Das »Kernstück« des Skripts besteht aus einer while-Schleife, in der immer wieder die soeben dynamisch erzeugte Datei mit dem »dialog --menu«-Aufruf in der Bash ausgeführt wird. Liefert der Dialog als Rückgabe »[Ende]«, wird die Schleife und somit - im übernächsten Schritt das Programm - verlassen. Jedes andere Dialog-Ergebnis muss der Name einer das Suchmuster enthaltenden Datei sein, die in einer Textbox dargestellt wird:
Abbildung 10: dialog --textbox

 Korrekturen, Hinweise?
Korrekturen, Hinweise?