

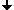
Network File System - Server |
| Übersicht |
|
Dieser Abschnitt basiert auf Recherchen von Bernd Reimann. Herzlichen Dank an ihn für die Zusammenarbeit!
Bevor wir uns dem Schwerpunkt der Administration eines NFS-Servers zuwenden, sollen kurze Betrachtungen zur Vergangenheit, Gegenwart und Zukunft der NFS-Entwicklung unter Linux etwas Hintergrundwissen vermitteln...
Bereits 1984, also lange bevor Linus Torvalds auch nur annähernd an Linux dachte und die Computerwelt noch von den Mainframes regiert wurde, widmete sich das Unternehmen SUN Microsystems der Aufgabe, ein System zu entwickeln, das den transparenten Zugriff auf die auf entfernten Rechnern liegenden Daten und Programme ermöglichen konnte.
Nahezu ein Jahr nach dieser Ankündigung (1985) stellte SUN NFS Version 2 (NFS V2) der Öffentlichkeit vor. Das Herausragende dieser Präsentation waren jedoch nicht die technischen Finessen, die das System mit sich bringen würde, sondern die Veröffentlichung der Spezifikation ansich. SUN durchbrach zum ersten Mal die Heiligkeit der Geheimhaltung solcher Interna und ebnete damit auch unwillkürlich den Siegeszug von NFS.
SUN stellte allen interessierten Firmen die Entwicklungsergebnisse als Lizenz zur Verfügung und ermöglichte somit einen de-facto-Standard in der UNIX-Welt, der sich bis heute durchgesetzt hat und immer noch eine der erfolgreichsten UNIX-Technologien darstellt. Nach und nach wurde NFS auf weitere Plattformen wie System V, BSD, AIX, HP-UX und später auch Linux portiert, wo NFS zur Standardausstattung einer jeden Distribution gehört. Selbst viele Nicht-Unix-Systeme, die es zu einer gewissen Verbreitung gebracht haben, warten mit einer NFS-kompatiblen Implementierung auf.
1991 veröffentlichte SUNSoft, eine Tochtergesellschaft von SUN, erstmals eine komplette Sammlung zusammenwirkender Protokolle namens ONC (Open Network Computing), in der alle Bestandteile der Netzwerkkommunikation vom Zugriff auf die Netzwerkhardware bis hin zu Netzwerkanwendungen integriert wurden. Der NFS-Dienst ist Teil dieser ONC-Protokoll-Suite (Abbildung 1) und vertritt dort die Anwendungsebene, d.h. mit dem NFS-Dienst wird direkt gearbeitet.
Abbildung 1: Vergleich verbreiteter Protokollstacks
Wie auch das OSI-Modell hat sich die ONC-Protokollsuite als Schema in der Praxis nicht durchgesetzt, auch wenn Protokolle wie XDR (External Data Representation) und der Remote Procedure Call (RPC) untrennbar mit dem NFS-Dienst einhergehen. XDR dient der Konvertierung der zu übermittelnden Daten in ein standardisiertes Format. Dies ist notwendig, da das NFS-Protokoll nicht auf ein System und eine Hardware-Plattform beschränkt ist und unterschiedliche Systeme und Hardware mitunter unterschiedliche Darstellungen der Daten praktizieren.
Hinter dem »Entfernten-Prozedur-Aufruf« (RPC) steckt die Idee, dass Programme auf Funktionen zurückgreifen, die nicht zwingend auf dem gleichen Rechner erbracht werden, wobei sich der Funktionsaufruf aus Sicht des Programms nicht von einem »normalen« lokalen Funktionsaufruf unterscheidet. Der interessierte Leser findet im Abschnitt Remote Procedure Call des Kapitels »Netzwerk-Grundlagen« eine umfassende Diskussion der Mechanismen und Probleme des RPCs.
Auf der Anwendungsebene tummelt sich nicht nur der NFS-Dienst selbst, sondern auch noch (verwandte) Protokolle wie das Mount-Protokoll, der Netzwerk-Lock-Manager (NLM) und der Netzwerk-Status-Monitor (NSM). Das Mount-Protokoll ist für den »Einhängevorgang« des Dateisystems zuständig, ein konkretes Beispiel des doch recht komplexen Vorgangs folgt zu einem späteren Zeitpunkt. NLM und NSM ermöglichen den exklusiven Zugriff auf Dateien über Rechnergrenzen hinweg. Beide Dienste sind für den Betrieb von NFS nicht zwingend erforderlich, ob Sie sie benötigen, erfahren Sie im Abschnitt Interna.
Wer mit der Materie wenig vertraut ist, wird womöglich zum ersten Mal mit beiden Begriffen konfrontiert sein. Eigentlich erübrigt sich eine Diskussion über Vor- und Nachteile, hat sich doch der kernel-basierte Serverdienst gegenüber der alteingesessenen Implementierung als im Nutzeradressraum tätiger Serverprozess eindeutig durchgesetzt. Und dennoch verlangt eine umfassende Betrachtung einen tieferen Blick hinter die Kulissen.
Der so genannte User-Space NFS Server, wie er vor wenigen Jahren noch jeder Linux-Distribution beilag, zeichnet sich vor allem durch eine einfach zu realisierende Implementierung aus. Allein die Tatsache, dass ein Client dieselbe Sicht auf ein gemountetes Dateisystem hat, wie auch der Server, ermöglicht ein simples Mapping von lokalen Gruppen- und Benutzeridentifikationen (gid, uid) auf die vom importierten Dateisystem verwendeten Nummern. Dem User-Space-NFS-Server stand hierzu ein Rpc-Dienst (rpc.ugidd) zur Seite, der anhand einer Tabelle die Umsetzung der Benutzeridentifikationen vornahm. Nicht zuletzt aus Sicherheitsgründen unterstützt der neue Kernel-NFS-Server nur eine stark eingeschränkte Variante dieses Verfahrens (vergleiche Squashing).
Wenn der kernel-basierte Server so aufwändig zu implementieren ist, warum hat man es nicht beim User-Space NFS Server belassen? Im Großen und Ganzen führen alle Überlegungen auf einen Grund zurück: Im Kernel arbeitet der Server entschieden schneller!. Der alte User-Space-NFS-Server kannte kein Threading (vereinfacht ausgedrückt, kann ein thread-basiertes Programm mehrere Aufgaben quasi gleichzeitig verrichten). Dieses Manko hätte eine Reimplementierung sicher noch behoben, aber auf Grund der strikten Schutzmechanismen im Betriebssystem bleiben dem Kernel-Server etliche Kopieroperationen erspart, da er bspw. die Berechtigung besitzt, Daten direkt in den Speicherbereich der Netzwerkkarte zu befördern. Ein Server im Nutzeradressraum müsste hierzu erst den Kernel bemühen, was allein schon einen Taskwechsel - und damit Zeit - bedingt. Weitere Unzulänglichkeiten sind die fehlende Unterstützung für NLM (Network Lock Manager) und NSM (Network Status Monitor) sowie die leidige Beschränkung der Dateigröße auf 2GB.
Die Vorteile des Kernel-Space NFS Servers liegen neben dem Geschwindigkeitsgewinn in dessen erweitertem Funktionsumfang. So beherrscht er mittels der NLM und NSM Protkolle das Setzen von Dateisperren auf exportierten Verzeichnissen. Und da die Überwachung der exports-Datei als Systemruf implementiert ist, müssen Server und Mountd nicht explizit über Änderungen unterrichtet werden. Die (theoretische) Beschränkung der Dateigröße liegt nun bei 263 Bits.
Leider besitzt auch die Kernelrealisierung noch eine Schwäche. So werden Dateisysteme, die sich unterhalb eines exportierten Verzeichnisses befinden, nicht automatisch exportiert (bis auf einen Fall; siehe später). Für diese wird ein extra Eintrag in der exports-Datei und damit clientseitig ein weiterer Mountvorgang notwendig.
So komplex obige Ausführungen auch anmuten mögen, aus Sicht des Administrators bestehen bez. der Einrichtung von NFS keinerlei Unterschiede zwischen User- und Kernel-Space NFS.
Im kurzen historischen Abriss war von NFS Version 2 die Rede. Version 3 ist seit Jahren existent und an Version 4 wird gestrickt. Die aktuellen NFS-Server (Kernelversionen ab 2.2.19) unterstützen alle Forderungen der Version 2 und bereits wesentliche Teile von Version 3. Die letzte »Hürde« (NFS via TCP) zur vollständigen Umsetzung von Version-3-Funktionalität ist als experimenteller Patch (ab Kernel 2.4.19) bereits genommen, die stabile Version ist somit nur noch eine Frage der Zeit. Auch Entwicklungen zur Umsetzung von NFS der 4. Version sind angelaufen.
| Schritte zum Serverstart |
|
Da eine Kommunikation zwischen zwei Rechnern über sogenannte Sockets läuft, also die IP-Adresse und die zugehörige Portnummer eines Dienstes, muss natürlich der Client, der seine Anfrage an den Server richtet, auch diese Portnummer kennen. Auf Grund der Fülle existenter RPC-Dienste werden Portnummern für diese nicht mehr strikt statisch vergeben, sondern über einen zusätzlichen Dienst - den Portmapper oder auch RPC-Bind (SUN) genannt - verwaltet. Der Portmapper selbst lauscht an einem festgelegten Port (111 sowohl über UDP als auch TCP).
Dieser Portmapper ist in den meisten Distributionen standardmäßig installiert und wird oft durch ein Init-Skript in den Netzwerk-Runleveln beim Booten des Systems gestartet. Wird der Portmapper nur selten benötigt, spricht nichts gegen einen automatischen Start bei Bedarf durch den [x]inet-Daemonen.
Der Portmapper verwaltet eine Art kleine Datenbank, in der er verschiedene Informationen zu allen auf dem System aktiven RPC-Diensten hält. Ein RPC-Dienst muss sich deshalb beim Start beim Portmapper registrieren und ihm u.a. die von ihm verwendete Portnummer mitteilen. Bei Anfragen eines RPC-Clients an den Portmapper nach einem konkreten RPC-Dienst (PMAPPROC_GETPORT()), durchsucht dieser seine Datenbasis und übergibt, falls der Dienst verfügbar ist, dessen Portnummer. Alle Clientzugriffe erfolgen später direkt an diesen Port (also unter Umgehung des Portmappers; Abbildung 2).
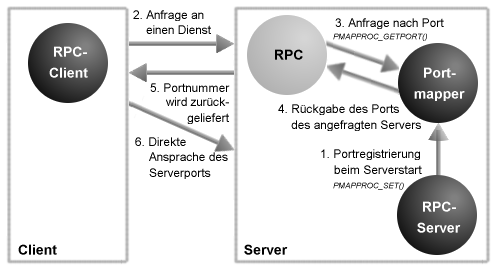
Abbildung 2: Kontaktaufnahme des Clients zum Server
Der Zugang zu fast jedem RPC-Dienst unter Linux wird in aktuellen Programmversionen durch die Konfigurationen der Dateien /etc/hosts.allow und /etc/hosts.deny geregelt. Sie können leicht feststellen, ob die Dateien für ein Programm relevant sind:
|
# Wertet 'rpc.mountd' die Dateien hosts.allow und hosts.deny aus? user@sonne> strings /usr/sbin/rpc.mountd | grep hosts hosts_access_verbose hosts_allow_table hosts_deny_table /etc/hosts.allow /etc/hosts.deny @(#) hosts_ctl.c 1.4 94/12/28 17:42:27 @(#) hosts_access.c 1.21 97/02/12 02:13:22 |
Insofern ein Dienst nicht in einer der Dateien »hosts.allow« bzw. »hosts.deny« aufgeführt ist, ist der Zugang zu diesem gewährt. In der Datei »hosts.allow« kann der Zugang explizit erlaubt und in »hosts.deny« verboten werden, wobei bei widersprüchlichen Einträgen in beiden Dateien die Angaben aus »hosts.allow« gelten.
In sicherheitskritischem Umfeld ist es nicht ungewöhnlich, zunächst pauschal sämtliche Dienste in »hosts.deny« zu sperren, um die wirklich benötigen in »hosts.allow« explizit für auserwählte Rechner zuzulassen. Bez. der auf einem NFS-Server notwendigen Dienste, wären folgende Einträge in die Dateien erforderlich, um den Zugriff für Rechner des lokalen Netzwerks (192.168.100.0) zuzulassen:
|
root@sonne> vi /etc/hosts.deny # Alles verbieten ALL : ALL root@sonne> vi /etc/hosts.allow # Alle für NFS notwendigen Dienste für die lokale Domain freigeben: portmap : 192.168.100.0/255.255.255.0 mountd : 192.168.100.0/255.255.255.0 lockd : 192.168.100.0/255.255.255.0 statd : 192.168.100.0/255.255.255.0 rquotad : 192.168.100.0/255.255.255.0 |
Die Namen der einzelnen Dienste könnten auf Ihrem System von denen im Beispiel abweichen. Im Zweifelsfall sollten Sie nach der Registrierung der RPC-Dienste beim Portmapper die Namen der Ausgabe von »/usr/sbin/rpcinfo -p« entnehmen (mehr Informationen dazu im weiteren Text). »lockd« und »statd« sind einzig erforderlich, wenn Programme auf dem Client mit Dateisperren arbeiten (vergleiche Anmerkungen in der Einleitung); der RPC-Dienst »rquotad« ist notwendig, wenn auf den exportierten Verzeichnissen Quotas Verwendung finden.
Vergewissern Sie sich zunächst, dass der Portmapper auf Ihrem System aktiv ist. Dies kann entweder über die Statusabfrage des Runlevelskripts (falls ein solches existiert) erfolgen oder durch Suche in der Ausgabe des Kommandos ps:
|
# Abfrage über Runlevelskript (dessen Name kann auf Ihrem System abweichend lauten!) root@sonne> /etc/init.d/portmap status Checking for RPC portmap daemon: running # Abfrage mittels ps user@sonne> ps ax | grep portmap 399 ? S 0:00 /sbin/portmap 1578 pts/3 S 0:00 grep portmap |
Ist der Portmapper inaktiv, dann starten Sie ihn entweder über das Runlevelskript oder per Hand:
|
# Start über Runlevelskript (dessen Name kann auf Ihrem System abweichend lauten!) root@sonne> /etc/init.d/portmap start Starting RPC portmap daemon done # Start per Hand root@sonne> /sbin/portmap |
In den aktuellen Distributionen erledigt den Start des NFS-Servers und aller weiteren notwendigen Dienste ein Skript, bei SuSE ist dies bspw. »/etc/init.d/nfsserver«:
|
# NFS-Serverstart bei SuSE root@sonne> /etc/init.d/nfsserver start Starting kernel based NFS server done |
Existiert kein solches Skipt, müssen Sie die Dienste per Hand aktivieren:
|
root@sonne> /sbin/rpc.statd root@sonne> /sbin/rpc.lockd root@sonne> /usr/sbin/rpc.mountd root@sonne> /usr/sbin/rpc.nfsd root@sonne> /usr/sbin/rpc.rquotad |
Die Dienste »/sbin/rpc.statd« und »/sbin/rpc.lockd« bzw. »/sbin/rpc.rquotad« sind nicht zwingend notwendig (siehe Anmerkungen in der Einleitung und unter Interna).
Vom erfolgreichen Registrieren der RPC-Dienste beim Portmapper können Sie sich durch einen Aufruf von »rpcinfo« überzeugen. In Verbindung mit der Option »-p« erfahren Sie, welche Dienste mit welchen internen Daten aktuell verwaltet werden:
|
user@sonne> rpcinfo -p Program Vers Proto Port 100000 2 tcp 111 portmapper 100000 2 udp 111 portmapper 100021 1 udp 1024 nlockmgr 100021 3 udp 1024 nlockmgr 100024 1 udp 1025 status 100024 1 tcp 1024 status 100011 1 udp 969 rquotad 100011 2 udp 969 rquotad 100005 1 udp 1033 mountd 100005 1 tcp 1025 mountd 100005 2 udp 1033 mountd 100005 2 tcp 1025 mountd 100003 2 udp 2049 nfs |
Die Ausgaben könnten auf Ihrem System durchaus von obigem Beispiel abweichen, so sind abweichende Portnummern oder ähnliche Namen für die Dienste ebensowenig Besorgnis erregend, wie mehrfaches Auftauchen eines RPC-Dienstes in der Tabelle, da in vielen Konfigurationen aus Effizienzgründen gleich mehrere Instanzen eines Dienstes aktiviert werden.
| Verzeichnisexport |
|
Bevor ein Client ein Verzeichnis vom Server importieren kann, muss dieser dieses explizit mit den erforderlichen Rechten exportieren. Der Export eines Verzeichnisses erfolgt mit dem Kommando exportfs (das Kommando existiert nur in Zusammenhang mit dem Kernel-NFS):
|
/usr/sbin/exportfs [-avi] [-o Mountoptionen,..] [Client:/Pfad..] /usr/sbin/exportfs [-av] -u [Client:/Pfad..] /usr/sbin/exportfs -r [-v] |
Der Export von Verzeichnissen mittels »exportfs« ist zumeist nur in der Testphase des NFS-Servers oder bei einmaliger Freigabe eines Verzeichnisses erforderlich. »exportfs« wird hauptsächlich genutzt, um nach Änderungen in der Datei »/etc/exports« den Server (genauer: rpc.nfsd und rpc.mountd) zu instruieren, seine Konfiguration neu einzulesen. Bei den Mountoptionen des Kommandos handelt es sich um eben diese, die anschließend in Zusammenhang mit der Datei »/etc/exports« vorgestellt werden; an dieser Stelle verzichten wir auf ihre Diskussion und veranlassen in einem ersten Beispiel den NFS-Server, das Verzeichnis »/home/user« für den Rechner »venus« freizugeben:
| root@sonne> exportfs venus.galaxis.de:/home/user |
Prinzipiell können Sie für die Rechnernamen dieselbe Syntax wie in »/etc/exports« verwenden; vergessen Sie jedoch nicht, enthaltene Sonderzeichen vor Interpretation durch die Shell zu schützen. Wird - wie im Beispiel - auf Mountoptionen verzichtet, gelten async, ro, root_squash, secure (Erklärung im Anschluss).
Um das Verzeichnis vom Export wieder auszuschließen, ist die Option »-u« dienlich:
| root@sonne> exportfs -u venus.galaxis.de:/home/user |
Die Option »-a« exportiert alle (auf der Kommandozeile und in /etc/exports angegebenen) Verzeichnisse; in Zusammenhang mit »-u« werden sämtliche exportierten Verzeichnisse vom Export ausgeschlossen. Um in solchen Fällen die Auswertung der Datei »/etc/exports« zu verhindern, dient »-i«. Schließlich synchronisiert die Option »-r« die aktuelle Datenbasis des NFS-Servers (/var/lib/nfs/xtab) mit den Einträgen der Datei »/etc/exports«.
Nach Änderungen in der Datei »/etc/exports« führt folgender exportfs-Aufruf zu einer Aktualisierung beim Server:
| root@sonne> exportfs -ra |
Anmerkung: Beim älteren User-Space-NFS-Server gelingt der Export von Verzeichnissen einzig über Einträge in der Datei »/etc/exports«. Anschließend muss dem Serverprozess das Signal SIGHUP gesendet werden (kill -HUP <Prozess-ID des Servers>).
Anstatt Dateisysteme einzeln via »exportfs« zu exportieren, wird die Konfiguration mittels der Datei »/etc/exports« bevorzugt (...und in Verbindung mit dem User-Space-NFS-Server ist dies die einzige Möglichkeit der Konfiguration).
Der Aufbau eines Eintrags in die Datei ist einfach:
| Verzeichnis Client[(Mountoption,...)] [Client[(Mountoption,...)] ] |
Verzeichnis bezeichnet das zu exportierende Verzeichnis. Es folgt eine Liste der Client-Rechner, die zum Importieren dieses Verzeichnisses befugt sind. Optional kann der Zugriff auf die Daten für einen Client gegenüber der Voreinstellung (async, ro, root_squash, secure) weiter eingeschränkt oder auch gelockert werden.
Die Syntax für Client ist etwas weiter gefasst. Hier sind nicht nur die Angabe starrer Rechnernamen gestattet, sondern ebenso die Bezeichnung von Netzgruppen (die in der Datei /etc/netgroup definiert sein müssen) oder die Verwendung von Wildcards zur Definition von Mustern. Damit ergeben sich folgende Varianten zur Angabe:
erde.galaxis.de
@Gateways
*.galaxis.de
192.168.100.0/255.255.255.0
192.168.100.0/22
Jeder Angabe eines Clients kann eine Liste vom Optionen folgen, die den Zugriff auf die exportierten Daten steuern. Innerhalb der kommaseparierten Liste sind keine Leerzeichen statthaft! Mögliche Werte sind:
secure, insecure
ro, rw
sync, async
wdelay, no_wdelay
hide, nohide
subtree_check, no_subtree_check
root_squash, no_root_squash
all_squash, no_all_squash
anongid=gid
anonuid=uid
Die Optionen zum Verändern der Nutzerkennungen werden als »Squashing« bezeichnet und werden im folgenden Abschnitt detailliert diskutiert.
Als reales Szenario nehmen wir an, dass unser NFS-Server (»sonne.galaxis.de«) als Datei- und als NIS-Server konfiguriert wurde. Die zentrale Aufgabe eines NIS-Servers ist immer noch die Bereitstellung einer zentralen Benutzerverwaltung, in Kombination mit einen NFS-Server werden meist auch die Heimatverzeichnisse der Benutzer zentral gehalten, sodass ein Benutzer sich an einen beliebigen Rechner eines Pools anmelden kann und überall seine gewohnte Umgebung vorfinden wird.
Des Weiteren gehen wir davon aus, dass die Clients nur über eine beschränkte Plattenkapazität verfügen, sodass sie etliche Daten, die nicht der Grundfunktionalität dienen, ebenso via NFS importieren (wir gehen jetzt nicht soweit, festplattenlose Clients in die Betrachtung einzubeziehen, die sogar ihr Root-Dateisystem und den Swap via NFS beziehen).
In der nachfolgenden Beispieldatei finden Sie weitere Anmerkungen in Form von Kommentaren, warum welche Option für welches Verzeichnis gesetzt wurde; die Überlegungen sollten auf etliche Rahmenbedingungen übertragbar sein.
|
root@sonne> vi /etc/exports # Wir nehmen an, dass /home auf einer eigenen Partition liegt, sodass sich die Prüfung, ob eine Datei innerhalb des exportierten Verzeichnisses liegt, erübrigt. Dass Benutzer innerhalb ihrer Heimatverzeichnisse auch Schreibrechte erhalten sollten, ist verständlich. Da unsere Netzwerk als sichere Zone anzusehen ist, verzichten wir auf die Einschränkung der zulässigen Portnummern: /home *.galaxis.de(rw,no_subtree_check,insecure) # Wie der Name schon sagt, sind Daten unter /usr/share geeignet, um an zentraler Stelle für verschiedene Clients bereit gestellt zu werden. Kein Client muss diese Daten veränern können, deshalb setzen wir gleich die Benutzerkennungen auf den sehr restriktiven Zugang »nobody« /usr/share *.galaxis.de(ro,all_squash) |
Abschließend sei darauf hingeweisen, dass auf Clientseite beim Import eines Verzeichnisses die Rechte weiter eingeschränkt werden können. Die Informationen dazu finden Sie im Abschnitt zum NFS-Client.
| Squashing |
|
Gerade wurde bei den Optionen und Parametern der Begriff »Squashing« eingeführt, doch was bedeutet er?
Lassen Sie es mich an einem Beispiel erklären: Auf dem System »sonne« (NFS-Server)
existieren in einem exportierten Verzeichnis folgende Dateien:
|
user@sonne> ls -l -rw-r----- 1 root root 166 Apr 27 10:45 foo.bar -rw------- 1 tux users 16 Apr 27 10:45 testdaten.txt |
| root | 0 | |
| tux | 501 |
Auf System »venus« (unser NFS-Client) existieren Benutzer mit folgenden UIDs:
| root | 0 | |
| alf | 501 | |
| tux | 502 |
Was passiert nun, wenn wir auf dem Client eine Serverfreigabe mounten?
Dazu muss man wissen, dass Unix die Zugriffsrechte nicht aufgrund der Benutzernamen verwaltet, sondern einzig anhand der zugrundeliegenden UIDs. In unserem Falle hat der Benutzer »alf« (auf dem Client) plötzlich Zugriff auf die Datei »testdaten.txt« von Benutzer «tux«, da beide dieselbe UID 501 besitzen. Gleiches gilt natürlich ebenso für den Benutzer »root«.
Um dies zu verhindern, gibt es das »Squashing«. Hierbei werden die UIDs und GIDs der auf die gemounteten Verzeichnisse zugreifenden Benutzer auf eine neutrale UID (der Pseudouser nobody mit UID -2) und GID (nogroup mit GID -2) gesetzt, wenn dieses mit der Option »all_squash« exportiert wurde. Die UID 0 (GID 0; also Root) wird in der Voreinstellung stets nach »nobody/nogroup« gemappt; erst die Option »no_root_squash» verhindert die Umsetzung.
Der alte User-Space-NFS-Server erlaubte das »Squashen« jeder UID auf jede beliege andere und ebenso konnte jede Gruppenkennung (GID) auf jede andere gemappt werden. Der neuer Kernel-NFS-Server arbeitet wesentlich restriktiver und gestattet einzig, anstatt dem Pseudobenutzer »nobody« bzw. der Pseudogruppe »nogroup« mittels »anonuid=<UID>« bzw. »anonguid=<GID>« andere Kennungen zu vergeben. Diese gelten dann jedoch für beliebige Gruppen oder Benutzer.
Bez. unserer oben angegebenen Benutzerstrukturen würde bei Export des Verzeichnisses mittels der Option »all_squash« der Client-Benutzer »alf« nur noch ein »Nobody« sein und hätte somit nur Lesezugriff auf die Datei »testdaten.txt«
| Etwas Statistik |
|
Nicht zuletzt beim Aufspüren von Fehlkonfigurationen sind zwei Kommandos zur Diagnose des NFS-Servers nützlich. Zum einen erlaubt showmount einen Einblick sowohl auf die vom Server bereitgestellten Dateisysteme als auch auf die momentan aktiven Clients. Zum zweiten erlaubt nfsstat die Auswertung zahlreicher statistische Daten des Kernel-NFS-Servers.
| /usr/sbin/showmount [ -adehv ] [ NFS-Server] |
Ohne Argumente aufgerufen, listet das Kommando die Namen der NFS-Clients auf, die aktuell Verzeichnisse vom Server importiert haben; bei Verwendung der Option »-a« werden zusätzlich die Verzeichnisnamen aufgeführt:
|
user@sonne> /usr/sbin/showmount All mount points on sonne: venus.galaxis.de:/home/ venus.galaxis.de:/usr/share/ erde.galaxis.de:/home/ |
Um einzig die aktuell von Clients importierten Verzeichnisnamen anzuzeigen, nicht aber die Namen der Clientrechner selbst, dient die Option »-d«. »-h« schreibt eine Kurzhilfe aus; »-v« die Versionsnummer des Programms.
Vor allem für Clientrechner interessant ist die Option »-e«, mit der sie, wenn Sie auf der Kommandozeile noch den Namen eines NFS-Servers angeben, testen können, welche Verzeichnisse ein Server für welchen Client exportiert:
|
user@erde> /usr/sbin/showmount -e sonne.galaxis.de Export list for sonne.galaxis.de: /home *.galaxis.de /usr/share *.galaxis.de |
| /usr/sbin/nfsstat [-anrcs] [-o <Kategorie> |
Der Zugang zu den Statistiken im Kernel trägt eher informativen Charakter und verdeutlichen, welche Anforderungen die Clients tatsächlich stellen. Die Unterscheidung nach NFS Version 2 und 3 zeigt, in welchem Verhältnis die Clients nach dem alten bzw. nach dem neuen Protokoll arbeiten; im nachfolgend dargestellten Beispiel habe ich der besseren Übersicht wegen die Tabelle für die Versionen 2 entfernt.
Die Optionen des Kommandos helfen, die Ausgaben auf einen konkreten Typ zu beschränken. So begnügt sich »nfsstat -s« auf die Ausschrift der Statsitik der Serverseite, während »nfsstat -c« nur die Client-Daten offenbahrt.
»nfsstat -r« beschränkt sich auf Angabe der RPC-relevanten Daten; »nfsstat -n« tut dasselbe für die NFS-spezifischen Informationen.
|
root@sonne> nfsstat Server rpc stats: calls badcalls badauth badclnt xdrcall 20860 0 0 0 0 Server nfs v3: null getattr setattr lookup access readlink 0 0% 264 1% 0 0% 1148 5% 14726 70% 32 0% read write create mkdir symlink mknod 4485 21% 0 0% 0 0% 0 0% 0 0% 0 0% remove rmdir rename link readdir readdirplus 0 0% 0 0% 0 0% 0 0% 188 0% 14 0% fsstat fsinfo pathconf commit 1 0% 2 0% 0 0% 0 0% Client rpc stats: calls retrans authrefrsh 775 0 0 Client nfs v3: null getattr setattr lookup access readlink 0 0% 263 33% 0 0% 0 0% 494 63% 2 0% read write create mkdir symlink mknod 1 0% 0 0% 0 0% 0 0% 0 0% 0 0% remove rmdir rename link readdir readdirplus 0 0% 0 0% 0 0% 0 0% 0 0% 14 1% fsstat fsinfo pathconf commit 0 0% 1 0% 0 0% 0 0% |
Unter Kategorie können nochmals die Statistiken speziell für RPC (»nfsstat -o rpc«) und NFS (»nfsstat -o nfs«) abgerufen werden. Zusätzlich sind Informationen über Auslastung des Transportprotokolls (»nfsstat -o net«), des Dateihandle-Caches (»nfsstat -o fh«) und des Antwortcaches (»nfsstat -o rc«) abrufbar.
|
root@sonne> nfsstat -o net Server packet stats: packets udp tcp tcpconn 0 20860 0 0 Client packet stats: packets udp tcp tcpconn 0 0 0 0 |
| Der Mountvorgang intern |
|
Die Abläufe eines vom NFS-Clients initiierten Dateiimports sind recht komplex. Die Verwendung des hierzu notwendigen Kommando mount finden Sie im Abschnitt zum NFS-Client. Hier schauen wir hinter die Kulissen, also auf das Zusammenspiel der einzelnen Komponenten bis letztlich das Dateihandle, eine vom Server vergebene eindeutige Kennziffer für das Verzeichnis, zum Client gelangt.
Ausgangspunkt sei folgender erstmaliger Mount-Aufruf:
| root@venus> mount -t nfs sonne:/home /home |
Anmerkung: Bei entsprechender Konfiguration kann ein Mountvorgang auch einem »normalen« Benutzer gestattet werden oder gar per Automounter automatisch bei Bedarf erfolgen.
Zum Zeitpunkt der ersten Kontaktaufnahme zum NFS-Server fehlt dem Client die Kenntnis der korrekten Portnummer, an dem dieser wartet. Deshalb geht die erste Anfrage an den Portmapper des Servers, an welchem Port der Mount-Daemon wartet. Mittels einer weiteren Anfrage beim Portmapper sollte der Client auch noch die Portnummer des NFS-Daemons in Erfahrung bringen (falls notwendig, erfragt der Client auch noch die Portnummern der RPC-Dienste NSM und NLM). Die Prinzipien des Verfahrens sollten Ihnen aus dem Abschnitt Schritte zum Serverstart bekannt sein. Einmal erfragte Portnummern werden solange lokal vorgehalten, bis ein Zugriff auf einen solchen Port einen Fehler meldet (oder der Client neu bootet;-).
Mit der Erkenntnis, an welchem Port der Mount-Daemon des Servers wartet, wendet sich der Client nun direkt an diesen. Der Mount-Daemon durchsucht nun die Datei »/var/lib/nfs/etab«, ob das erwünschte Verzeichnis zum Export freigegen ist und ob der Client zum Import berechtigt ist.
|
user@venus> cat /var/lib/nfs/etab /usr/share *.galaxis.de(ro, async, wdelay, hide, secure, root_squash, all_squash,subtree_check, secure_locks, mapping=identity, anonuid=-2, anongid=-2) /home/ *galaxis.de(rw, async, wdelay, hide, secure, root_squash, no_all_squash, no_subtree_check, secure_locks, mapping=identity, anonuid=-2, anongid=-2) |
Verlaufen die Überprüfungen erfolgreich, so wendet sich der Mount-Daemon an den NFS-Daemon (Funktion GETFH()), der ein eindeutiges Dateihandle, das das exportierte Verzeichnis referentiert, erzeugt. Dieses Handle ist ein Datenobjekt und enthält eine eindeutige Zufallszahl, die die Identifikation der Datei (ein Verzeichnis ist unter Unix letztlich auch nur eine Datei) gewährleisten soll und nur einmalig vergeben wird. Dieses Dateihandle übergibt der NFS-Daemon dem Mount-Daemon, der es zum Client sendet (Abbildung 3).
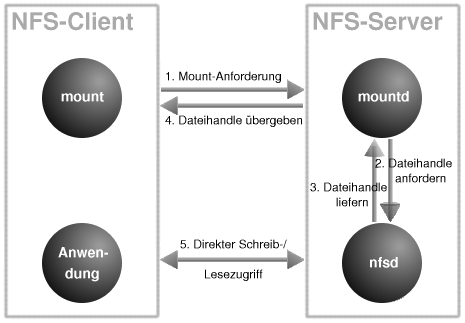
Abbildung 3: Ablauf eines NFS-Mounts
Alle weiteren Zugriffe auf Dateien des importierten Verzeichnisses erfolgen durch direkten Kontakt zwischen NFS-Client und dem NFS-Daemon-Prozess. Der Client gibt jeweils das Dateihandle an, womit der Server das Verzeichnis kennt, von dem aus er nach angeforderten Dateien suchen muss. Was in der Abbildung nicht dargestellt wurde, ist die eventuell notwendige Interaktion zwischen Lock-Manager und Status-Monitor, falls beim Zugriff auf Dateien mit Sperren gearbeitet werden soll.
| Interna |

|
Rein informellen Charakter tragen die weiteren Ausführungen, die Apsekte ansprechen, die für die Administration von NFS selbst unerheblich sind.
Oftmals ist es wünschenswert, wenn es eine Art Zwischenspeicher für die Netzzugriffe gibt, um die Netzbelastung so gering wie möglich zu halten. Hierfür gibt es von SUN (mal wieder!) ein Dateisystem namens Cachefs, das genau dieses »Caching« übernimmt. Leider existiert noch keine Implementierung dieses Dateisystems für Linux, jedoch wird es unter anderen Unixen häufig verwendet. Bei Cachefs wird ein Puffer-Verzeichnis angelegt, das nach und nach mit den vom Server angeforderten Daten gefüllt wird. Bei jedem Datenzugriff wird nun zunächst geprüft, ob diese eventuell bereits im lokalen Puffer enthalten sind. Falls ja, muss die Datei nicht erst erneut übers Netz vom Server geladen werden, was einen mitunter erheblichen Geschwindigkeitsvorteil mit sich bringt, da lokale Bus- und Dateisysteme immer schneller sind als Netzleitungen (oder haben sie ein Gigabit-Ethernet zu Hause?).
Quotas dienen der Beschränkung des einem Benutzer zur Verfügung stehendem Plattenspeicherplatzes. Die Quotas selbst werden nur auf dem Server eingerichtet und ihre Einhaltung überwacht. Um Benutzern auf den Clients eine Abfrage ihres Quotastatus zu ermöglichen, ist auf dem NFS-Server der RPC-Dienst rpc.rquotad zu starten.
Um gleichzeitige Zugriffe auf einunddieselben Dateien koordinieren zu können, behilft sich NFS eines Network-Lock-Managers (rpc.lockd) und eines Network-State-Monitors (rpc.statd). Das allein garantiert noch keine Dateisperren, denn diese müssen die auf NFS-importierte Dateien zugreifenden Programme auf Clientseite implementieren. Und dies tun bis heute die wenigsten Programme unter Linux. Daher ist es in den meisten Linuxnetzwerken gar nicht erforderlich, rpc.statd und rpc.lockd zu aktivieren.
Prinzipiell fordert ein entsprechend realisiertes Programm vom Kernel eine Dateisperre an. Der Kernel erkennt, dass die Datei auf einem via NFS gemountetem Dateisystem liegt und leitet die Anforderung an den lokalenLock-Manager weiter. Dieser sendet die Anforderung an den Lock-Daemon auf dem Server, welcher den Vorgang akzeptiert oder ablehnt. Das Ergebnis schickt er zum Lock-Daemon des Clients zurück, der es dem Kernel reicht.
Angenommen, während einer aktiven Dateisperre startet entweder der Client oder der Server neu, was passiert mit den Sperren? Jetzt kommt der Status-Monitor ins Spiel. Wenn auf Serverseite der Lock-Manager für einen Client eine Dateisperre anlegt, so unterrichtet er den Status-Monitor, welcher den Namen des Client-Rechners unter /var/lib/nfs/sm ablegt. Auf Clientseite erfährt der Status-Monitor die akzeptierte Sperre ebenso vom lokalen Lock-Manager, nur speichert er den Namen des Servers, von dem die Sperre gesetzt wurde.
Bootet nun ein Client neu, prüft der lokale rpc.statd sofort, ob irgendein Server zu unterrichten ist. Falls ja, kontaktiert er dessen Status-Monitor, der den Lock-Manager auf Serverseite unterrichtet, welcher wiederum alle Dateisperren des Clients aufhebt.
Fällt allerdings der Server aus, so unterrichtet nach einem Neustart dessen Status-Monitor die Kollegen auf allen Clients, die aktuelle Dateisperren besaßen. Die Lock-Manager auf den Clients versuchen nun zunächst die Dateisperren vom Server erneut anzufordern. Der Lock-Manager auf dem Server wird die durch den Neustart ungültigen Sperren noch »eine Zeit lang« reservieren und einzig dem »alten« Besitzer (also Client) gestatten, die Sperre unverzüglich anzufordern. So wird dem Client eine Chance erteilt, die verlorenen Sperren zu erneuern.
Obwohl NFS V2 schon mehrere Jahre nach seiner Fertigstellung einen neuen großen Bruder erhielt (NFS V3), ist es trotzdem immer noch ein Standard und wird bei Linux weitestgehend eingesetzt. Langsam aber sicher findet der Umstieg auf NFS V3 statt, der aus Kompatibiltätsgründen fast alle alten Prozeduren übernimmt und neue Eigenschaften einbringt. So kann bei Version 3 nun zwischen den beiden Protokollen UDP und TCP ausgewählt werden, was bei Einsatz von TCP eine Entlastung des Dienstes bedeutet, da TCP nun die Fehlersicherung übernimmt und somit eine sichere Leitung gewährleistet - jedoch zum Preis einer erhöhten Netzbelastung (an der TCP-Unterstützung durch den Kernel-NFS-Daemon wird derzeit gearbeitet; vergleiche »Ausblick« in der Einleitung).
Die Größenlimits werden den heutigen Verhältnissen angemessener gestaltet bzw. ganz aufgehoben. Es wird ein asynchroner, zusätzlicher Schreib- und Lesemodus eingeführt, der die Geschwindigkeit deutlich erhöhen wird.
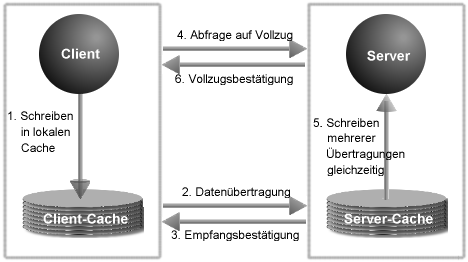
Abbildung 7: Asynchrones Schreiben in NFS-3
Dabei wird nicht mehr wie beim synchronen Zugriff ein Arbeitsvorgang komplett abgeschlossen, sondern die gecachten Daten werden beim Server zwischengespeichert und »bei geeigneter Gelegenheit« auch gesammelt festgeschrieben. Erst auf die endgültige Bestätigung hin verwirft der Client seine Daten im Cache.
Auch bei den Lesezugriffen wurden neue Prozeduren eingeführt. So wurden beim Objektaufruf (bspw. ls -al) zuerst alle Daten übertragen (READDIR()) und danach jeweils die Attribute (GETATTR()) der Objekte. Dies wird in Version 3 durch eine vollständig neue Prozedur (READDIRPLUS()) ersetzt, die alles in einem Aufwasch erledigt und die erhoffte Steigerung der Geschwindigkeit nach sich zieht.
NFS nach Version 3 arbeitet anstatt mit 32 Bit mit 64 Bit langen Dateizeigern, sodass auch hier die insbesondere für Datenbankanwendungen schmerzlichen Schranken der Datei- und Dateisystemgrößenbeschränkung fallen.
Mittlerweile wird eine vierte Version (NFSV4) erstellt. Die Tests sind weitestgehend abgeschlossen und nun wird an einer Verabschiedung, die voraussichtlich 2002 erfolgen wird, gearbeitet.