

Dateisysteme |
| Übersicht |
|
Jede Computeranwendung wird irgendwelche Informationen speichern wollen, seien es permanente Daten, die ein Programm als Ausgabe liefert oder aber temporäre Dateien, die nicht komplett in den Adressraum eines Prozesses passen. Beim erneuten Start des Programms wird dieses seine abgespeicherten Informationen schnell wiederfinden wollen. Damit haben wir nur zwei wesentliche Aspekte eines Dateisystems tangiert...
Dateisystemimplementierungen gibt es zuhauf und Linux kennt die meisten. Wie das möglich ist, ist u.a. Gegenstand des Abschnitts.
Dateisysteme müssen vor ihrer Verwendung angelegt werden. Fehler beim Speichern, z.B. durch Rechnerabsturz, bleiben nicht aus. Also gehören auch Kommandos zur Überprüfung und Reparatur von Dateisystemen zum Umfang eines jeden Betriebssystems.
| Das virtuelle Dateisystem |
|
So ziemlich jedes neue Betriebssystem, das jemals jemand in die Welt gesetzt hatte, brachte eigene Vorstellungen vom Aussehen seines Dateisystems mit. Gemeinsam ist ihnen die Absicht, eine große Menge an Informationen permanent speichern zu können, so dass auch noch mehrere Prozesse gleichzeitig auf diese zugreifen können. Dateien sind die Container, in denen die Informationen abgelegt sind und Festplatten, Disketten, ... sind das Medium der dauerhaften Speicherung.
Aber damit hören die Gemeinsamkeiten der Dateisysteme auch schon auf.
Aus Sicht des Benutzers unterscheiden sich vor allem:
Aus Sicht des Betriebssystems kommen noch die Details der Implementierung hinzu:
Die meisten Betriebssysteme umgehen das Problem mit dem Vogel-Strauß-Algorithmus: sie unterstützen neben ihrem eigenen Dateisystem bestenfalls marktstrategisch wichtige Fremdsysteme.
Nicht so Linux, das so ziemlich mit jedem Dateisystem zu Rande kommt, und selbst den Zugriff auf Partitionen von Windows-Systemen ermöglicht.
Wie wurde das realisiert?
Indem eine Schnittstelle zwischen Betriebssystem und den unterschiedlichen Dateisystemen geschaffen wurden. Es liegt nun in der Verantwortung dieses Virtuellen Dateisystems, wie es die Systemrufe des Kernels in die spezifischen Aktionen eines konkreten Dateisystems umsetzt.
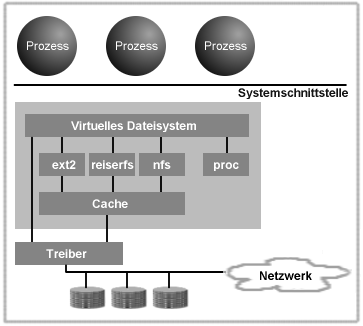
Abbildung 1: Prinzip des Virtuellen Dateisystems
| Unterstützte Dateisysteme |
|
Die Unterstützung der Dateisysteme ist Aufgabe des Kernels, d.h. jedes Dateisystem, auf das Ihr System zugreifen soll, muss in den Kernel einkompiliert oder als Modul realisiert sein. Um schnell zu entscheiden, wie die momentane Unterstützung ausschaut, können Sie einen Blick in die Datei »/proc/filesystems« werfen:
|
user@sonne> cat /proc/filesystems nodev sockfs nodev tmpfs nodev shm nodev pipefs nodev proc ext2 vfat iso9660 nodev nfs nodev devpts reiserfs |
Liegt der Treiber für ein Dateisystem als Modul vor, so erscheint es erst in obiger Datei, wenn sein Modul geladen wurde. Sehen Sie im Verzeichnis »/lib/modules/<kernel_version>/kernel/fs« nach, welche Dateisystemtreiber durch Module realisiert sind (seit Kernel 2.4.0 sind die Module jedes Dateisystems in einem eigenen Unterverzeichnis enthalten; bei älteren Kerneln sind alle Module in einem Verzeichnis »/lib/modules/<kernel_version>/fs« organisiert):
|
||||||||||||||||||||||||||||||||||
Beim Zugriff auf ein solches Dateisystem sollte der Kernel (exakt: der kerneld [Kernel 2.0.x] bzw. kmod [Kernel >= 2.2]) das entsprechende Modul automatisch laden. Näheres zum Kernel und Modulen erfahren Sie im Kapitel Kernel.
Einige der interessanteren Dateisysteme fasst die folgende Tabelle zusammen:
bfs
ext
iso9660
hpfs
loopback
minix
msdos
ncpfs
nfs
ntfs
ramdisk
SMB
swap
SystemV
umsdos
vfat
Auf jedes Dateisystem im Detail einzugehen, würde Bände füllen, weswegen wir nur das Linux-Dateisystem ext2, die beiden Vertreter der Journaling Filesysteme ReiserFS und ext3 sowie das Device-Dateisystem devfs genauer vorstellen möchten. Im Kapitel Kernel erfahren Sie Einzelheiten zum Prozessdateisystem.
| Das Extended File System Version 2 (ext2) |
|
ext2 galt über Jahre hinweg als das Standard-Dateisystem für Linux. Erst mit Aufkommen der Journaling Dateisysteme etablierten sich ernsthafte Alternativen. Doch erforderten Unzulänglichkeiten in Kernelversionen der 2.2er Serie und im Bootmanager Lilo < Version 21.6, dass zumindest der Kernel selbst und die Dateien des Lilo-Bootmanagers zwingend auf einem ext2-Dateisystem platziert wurden. Aktuellen Kernel- und Lilo-Versionen sind derartige Einschränkungen fremd.
Dass das ext2 gegenüber anderen Implementierungen zahlreiche Vorteile mit sich bringt, werden Sie in diesem Abschnitt kennen lernen.
ext2 hält sich in seinem Aufbau stark an die bewährte Architektur, die allen UNIX-Dateisystemen gemein ist. Beginnen wir deshalb mit dem Allgemeinen.
Generell werden die Verwaltungsinformationen von den eigentlichen Daten getrennt gespeichert. Die Verwaltungsdaten einer Datei, also alle Merkmale wie Rechte, Zugriffszeiten, Größe usw., werden in so genannten Inodes gehalten. Die einzige wichtige Information, die nicht im Inode steht, ist der Name der Datei. Der selbst steht in einem Verzeichnis und verweist auf den zugehörigen Inode. Ein Verzeichnis wiederum ist auch nur eine Datei. Es wird durch einen Inode repräsentiert und die Daten der Verzeichnisdatei sind die enthaltenen Verzeichniseinträge.
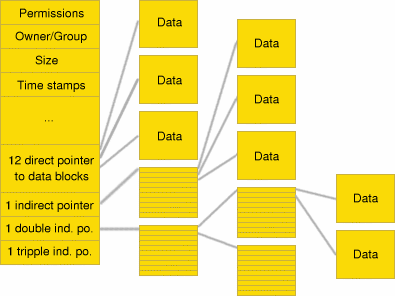
Abbildung 2: Speicherung einer Datei im Inode
Genau 60 Bytes stünden im Inode zur Speicherung von Daten zur Verfügung. Allerdings werden einzig die Daten symbolischer Links direkt im Inode gehalten, für alle anderen Dateitypen gelten die letzten 15 Einträge im Inode als 32-Bit Zeiger und verweisen auf Datenblöcke, die nun die eigentlichen Daten aufnehmen. Wie viele Zeigereinträge gültig sind, wird anhand der im Inode gespeicherten Anzahl belegter Datenblöcke berechnet.
12 direkte Zeiger auf Datenblöcke sind in einem Inode vorgesehen. Genügt der Speicherplatz für eine Datei noch immer nicht aus, referenziert der nächste Eintrag im Inode einen Datenblock, dessen Inhalt nun als Zeiger auf die eigentlichen Datenblöcke betrachtet wird; man spricht von einem einfach indirekten Zeiger. Ist die Datei weiterhin unersättlich, kommt der nächste Eintrag ins Spiel. Er verweist auf einen Datenblock, dessen Inhalt Zeiger auf Datenblöcke sind, deren Inhalte letztlich Zeiger auf die Daten der Datei sind. Alles klar? Es handelt sich um einen zweifach indirekten Zeiger. Und manche Dateien können einfach nicht genug Speicherplatz bekommen, also ist der nächste (und letzte) Eintrag im Inode ein Zeiger auf... [ich erspare mir die Ausführungen]. Es ist ein dreifach indirekter Zeiger.
Während die Größe eines Inodes im Falle des ext2 konstant 128 Byte beträgt, kann die Datenblockgröße beim Einrichten des Dateisystems festgelegt werden. Zulässig sind 1k, 2k und 4k (wird meist bevorzugt; höhere Blockgrößen sind (derzeit) nicht zulässig, da die Pagegröße 4k beträgt).
Eine einfache Berechnung soll zeigen, wie die Größe eines Datenblocks die maximal mögliche Größe einer Datei beschränkt.
Unsere Blockgröße sei »1024 Bytes«, dann lassen sich mit den 12 direkten Zeigern des Inodes maximal »12*1024 Bytes» (12k) Daten speichern. Der einfach indirekte Zeiger verweist auf einen Datenblock, der maximal »1024/4« Zeiger (ein Zeiger belegt 4 Bytes) aufnehmen kann, also erreicht dieser »1024*256 Bytes« (256k) Daten. Mit derselben Überlegung erhält man für den zweifach indirekten Zeiger »1024*256*256 Bytes« (65536k) Daten und der dreifache schafft gar »1024*256*256*256 Bytes« (16GByte) Daten.
Um die machbare Dateigröße zu erhalten, sind die vier Werte zu addieren. Die nachfolgende Tabelle enthält die (theoretischen) Werte für die verschiedenen Datenblockgrößen:
| Blockgröße (kByte) | Maximale Dateigröße (GByte) |
|---|---|
| 1 | 16 |
| 2 | 256 |
| 4 | 4100 |
Wie so oft klafft zwischen Theorie und Praxis ein riesiges Loch, so dass tatsächlich nur Daten bis zu einer Größe von 2 GByte (Linux Kernel 2.2.x) gehandhabt werden können. Diese Beschränkung liegt in der Handhabung der Dateigröße durch den Kernel begründet, der diese nur mit 32 Bit speichert, wobei das höchstwertige Bit auch noch als Vorzeichen betrachtet wird. Im 2.4er Kernel wird mit 64 Bit gearbeitet, so dass er den »Schwarzen Peter der Begrenzung« den Dateisystemimplementierungen in die Schuhe schiebt. Um das »ext2« für diese Dateigröße einsetzen zu können, wird ab Kernel 2.4 ein bislang nicht verwendeter Eintrag im Inode zusätzlich zur Speicherung der Dateigröße verwendet, so dass die notwendigen 64 Bit - bei Wahrung der bisherigen Strukturen - zur Verfügung stehen.
Der Datenblock ist im Sinne der Dateiverwaltung die kleinste zu adressierende Einheit. Als Konsequenz ist der physische Speicherplatzverbrauch einer Datei im Mittel größer ist als ihr tatsächlicher Bedarf. Ist eine Datei bspw. 1500 Bytes groß, so benötigt sie bei einer 1k Blockgröße 2k Speicherplatz, bei 2k Blockgröße 2k Speicherplatz, bei 4k Blockgröße belegt sie jedoch 4k Speicherplatz, d.h. im letzten von einer Datei belegten Block geht im Mittel die Hälfte des Speicherplatzes als »Verschnitt« verloren. Die Logik legt nahe, dass die 1k-Blockgröße die beste Wahl sei.
Die Vermutung kann man bestätigen, für den Fall, dass man überwiegend sehr kleine Dateien speichern will. Bei großen Dateien jedoch beschleunigt die 4k-Blockgröße den Lesezugriff enorm, da sicher gestellt ist, dass umfangreiche Teile der Datei hintereinander auf der Festplatte liegen und der Schreib-Lese-Kopf diese »in einem Ritt« besuchen kann. Hohe Blockgrößen minimieren den Effekt der Fragmentierung.
Wird eine neue Datei erzeugt, so muss ein freier Inode für sie gefunden und reserviert werden. Ebenso reserviert ext2 eine Reihe möglichst zusammen hängender Blocknummern, um die Daten aufnehmen zu können. Vermutlich werden viel zu viele Blöcke als belegt markiert. Aber solange die Datei nicht geschlossen wurde, ist ihr tatsächlicher Speicherbedarf ungewiss. Wird die Bearbeitung einer neuen Datei beendet, gibt ext2 die nicht benötigten Blöcke wieder frei, verbraucht die Datei alle Einheiten, liegen diese nun in einem Stück auf der Platte. Dieselbe »vorausschauende« Markierung von Blöcken kommt beim Anfügen von Daten an eine existierende Datei zur Anwendung, so dass der Grad der Fragmentierung einer Datei von Haus aus in akzeptablen Grenzen gehalten wird.
Um einen freien Inode oder Block aufzuspüren, könnte sich ext2 durch die Inodes bzw. Blöcke »durchhangeln«, bis endlich ein unbelegter Eintrag gefunden wurde. Jedoch wäre diese Art der Suche furchtbar ineffizient. ext2 verwendet deshalb Bitmaps, die bitweise kodieren, welche Blöcke bzw. Inodes frei und welche belegt sind. Es existieren jeweils eine Bitmap für Blöcke und eine für die Inodes. Eine »0« des Bits x kennzeichnet den Block (Inode) mit der Nummer x als frei, eine »1« steht für einen verwendeten Block (Inode).
Eine solche Bitmap belegt genau einen Block, d.h. bei 1k Blöcken verwaltet eine Bitmap 8192 Inodes bzw. Datenblöcke. Mit 4k Blockgröße können 32768 Einheiten angesprochen werden, was wiederum die mögliche Größe einer Datei auf 128 MByte beschränken würde.
ext2 organisiert das Dateisystem in Gruppen. Jede Gruppe beinhaltet eine Kopie des Superblocks, eine Liste aller Gruppendeskriptoren, die Bitmaps für die enthaltenen Inodes und Datenblöcke und die Listen derselbigen.
Abbildung 3: Aufbau eines ext2-Gruppe
Der Superblock einer jeden Gruppe ist die exakte Kopie des Superblocks des Dateisystems und beinhaltet Informationen zur Blockgröße, der Anzahl der Inodes und Datenblöcke, den Status des Dateisystems, Anzahl der Mountvorgänge seit der letzten Überprüfung usw. Alle Informationen lassen sich mit dem Kommando dumpe2fs gewinnen:
|
root@sonne> dumpe2fs /dev/hda4 Filesystem volume name: <none> Last mounted on: /mnt/boot Filesystem UUID: 99c0ce4a-9e7d-11d3-86d7-b832bfd4e1f7 Filesystem magic number: 0xEF53 Filesystem revision #: 0 (original) Filesystem features: (none) Filesystem state: not clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 8016 Block count: 16033 Reserved block count: 801 Free blocks: 13365 Free inodes: 7983 First block: 1 Block size: 1024 Fragment size: 1024 Blocks per group: 8192 Fragments per group: 8192 Inodes per group: 4008 Inode blocks per group: 501 Last mount time: Mon Jul 3 07:07:46 2000 Last write time: Mon Jul 3 07:07:51 2000 Mount count: 17 Maximum mount count: 100 Last checked: Fri Jun 9 07:06:36 2000 Check interval: 15552000 (6 months) Next check after: Wed Dec 6 06:06:36 2000 Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) Group 0: (Blocks 1 -- 8192) Block bitmap at 3 (+2), Inode bitmap at 4 (+3) Inode table at 5 (+4) 6044 free blocks, 3981 free inodes, 2 directories Free blocks: 519-525, 1410-1416, 1826-1834, 2155-2158, 2174-2178, 2181-8192 Free inodes: 20, 29-4008 Group 1: (Blocks 8193 -- 16032) Block bitmap at 8195 (+2), Inode bitmap at 8196 (+3) Inode table at 8197 (+4) 7321 free blocks, 4002 free inodes, 1 directories Free blocks: 8712-16032 Free inodes: 4015-8016 |
Gruppendeskriptoren beinhalten Informationen zur relativen Lage der Bitmaps und der Inode-Tabelle innerhalb einer Gruppe. Da die Deskriptoren aller Gruppen in jeder Gruppe gespeichert sind, kann bei Beschädigung einer Gruppe diese anhand der Informationen restauriert werden (zumindest solange kein mechanischer Defekt des Speicherbereichs vorliegt).
Die Nummerierung der Inodes und Blöcke ist innerhalb eines Dateisystems eindeutig. Ist der letzte Inode der Gruppe x der Inode Nr. y, so ist der erste Inode der Gruppe x+1 der Inode Nr. y+1.
Und der Sinn der Gruppe? Durch die gewählte Struktur wird sicher gestellt, dass sich die Daten einer Datei nahe bei ihrem Inode befinden und die Dateien eines Verzeichnisses nahe der Verwaltungsstruktur des Verzeichnisses liegen. Letztlich verhilft die Anordnung zu einem schnelleren Zugriff auf die Festplatte.
Abbildung 4: Aufbau des ext2
Das Dateisystem ext2 stellt sich als eine Aneinanderreihung gleich großer Gruppen dar, denen der in jedem Dateisystem vorhandene und im Aufbau standardisierte Bootsektor voransteht. Die Anzahl der Gruppen wird dabei durch die Faktoren der Partitionsgröße einerseits und durch die gewählte Blockgröße und Inode-Anzahl andererseits bestimmt.
Da die Speicherkapazität einer einzelnen Gruppe auf maximal 128 MByte begrenzt ist, werden die Daten sehr großer Dateien auf mehrere Gruppen verteilt.
| Journaling Dateisysteme |
|
In regelmäßigen Abständen, und prinzipiell zum ungünstigsten Zeitpunkt (weil man gerade mal wieder unter Zeitdruck steht), wartet Linux mit einem verzögerten Systemstart auf:
| /dev/hda1 has reached maximal mount count, check forced... |
Das Linuxdateisystem ext2 hält es mal wieder für angebracht, seinen Inhalt einer gewissenhaften Überprüfung zu unterziehen. Je nach Größe der Partition und Leistungsfähigkeit des Prozessors kann die Revision wenige Minuten bis hin zu einigen Stunden konsumieren. Solch geplanter Aktivität lässt sich mit kleineren Manipulationen zuvor kommen. Was aber nach einem Absturz oder einem hängen gebliebenen »not clean - Filesystem state«, nur weil Sie den Ausschalter zwei Sekunden zu früh bemühten? Jetzt hilft nur Geduld ...irgendwann wird der Test schon fertig werden...
Für den privaten Rechner ist das Verhalten zwar lästig, aber ohne Folgen. Was aber, wenn die Datenbank des Servers für einige Zeit ausfällt, nur weil dieser nach einem Absturz die Platten scannt? Hunderte Clients warten vergebens auf die angeforderten Daten? Hier sollte die Überführung des Dateisystems in einen konsistenten Zustand höchstens ein paar Sekündchen dauern.
ext2 ist ziemlich faul, was die Buchführung seiner Aktivitäten betrifft. Wird ein ext2-Dateisystem »gemountet«, vermerkt es nur, dass es in Benutzung ist. »Not clean« lautet der Status des Systems. Folgt später dann ein »umount«, wechselt der Status zurück auf »clean«. Wenn das saubere Abhängen - aus welchem Grund auch immer - scheiterte, muss ext2 beim folgenden Systemstart alle Dateien überprüfen, um eventuellen Ungereimtheiten auf die Schliche zu kommen.
Hier setzt die Idee des Journal Dateisystems an. In ihm werden alle momentan bearbeiteten Dateien protokolliert, so dass im Falle eines Systemcrashs beim Wiederanlauf einzig diese Dateien auf Inkonsistenzen hin zu überprüfen sind. Eine weitere Maßnahme ist die Einführung eines transaktionsbasierten Modells, wonach eine Datei solange ihre Gültigkeit behält, bis die Bearbeitung einer neueren Version vollständig abgeschlossen wurde. Somit wird die fehlerträchtige Zeitspanne auf den Moment des Abspeicherns reduziert.
Journaling Dateisysteme bewähren sich schon seit einigen Jahren im praktischen Einsatz. Nur eine Implementierung unter Linux ließ lange auf sich warten. Derzeit existieren vier Implementierungen:
Dem Umstand, ersteres einsatzbereites System mit einem Journal gewesen zu sein, hat das ReiserFS seine weite Verbreitung unter Linux zu verdanken. Dieses Dateisystem und die Erweiterung des ext2, das ext3 werden Sie im weiteren Text kennen lernen.
Die Entwicklungen von IBM und SGI sind zwar unterdessen ebenso verfügbar, werden aber (derzeit) kaum eingesetzt. Über die folgenden Sätze zu den maximal zulässigen Dateigrößen der einzelnen Journaling Dateisysteme hinaus, werden Sie keinen weiteren Hinweise zu diesen beiden Vertretern im Buch finden.
ext3, das sich an den Maßgaben des ext2 orientiert und den selben Beschränkungen unterliegt, ermöglicht somit maximal 4 TByte große Dateien. Gar mit stolzen 4 Petabytes (4*1015 Bytes) für einen einzelne Datei wartet IBM's jfs auf. Noch ganz andere Dimensionen schwebten den Entwicklern bei SGI vor. Ihr xfs soll immerhin 9 Exabytes (9*1018 Bytes) in eine Datei stopfen können. Und ReiserFS wird in zukünftigen Versionen 1025 Bytes handhaben können! Inwiefern die Angaben einen praktischen Nutzen haben, sei dahingestellt...
Das ReiserFS speichert die Daten in einem B-Baum (ein »Balanced«-Baum ist eine Verallgemeinerung der bekannten Binärbäume). Ein Element des Baumes wird als Knoten bezeichnet. Ein Knoten ist dabei als Wurzel ausgezeichnet, von dem aus alle weiteren Knoten erreichbar sind. Alle Knoten unterhalb eines bestimmten Knotens bilden einen Teilbaum und die maximale Anzahl von Knoten, die zu einem Blatt (unterster Knoten) führen, bezeichnet man als die Höhe des Teilbaums. Unterscheidet sich die minimale Anzahl von Knoten auf dem Weg von der Wurzel eines jeden Teilbaums hin zu einem Blatt von der maximalen Anzahl auf einem beliebigen anderen Weg höchstens um 1, so spricht man von einem balancierten Baum.
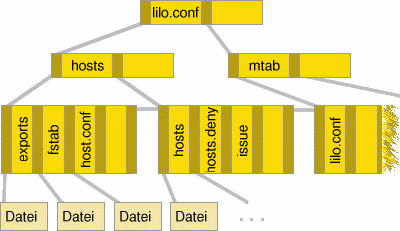
Abbildung 5: Die Baumstruktur eines ReiserFS
Ein Knoten des Baumes enthält nun die Suchschlüssel. Im Falle des ReiserFS werden die Dateinamen als Schlüssel verwandt. Innerhalb eines Knotens sind die enthaltenen Schlüssel aufsteigend sortiert und für jeden Schlüsselwert gilt, dass im Teilbaum, der durch den linken Zeiger referenziert wird, nur Schlüsselwerte gespeichert sind, die kleiner als dieser sind und im rechts angeordneten Zweig sind alle Schlüssel gleich oder größer.
Im Jargon des ReiserFS werden drei Typen von Knoten unterschieden:
Beispiel: Um die Datei hosts.deny aufzufinden, geht der Suchalgorithmus wie folgt vor: Die gesuchte Datei wird mit dem ersten Schlüsselwert aus dem Wurzelknoten verglichen. Ist er kleiner, wird im Baum, der über den links stehenden Zeiger referenziert wird, weiter gesucht. Ist der Wert gleich, so wird jeweils dem rechten Zeiger gefolgt. Ist er größer, so wird, falls vorhanden, der nächste Schlüssel im Knoten betrachtet und das Verfahren wiederholt sich. Im obigen Beispiel ist der Schlüsselwert »hosts.deny« kleiner als »lilo.conf«, also wird im linken Teilbaum gesucht. Der erste Wert dort »hosts« ist kleiner, also wird, da kein weiterer Wert im Knoten enthalten ist, rechts weiter gegangen. Im letzten Level der internen Knoten tritt beim zweiten Vergleich eine Übereinstimmung ein. Über den korrespondierenden Zeiger kann auf die Informationen der Datei zugegriffen werden.
Das Einfügen und Entfernen von Schlüsseln ist eine komplexe Angelegenheit und Gegenstand der theoretischen Informatik. Dennoch möchte ich versuchen, das Prinzip knapp zu präsentieren.
Beginnen wir mit dem Anlegen einer neuen Datei (ein Verzeichnis ist auch nur eine Datei...). Der Algorithmus beginnt wieder mit dem Vergleich (Kriterium ist der neue Dateiname) in der Wurzel und folgt den Zeigern bis zu der Position im untersten internen Knoten, der die neue Datei aufnehmen müsste. Ist im Knoten noch genügend Speicherplatz zur Aufnahme des neuen Schlüssels vorhanden, so wird dieser hier eingefügt. Dabei wird die alphabetische Anordnung beibehalten (durch Verschieben größerer Schlüssel nach rechts). Jetzt wird es irgendwann geschehen, dass der Belegungsgrad eines Knotens einen bestimmten Wert übersteigt (der Faktor hängt von der Konfiguration ab). Jetzt wird der Knoten zweigeteilt, wobei jede Hälfte die gleiche Anzahl Schlüssel erhält. Der neue »linke« Knoten (mit den kleineren Schlüsselwerten) ist schon im übergeordneten Knoten enthalten, nur der erste Schlüsselwert des neuen »rechten« Knotens muss noch im »Vater« aufgenommen werden. Also wiederholt sich dort das Spielchen, eventuell muss auch der Vaterknoten gesplittet werden. Sollte gar der Wurzelknoten überlaufen, so wird auch er geteilt und eine neue Wurzel erzeugt.
Der umgekehrte Weg wird beim Löschen eines Eintrages gegangen. Wird im untersten Knoten der Eintrag entfernt, muss zunächst überprüft werden, ob der Schlüssel nicht in den übergeordneten Knoten verwendet wird. Falls dem so ist, ist der dortige Schlüssel durch einen geeigneten anderen zu ersetzen. Weiterhin wird der Grad der Belegung mit den benachbarten Knoten verglichen und ggf. eine Vereinigung dieser veranlasst. Dies zieht weite Kreise, da nun im übergeordneten Knoten ein Schlüssel zu viel enthalten ist und dieses korrigiert werden muss.
Die Speicherung der Informationen zu Dateien und Verzeichnissen findet in den Blattknoten statt.
In der aktuellen Konfiguration existiert der Statuseintrag nicht eigenständig, sondern ist dem Datei-
bzw. Verzeichniseintrag zugeordnet.
Ein Verzeichniseintrag beinhaltet neben den Statusinformationen alle Schlüssel zu den enthaltenen
Dateien. In einem indirekten Eintrag stehen Zeiger auf unformatierte Knoten, die die Daten zu einer
Datei beinhalten. Im Unterschied zum ext2 sind diese Blöcke immer voll belegt, da das Ende einer
Datei in einem direkten Eintrag gespeichert ist (es sei denn, die Datei endet exakt auf einer
Blockgrenze).
Dem ReiserFS voran steht ein Informationsblock, der die notwendigen Angaben zum Auffinden des Journals und des Rootknotens enthält. Wenn ein Zugriff auf eine Datei erfolgt, wird diese zunächst in einer Hashtabelle gesucht. Ist die Blocknummer zu dieser Datei dort nicht enthalten, beginnt die Suche immer im Rootblock des Dateisystems. dumpreiserfs bringt die Strukturen des Dateisystems ans Licht:
|
root@sonne> dumpreiserfs /dev/hda3 <-----------DUMPREISERFS, 2000-----------> ReiserFS version 3.5.23 0x3:0x7's super block in block 16 ====================== Reiserfs version 0 Block count 787176 Blocksize 4096 Free blocks 454227 Busy blocks (skipped 16, bitmaps - 25, journal blocks - 8193 1 super blocks, 324714 data blocks Root block 11598 Journal block (first?) 18 Journal dev 0 Journal orig size 8192 Filesystem state ERROR Tree height 4 |
Bei der enormen Verbreitung des ext2-Dateisystems war es nur eine logische Konsequenz, dieses um die modernen Fähigkeiten eines Journaling Dateisystems nachzurüsten. Mit ext3, das ab Version 2.4.16 offiziell in den Kernel Einzug hielt, steht ein Dateisystem zur Verfügung, das zu 100% kompatibel mit allen Werkzeugen rund um das Dateisystem ext2 ist. Jedes ext2-Dateisystem kann ohne Risiko in ein ext3-System konvertiert werden (und umgekehrt), sodass Sie selbst bestehenden Dateisysteme ohne Neuinstallation die Journaling-Fähigkeit verleihen können.
Journaling meint im Allgemeinen die Protokollierung der Änderungen im Dateisystem. Im Speziellen können jedoch Änderungen an den Metadaten (Informationen zu einer Datei) und den Dateien (Inhalt der Dateien) gesondert behandelt werden. Das ext3-Dateisystem unterstützt deshalb gleich drei Journaling-Modi, die sich aus den Kombinationen dieser Handhabungen ergeben:
journal
ordered
writeback
Wenn Sie sich Vorteile davon versprechen, einen anderen als den Default-Journaling-Modus zu verwenden, dann müssen Sie nur beim Mounten des Dateisystems den gewünschten Modus angeben:
| root@sonne> mount -t ext3 -o data=writeback /dev/hdb9 /mnt |
| Spezielle Dateisysteme |
|
Wie oft haben Sie Linux bereits neu installiert und im Nachhinein dennoch fest gestellt, dass die von Ihnen gewählte Plattenpartitionierung doch nicht so optimal war? Sprengen die Daten nun die eine Partition?
Mit ein paar Handgriffen könnten Sie die Daten via Links auf andere Partitionen auslagern oder aber Sie könnten die Platte umpartitionieren. Eine Neuinstallation ist Dank geeigneter Programme nicht zwangsläufig notwendig.
Aber was, wenn diese Maßnahmen Ihren öffentlichen Webserver betreffen? Können Sie die notwendigen Wartungs- und Stillstandzeiten den Besuchern Ihrer Webseite zumuten?
LVM (Logical Volume Manager) könnte die Lösung solcher Probleme sein!
Der Zugriff auf die Partitionen einer Festplatte erfolgt in herkömmlicher Weise (also ohne LVM) über die Blockgerätedateien (/dev/hdax, /dev/hdbx,... , /dev/sdax,...). LVM greift nun nicht mehr direkt auf diese Gerätedateien zu, sondern verwendet eigene Treiber, sodass eine Entkopplung der Gerätedateien vom physikalischen Speichermedium erfolgt.
Die Architektur des Logical Volume Manager lässt sich somit ein drei Ebenen unterteilen. Die unterste Ebene bilden die physikalischen Speichermedien (Physical Volumes). Ein oder mehrere dieser Volumes gruppieren in der mittleren Ebene die virtuellen Platten (Volume Groups). Wiederum einer oder mehrerer dieser Volume Groups stehen in der oberen Ebene als virtuelle Partitionen zur Verfügung (Logical Volumes). Der Zugriff auf ein solche virtuelle Partition erfolgt über eine Blockgerätedatei.
Mit Physical und Logical Extents tauchen im Umgang mit LVM zwei weitere Begriffe auf, deren Erklärung die folgenden Abschnitte versuchen.
Physical Volume (PV)
Physical Extent (PE)
Volume Group (VG)
Logical Volume (LV)
Logical Extent (LE)
I.d.R. werden Sie Festplatten als Speichermedium für Ihr LVM-System verwenden. Die vorgesehenen Partitionen müssen Sie auf den Typ »0x8e« (Linux LVM) setzen, damit sie für LVM nutzbar werden. Das Setzen kann u.a. mit fdisk geschehen.
|
root@sonne> fdisk -l Platte /dev/hda: 40.0 GByte, 40020664320 Byte 255 Köpfe, 63 Sektoren/Spuren, 4865 Zylinder Einheiten = Zylinder von 16065 * 512 = 8225280 Bytes Gerät boot. Anfang Ende Blöcke Id Dateisystemtyp /dev/hda1 * 1 957 7687071 8e Linux LVM /dev/hda2 958 4865 31391010 5 Erweiterte /dev/hda5 958 990 265041 82 Linux Swap /dev/hda6 991 2296 10490413+ 8e Linux LVM |
Anmerkung: Wenn Sie die gesamte Festplatte als ein einziges Physical Volume betreiben, ist deren Formatierung mittels fdisk nicht zwingend erforderlich. Allerdings würde eine solche Partition weder unter /proc/partitions erscheinen noch bei »fdisk -l« angezeigt werden.
Hinweis: Zur Demonstration der weiteren Schritte wählen wir ein anderes Vorgehen. Anstatt ein LVM-System auf Festplatten(partitionen) einzurichten, legen wir uns einige hinreichend große Dateien an, verwenden diese als Loopback-Dateien und setzen darauf LVM auf. Somit bleibt das Risiko, irgendetwas an unserer Linuxinstallation zu ruinieren, relativ gering.
Folgende Kommandos richten acht Loopback-Dateien zu je 100MB ein:
|
root@sonne> for ((i=0; i < 8; i++)); do > dd if=/dev/zero of=/tmp/lvm_loop$i bs=1024 count=100k > losetup /dev/loop$i /tmp/lvm_loop$i > done 102400+0 Records ein 102400+0 Records aus ... |
Wenn Sie die Loopback-Dateien nicht mehr benötigen, müssen Sie vor derem Löschen die Verbindung zur Gerätedatei lösen:
| root@sonne> losetup -d /dev/loop0 |
| pvcreate [Optionen] PhysicalVolume [PhysicalVolume] |
Mit pvcreate bereiten Sie eine Partition (alternativ die gesamte Festplatte oder eine Loopback-Datei) zur Verwendung durch LVM vor. Die möglichen Optionen dienen im Wesentlichen der Ausgabesteuerung und sind nur in seltenen Fällen sinnvoll.
In unserem Beispiel initialisieren wir die sechs mit den Loopback-Dateien verbundenen Gerätedateien:
|
root@sonne> pvcreate /dev/loop{0,1,2,3,4,5} pvcreate -- physical volume "/dev/loop0" successfully created pvcreate -- physical volume "/dev/loop1" successfully created ... root@sonne> pvdisplay /dev/loop0 pvdisplay -- "/dev/loop0" is a new physical volume of 100 MB |
Das Kommando pvdisplay zeigt im Moment noch nicht allzu viele Informationen, da die Verwaltungsstruktur erst bei der Integration eines Physical Volumes in eine Volume Group mit sinnvollen Werten belegt wird (vergleiche nächster Schritt).
| vgcreate [-l max-LV] [-p max-PV] [-s PE-Größe] VG-Name PhysicalVolume [PhysicalVolume] |
Eine oder mehrere der Physical Volume werden mittels vgcreate zu einer Physical Group zusammengefasst. Wichtig ist die Angabe des eindeutigen Namens für die Volume Group, der als Verzeichnisname unterhalb von »/dev« erscheint. In diesem Verzeichnis landen später die Informationen zu den aufsetzenden Logical Volumes.
Von den weiteren Optionen des Kommandos kommen dreien eine gewisse Bedeutung zu. Mit
»-l max-LV« bzw. »-p max-PV« können Sie die Grenzen für die maximal
zulässige Anzahl enthaltener Logical bzw. Physical Volumes herunter setzen. In der Voreinstellung betragen
beide Werte 256, was für viele Anwendungen zu hoch gegriffen ist und letztlich durch Verwaltungsstrukturen
nur Plattenplatz verschwendet. Beachten Sie aber, dass eine Reduzierung unumkehrbar ist und nur durch Löschen
und Neuanlegen der Volume Group korrigiert werden kann.
Die Größe eines Physical Extents können Sie mit »-s PE-Größe« anpassen
(zwischen 8KB und 16GB in Zweierpotenzen). Da maximal ca. 64k Extents in einem Logical Volume verwaltet werden
können, beeinflusst dieser Wert letztlich die Speicherkapazität (max. 2TB).
Für unser Beispiel fassen wir sechs Physical Extents zu einer Volume Group zusammen, wobei wir die Defaultwerte beibehalten:
|
root@sonne> vgcreate vg_demo0 /dev/loop{0,1,2,3,4,5} vgcreate -- INFO: using default physical extent size 32 MB vgcreate -- INFO: maximum logical volume size is 2 Terabyte vgcreate -- doing automatic backup of volume group "vg_demo0" vgcreate -- volume group "vg_demo0" successfully created and activated |
vgcreate belegt das Volume Group Descriptor Area der eingeschlossenen Physical Volumes mit konkreten Werten:
|
root@sonne> pvdisplay /dev/loop0 --- Physical volume --- PV Name /dev/loop0 VG Name vg_demo0 PV Size 100 MB [204800 secs] / NOT usable 32.19 MB [LVM: 128 KB] PV# 1 PV Status NOT available Allocatable yes Cur LV 0 PE Size (KByte) 32768 Total PE 2 Free PE 2 Allocated PE 0 PV UUID 2gOYAB-bXBc-uEdx-SUs4-24aW-I6Th-pHS7pu |
Mit vgdisplay bringen Sie die Informationen der gesamten Volume Group zum Vorschein:
|
root@sonne> vgdisplay --- Volume group --- VG Name vg_demo0 VG Access read/write VG Status available/resizable VG # 0 MAX LV 256 Cur LV 0 Open LV 0 MAX LV Size 2 TB Max PV 256 Cur PV 6 Act PV 6 VG Size 384 MB PE Size 32 MB Total PE 12 Alloc PE / Size 0 / 0 Free PE / Size 12 / 384 MB VG UUID QZIbE7-jmoQ-CkTD-S3Qb-mMvX-6OEG-0Pt9W0 |
Wenn Sie die Kapazitäten der verwendeten sechs Loopback-Dateien aufsummieren, erhalten Sie 600MB. Tatsächlich sind in unserer Beispiel-Volume-Group ganze 384 MB zur Datenaufnahme verfügbar. Woher dieser Diskrepanz? Ganz einfach... wir haben zu kleine Größen für die Physical Volumes angesetzt, sodass unverhältnismäßig viele Verwaltungsdaten anfallen. Pro Physical Volume werden ca. 32 MB für die Verwaltung benötigt. Bleiben noch runde 68MB übrig, von denen wegen der gewählten Physical-Extent-Größe von 32 MB allerdings auch nur 64 MB nutzbar sind. Bei realem Einsatz von LVM sollten Sie also die Physical Volumes wesentlich größer dimensionieren.
| lvcreate [-n LV-Name] -L LV-Größe VG-Name |
Die zuvor erzeugte Volume Group präsentiert sich quasi als unformatierte Festplatte. Das Anlegen der Logical Volumes auf dieser kommt einer Partitionierung gleich. Neben dem Namen der zu verwendenden Volume Group ist die Angabe der Größe des Logical Volume mittels »-L LV-Größe« erforderlich. Optional können Sie den Namen für dieses Logical Volume festlegen (»-n LV-Name«). Verzichten sie darauf, wird automatisch ein Name generiert.
Jedes Logical Volume erscheint unter seinem Namen im Verzeichnis der betreffenden Volume Group (im Beispiel unterhalb von »/dev/vg_demo0«).
Zur Demonstration unterteilen wir die Volume Group in zwei Logical Volume mit 200 bzw. 184 MB Kapazität:
|
root@sonne> lvcreate -L200 -n lv_demo0 vg_demo0 lvcreate -- rounding size up to physical extent boundary lvcreate -- doing automatic backup of "vg_demo0" lvcreate -- logical volume "/dev/vg_demo0/lv_demo0" successfully created root@sonne> lvcreate -L184 -n lv_demo1 vg_demo0 lvcreate -- rounding size up to physical extent boundary lvcreate -- only 5 free physical extents in volume group "vg_demo0" |
Offensichtlich ging beim Anlegen des zweiten Logical Volumes etwas schief. Warum? Weil für die ersten angeforderten 200 MB die Reservierung von sieben Physical Extents notwendig wurden und damit nur noch fünf Extents (160 MB) übrig bleiben. Wir nutzen also die verbliebenen Extents für das zweite Volume:
|
root@sonne> lvcreate -L160 -n lv_demo1 vg_demo0 lvcreate -- doing automatic backup of "vg_demo0" lvcreate -- logical volume "/dev/vg_demo0/lv_demo1" successfully created |
Mit dem Kommando lvdisplay holen Sie Informationen zu einem Logical Volume hervor:
|
root@sonne> lvdisplay /dev/vg_demo0/lv_demo0 --- Logical volume --- LV Name /dev/vg_demo0/lv_demo0 VG Name vg_demo0 LV Write Access read/write LV Status available LV # 1 # open 0 LV Size 224 MB Current LE 7 Allocated LE 7 Allocation next free Read ahead sectors 1024 Block device 58:0 |
Ihre neu erzeugten Logical Volumes können Sie analog zu Partitionen der Festplatten benutzen. Nachdem Sie auf ihnen ein Dateisystem erzeugt und dieses gemountet haben, können Sie wie gewohnt Ihre Dateien darauf ablegen. LVM kümmert sich für Sie um die Verteilung der Daten auf die vorhandenen Physical Volumes.
Mit folgenden Schritten formatieren wir unsere beiden Logical Volumes mit einem ext3-Dateisystem:
|
root@sonne> mkfs -t ext3 /dev/vg_demo0/lv_demo0 mke2fs 1.28 (31-Aug-2002) Filesystem label= OS type: Linux ... root@sonne> mkfs -t ext3 /dev/vg_demo0/lv_demo1 ... |
Als Ziel des Mountens erzeugen wir uns zwei Verzeichnisse unterhalb von /mnt und hängen die Logical Volumes dort ein:
|
root@sonne> mkdir /mnt/lvm_demo{0,1} root@sonne> mount /dev/vg_demo0/lv_demo0 /mnt/lvm_demo0 root@sonne> mount /dev/vg_demo0/lv_demo1 /mnt/lvm_demo1 root@sonne> df -h | grep -B 1 lvm /dev/vg_demo0/lv_demo0 217M 4,1M 202M 2% /mnt/lvm_demo0 /dev/vg_demo0/lv_demo1 155M 4,1M 143M 3% /mnt/lvm_demo1 |
Seine Stärken offenbart LVM erst, wenn die Kapazität des aktuellen Systems erweitert werden muss. Wenn Sie Plug&Play-fähige Hardware einsetzen (bspw. SCSI-Platten), dann ist nicht einmal eine Unterbrechung des laufenden Systems erforderlich. Vorrausgesetzt natürlich, es existieren Werkzeuge, die das aufgesetzte Dateisystem »on the fly« erweitern können.
Angenommen, Sie spendieren ihrem System eine neue Platte, so sollten Sie diese zunächst per fdisk partitionieren und die Partitionen mittels pvcreate als Physical Volumes initialisieren. Gehen Sie also genau vor, wie zu Beginn des Abschnitts beschrieben.
Anschließend verwenden Sie das Kommando vgextend, um die neuen Physical Volumes in die Volume Group zu integrieren.
| vgextend VG-Name PhysicalVolume [PhysicalVolume] |
In unserem Beispiel verwenden wir eine weitere Loopback-Datei, um die Volume Group zu vergrößern:
|
user@sonne> dd if=/dev/zero of=/tmp/lvm_loop6 bs=1024 count=200k 204800+0 Records ein 204800+0 Records aus root@sonne> losetup /dev/loop6 /tmp/lvm_loop6 root@sonne> pvcreate /dev/loop6 pvcreate -- physical volume "/dev/loop6" successfully created root@sonne> vgextend vg_demo0 /dev/loop6 vgextend -- INFO: maximum logical volume size is 2 Terabyte vgextend -- doing automatic backup of volume group "vg_demo0" vgextend -- volume group "vg_demo0" successfully extended |
In der erweiterten Volume Group könnten Sie nun ein neues Logical Volume anlegen oder aber ein bestehendes mit Hilfe des Kommandos lvextend erweitern.
| lvextend -L [+]LV-Größe VG-Name [PhysicalVolume] |
Als neue Größe können Sie sowohl den absoluten Wert als auch den Betrag der Erweiterung angeben. In der Volume Group müssen genügend freie Physical Extents vorhanden sein. Mit der Angabe der Namens eines Physical Volumes können Sie explizit Einfluss auf die Verwendung dieses nehmen. Ohne die Angabe wird das erste freie gwählt. Das Physical Volume muss in der Volume Group vorhanden sein.
|
root@sonne> lvextend -L+160M /dev/vg_demo0/lv_demo0 vextend -- extending logical volume "/dev/vg_demo0/lv_demo0" to 384 MB lvextend -- doing automatic backup of volume group "vg_demo0" lvextend -- logical volume "/dev/vg_demo0/lv_demo0" successfully extended |
Zum Abschluss müssen Sie das Dateisystem der betreffenden Logical Volume vergröszlig;ern. Im Falle von ext2/ext3 könnten Sie resize2fs auf dem nicht-gemounteten (!) Dateisystem anwenden.
Anstatt die beiden letztgenannten Schritte separat auszuführen, bringt das LVM-Paket das Kommando e2fsadm mit, das die Schritte lvextend und resize2fs zusammenfasst.
Zum Verkleinern eines LVM-Systems müssen Sie in umgekehrter Reihenfolge vorgehen, d.h. Sie müssen zunächst das aufgesetzte Dateisystem, dann das Logical Volume mittels lvreduce und anschließend die Volume Group mittels vgreduce verkleinern. Im Falle eines ext2/ext3-Dateisystem kann die Schritte der Dateisystemreduzierung und von lvreduce wiederum e2fsadm übernehmen.Zum Entfernen der einzelnen Volumes benötigen Sie folgende drei Befehle:
|
lvremove LogicalVolume [LogicalVolume] vgchange [Optionen ]VG-Name [VG-Name] vgremove VG-Name [VG-Name] |
Die Physical Volumes müssen nicht explizit entfernt werden; verwenden Sie die zugrunde liegenden Partitionen einfach nach Bedarf.
Zum Löschen des Logical Volumes darf dieses nicht gemountet sein:
|
root@sonne> lvremove /dev/vg_demo0/lv_demo0 lvremove -- can't remove open logical volume "/dev/vg_demo0/lv_demo0" root@sonne> umount /mnt/lvm_demo0 /mnt/lvm_demo1 root@sonne> lvremove /dev/vg_demo0/lv_demo0 /dev/vg_demo0/lv_demo1 lvremove -- do you really want to remove "/dev/vg_demo0/lv_demo0"? [y/n]: y lvremove -- doing automatic backup of volume group "vg_demo0" lvremove -- logical volume "/dev/vg_demo0/lv_demo0" successfully removed lvremove -- do you really want to remove "/dev/vg_demo0/lv_demo1"? [y/n]: y lvremove -- doing automatic backup of volume group "vg_demo0" lvremove -- logical volume "/dev/vg_demo0/lv_demo1" successfully removed |
Sollten Sie jetzt versuchen, im nächsten Schritt die Volume Group zu löschen, wird Ihr Bemühen mit einer Fehlermeldung quittiert werden:
|
root@sonne> vgremove vg_demo0 vgremove -- ERROR: can't remove active volume group "vg_demo0" |
Eine Volume Group kann nur entfernt werden, wenn sie keine Logical Volumes mehr enthät und - der Grund für obiges Scheitern - sie sich im inaktiven Zustand befindet. Zum Ändern des Zustands benötigen Sie das Kommando vgchange:
|
root@sonne> vgchange -a n vg_demo0 vgchange -- volume group "vg_demo0" successfully deactivated |
Ohne Angabe des Volumen-Group-Names wirkt das Kommando auf alle Volume Groups. Zur Aktivierung einer Volume Group dient die Option »-a y«.
Jetzt sollte das Entfernen der Volume Group gelingen:
|
root@sonne> vgremove vg_demo0 vgremove -- volume group "vg_demo0" successfully removed |
Dem Sinn oder Unsinn, der Theorie und Praxis der Verschlüsselung von Daten haben wir ein eigenes Kapitel Sicherheit gewidmet. Wie gehen an dieser Stelle nicht explizit darauf ein, warum ein verschlüsseltes Dateisystem für Sie in Frage käme. Wie konzentrieren uns hier einzig auf das Wie der Konfiguration.
Aus Lizenzrechtlichen oder Sicherheitsgründen enthalten aktuelle Kernel oft nur wenige kryptografischen Algorithmen. Theoretisch werden alle in der Manpage zu lopsetup genannten Algorithmen unterstützt. Der SuSE-Kernel bringt allerdings einzig den Twofish-Algorithmus mit sich, weshalb wir im weiteren Text einzig diesen betrachten.
Der Twofish-Algorithmus liegt den SuSE-Kerneln als Modul bei. Falls noch nicht bereits geschehen, muss dieses vorab geladen werden:
| root@sonne> lsmod | grep loop_fish2 || modprobe loop_fish2 |
Kann das Modul nicht gefunden werden, kommen Sie um einen neuen Kernel nicht umhin. Abbildung 6 zeigt die auszuwählenden Optionen aus dem Menü Block devices.
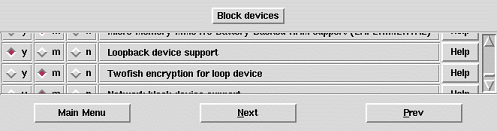
Abbildung 6: Kerneloptionen für die twofish-Verschlüsselung
Aus der Abbildung 6 ist ersichtlich, dass die Verschlüsselung von Dateisystemen nur über das Loopback-Device funktioniert. Dies stellt aber keine Einschränkung dar, sondern ermöglicht sogar die Verwendung einer Datei anstatt einer Partition als Dateisystem. Wie demonstrieren das weitere Vorgehen daher anhand einer Loopback-Datei, die folgender Befehl erstellt:
|
root@sonne> dd if=/dev/zero of=/kryptofs bs=1024 count=1024 1024+0 Records ein 1024+0 Records aus |
Der einzige Unterschied zur Verwendung unverschlüsseltere Loopback-Dateien ist nun die Angabe des zu verwendenden Verschlüsselungsalgorithmus beim Aktivieren des Loopback-Devices:
|
root@sonne> losetup -e twofish /dev/loop1 /kryptofs Password: |
Sie werden zur Eingabe eines Passworts aufgefordert. Wählen Sie dieses gewissenhaft aus und vor allem... vergessen Sie es niemals. Sie haben weder eine Möglichkeit das Passwort zu ändern noch an die Daten zu gelangen, sollte Ihnen das Passwort abhanden gekommen sein.
Vor der Verwendung der Loopback-Datei müssen Sie dieses mit dem Dateisystem Ihrer Wahl formatieren:
|
root@sonne> mke2fs /dev/loop1 mke2fs 1.28 (31-Aug-2002) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) 5016 inodes, 20000 blocks 1000 blocks (5.00%) reserved for the super user First data block=1 3 block groups 8192 blocks per group, 8192 fragments per group 1672 inodes per group Superblock backups stored on blocks: 8193 Writing inode tables: done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 33 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override. |
Um das Loopback-Device freizugeben, sollten Sie zum Abschluss folgenden Befehl ausführen:
| root@sonne> losetup -d /dev/loop1 |
Zum Verwenden des verschlüsselten Dateisystems müssen Sie dieses an eine beliebige Position des Root-Dateisystems mounten. Prinzipiell kann dies bereits beim Booten des Systems erfolgen. Jedoch ist hiervon abzuraten, da das Mounten stets die Eingabe des Passwortes erfordert und der Bootvorgang solange unterbrochen wird.
Ohne Eintrag in die Datei /etc/fstab bleibt das Mounten dem Systemverwalter vorbehalten. Der korrekte Aufruf müsste folgendermaßen aussehen:
|
root@sonne> mkdir -p /mnt/kryptofs root@sonne> mount -t ext2 -o loop,encryption=twofish /kryptofs /mnt/kryptofs Password: |
Um allen Benutzern das Mounten zu ermöglichen, insofern Sie Kenntnis vom Passwort haben, muss die Datei /etc/fstab um folgende Zeile ergänzt werden:
|
root@sonne> vi /etc/fstab ... /kryptofs /mnt/kryptofs ext2 loop,encryption=twofish,noauto,user 0 0 |
Wie der Name schon andeutet, handelt es sich um Dateisysteme, die im RAM-Speicher liegen. Stark verbreitet sind solche RAM-Dateisysteme bspw. bei so genannten Embedded Systemen, die beim Start ein äußerst schlankes Betriebssystem zumeist aus einem ROM-Speicher in eine RAM-Disk entpacken und diese RAM-Disk als ihr Dateisystem verwenden. Auch aktuelle Linuxkernel werden häufig so konfiguriert, dass sie zunächst auf einem RAM-Dateisystem (Initial-Ramdisk) starten, dort gewisse Systeminitialisierungen vornehmen und erst anschließend auf die Dateisysteme der Festplatten zugreifen. Im Zusammenhang mit letzerem Verfahren finden Sie im Abschnitt Systemadministration, Booten eine ausführliche Einführung.
Ein weiterer Aspekt ist der enorme Geschwindigkeitsvorteil, den ein RAM-Dateisystem gegenüber Dateisystemen auf Festplatten besitzt. Bspw. arbeiten zahlreiche Programme mit temporären Dateien, die sie zumeist im Verzeichnis »/tmp/« anlegen. Da das Verzeichnis /tmp nach Filesystem-Hierarchie-Standard ohnehin keine Daten über einen Systemstart hinweg sichern muss, ist dieses ein geeigneter Kandidat für die Realisierung in einem RAM-Dateisystem.
RAM-Dateisysteme existieren in mehreren Variationen. Jede besitzt ihre Stärken und Schwächen und damit ihren besonderen Einsatzbereich. Wir verfolgen im weiteren Text speziell das tmpfs. Im Unterschied zu den meisten RAM-Dateisystem kann tmpfs sowohl RAM als auch den Swap-Speicher zur Datenablage verwenden, deshalb finden Sie auch oft den Begriff des Virtuellen Speicher Dateisystems.
Der Linuxkernel ist für die Verwaltung des virtuellen Speichers allein verantwortlich. D.h. tmpfs tut letztlich nichts anderes, als Seiten des virtuellen Speichers vom Kernel anzufordern. Das Dateisystem selbst hat weder Kenntnis noch Einfluss darauf, ob eine Seite aktuell im RAM oder im Swap liegt. Je nach Speicherauslastung wird die Speicherverwaltung des Kernels Seiten bei Bedarf in den RAM ein- oder aus dem RAM auslagern.
Das tmpfs selbst ist als Bestandteil des Virtuellen-Speicher-Subsystems realisiert und ist damit im Unterschied zu den sonstigen RAM-Dateisystemen kein Blockgerät, d.h. es erscheint weder als Gerätedatei im Verzeichnis /dev noch muss explizit ein Dateisystem auf diesem erzeugt werden.
Daraus erwächst letztlich ein enormer Vorteil: Die Gröszlig;e des Dateisystem passt sich dynamisch den Erfordernissen an. Sie ist intitial relativ klein und wächst und sinkt mit dem Speichern und Löschen von Dateien. Beachten sollten Sie allerdings, dass RAM und Swap entsprechend großzügig dimensioniert sein sollten.
Sie benötigen einen Kernel mit Unterstützung für das tmpfs. Schauen Sie in der Datei »/proc/filesystems« nach, ob ein Eintrag nodev tmpfs existiert. Wenn nicht, kommen Sie um eine Kernelübersetzung nicht umhin. Wichtig ist der in Abbildung 7 zu sehende aktivierte Eintrag Virtual memory file system support (former shm fs):
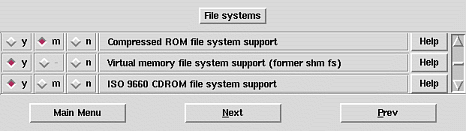
Abbildung 7: Kerneloption für das Virtuelle Speicher Dateisystem
Zum Erzeugen genügt ein simpler Mount-Aufruf mit einem existierenden Mountpunkt:
|
root@sonne> test -d /mnt/tmpfs || mkdir /mnt/tmpfs root@sonne> mount tmpfs -t tmpfs /mnt/tmpfs |
So einfach obiges Verfahren ist, so gefährlich ist es auch. Die Größe des Dateisystems könnte nun wachsen bis der Virtuelle Speicher erschöpft ist. Tritt dieser Fall jedoch ein, ist der Kernel gezwungen, Speicher freizuräumen, er wird einen speicherintensiven Prozess auswählen und beenden. Vermutlich werden Sie mit dem System nicht mehr vernünftig arbeiten können...
Deshalb sollten Sie dem Dateisystem eine Obergrenze setzen. Wie hoch diese ist, hängt letztlich von der Auslastung Ihres Systems ab. Beobachten Sie eine Zeit lang die Entwicklung der Speicherbedarfs und verwenden Sie für tmpfs höchstens so viel, wie bei maximaler Auslastung (Summe aus RAM und Swap) noch übrig blieb. Geben Sie den ermittelten Wert beim Mounten des Dateisystems an und es wird niemals diese Grenze überschreiten:
| root@sonne> mount tmpfs /mnt/tmpfs -t tmpfs -o size=128M |
Im Beispiel verwendeten wir ein neues Verzeichnis als Mountpunkt. Hätten wir /tmp benutzt, hätten wir vermutlich einigen Programmen ihrer temporären Dateien beraubt. Sie hätten es uns sicher übel genommen. Um tmpfs für /tmp zu nutzen, müssen Sie dieses noch während des Bootens mounten. Am eifachsten ist ein Eintrag in die Datei /etc/fstab:
|
root@sonne> grep tmpfs /etc/fstab tmpfs /tmp tempfs size=128m 0 0 |
Dieser Fall dürfte in den meisten aktuellen Distributionen noch Gang und Gäbe sein, da aufgrund des experimentellen Status der Device-Dateisystem-Entwicklung und gewisser Hürden bei der Migration auf den Einsatz (noch) verzichtet wird.
Sie müssen nur einmal einen Blick in das Verzeichnis »/dev« werfen, um ein grobes Gefühl vom Wirrwarr mit den Gerätetreibern zu erlangen. Typischer Weise werden sie mehrere hundert Dateien vorfinden, die die Hardwaretreiber im Dateisystem repräsentieren. Programme werden i.d.R. mit Hilfe dieser Datei mit den Geräten kommunizieren, anstatt die relativ komplexe Schnittstelle der Hardware direkt anzusprechen.
Jede diese Gerätedateien verfügt über zwei Nummern, die Major Number und die Minor Number. Wenn ein Treiber sich beim Kernel registriert, dann teilt er diesem eine Nummer mit, die den Treiber eindeutig identifiziert. Die Major Number der Datei deckt sich mit dieser Nummer des Treibers. Ein Treiber wiederum vermag mitunter mehrere Geräte kontrollieren. Welches aktuell zu verwenden ist, besagt letztlich die Minor Number der Datei. Beachten Sie, dass für zeichen- und blockweise arbeitende Geräte trotz identischer Nummern unterschiedliche Treiber verwendet werden. Major Number und Minor Number adressieren letztlich einen Satz von Dateioperationen, über die mit der Hardwarekomponente kommuniziert werden kann.
Warum existieren derer so viele? Weil die aktuellen Linuxkernel halt so viel unterschiedliche Hardware unterstützen. Und jedes neue Gerät, für das ein neuer Linuxtreiber geschrieben werden sollte, wird sich mit einer neuen Datei repräsentieren, insofern der Treiber es zum offiziellen Bestandteil des Kernels schafft.
Sind wirklich alle Dateien notwendig? Eigentlich nein. Aber die Distributoren haben letztlich keine Kenntnis, welche Hardware auf dem installierten System vorhanden ist. Deshalb ist es für sie am einfachsten, alle bekannten Gerätedateien mit Hilfe des Programmes »MAKEDEV« vorab anzulegen. Prinzipiell wäre es denkbar mittels eines Programmes nach nicht verfügbaren Treibern zu scannen und die zugehörigen Gerätedateien zu entfernen. Jedoch würde damit der nachträgliche Einbau von Hardware oder auch nur das nachträgliche Laden von Modulen erschwert, da in solchen Situationen (bspw. beim Anstecken eines USB-Sticks) die Gerätedateien zu erzeugen wären.
Die Identifizierung von Treibern über Major und Minor Numbers hat noch weitere Schwächen. Ein akutes Problem ist die beschränkte Anzahl der Nummern (8 Bit), sodass bei der Fülle heutiger Treiber die 128 Major und 128 Minor Numbers kaum mehr ausreichen. Für SCSI-Geräte führte das schon dazu, dass mehrere Major Numbers für diese reserviert werden mussten. Theoretisch wäre eine Erweiterung auf 16-Bit Nummern denkbar, was aber zu extrem großen Datenstrukturen im Kernel führen würde, um Einsprungspunkte für alle Treiber zu verwalten (derzeit geht das über eine Tabelle mit 128 Einträgen; bei 16 Bit müsste diese Tabelle 32768 Einträge umfassen).
Zunächst einmal handelt es sich um ein eigenes Dateisystem. Es existiert, sobald dieses in den Kernel einkompiliert wurde. Es kann an beliebiger Position ins Dateisystem eingehangen werden; üblich ist jedoch »/dev« als Mountpunkt. Selbst wenn das Device-Dateisystem nicht gemountet ist, existiert es mitsamt seiner Einträge, sodass die Treiber stets verfügbar sind.
Der Inhalt des Device-Dateisystems wird nicht auf Festplatte gespeichert, d.h. bei einem Neustart des Systems muss der Kernel die Hardware selbstätig erkennen und initialisieren. In einer frühen Phase des Starts wird der Kernel hierzu die Initialisierungsroutinen der fest einkompilierten Treiber aufrufen. Über Kommandozeilenoptionen des Kernels ist das Verhalten dieser Routinen sogar beeinflussbar. Der jeweilige Treiber registriert sich über seinen Namen beim Kernel. Im Falle von Hardwaretreibern wird die Registrierung scheitern, falls das Gerät nicht vorhanden ist. Ist sie erfolgreich, erzeugt die Registrierungsroutine unter dem Namen des Treibers einen Eintrag im Device-Dateisystem und vermerkt, dass diese Datei zum soeben im Kernel registrierten Treiber gehört. Die zugehörigen Dateioperationen stehen nun direkt im Dateisystemeintrag anstatt in einer kernelinternen Tabelle.
Dieser Registrierung erfolgt analog beim Laden von Modulen. Beim Entfernen von fest einkompolierten oder als Modul realisierten Treibern verschwinden auch die Einträge aus dem Devivce-Dateisystem.
Wenn nun eine Anwendung auf einen Eintrag des Device-Dateisystems zugreift, dann könnte es sein, dass dieser nicht existiert, weil der zugehörige Treiber als Modul realisiert und noch nicht geladen wurde. In diesem Fall veranlasst das Device-Dateisystem automatisch das Laden der relevanten Module und der angeforderte Eintrag wird erzeugt (hierzu muss der devfsd aktiv und entsprechend konfiguriert sein; siehe weiterer Text).
Die aktuelle Implementierung des Device-Dateisystems umfasst einen Device Mangement Daemon devfsd, der weitere Aufnahmen wahrnimmt. Diesem Daemon können bei Ereignissen wie bspw. der Registrierung eines Treibers Nachrichten gesandt werden, die ihn zu bestimmten Aktionen veranlassen. So vermag er die Zugriffsrechte der Einträge im Device-Dateisystem ebenso zu ändern, wie Programme aufzurufen, um bspw. ein Dateisystem zu mounten, wenn eine Diskette ins Laufwerk eingelegt wurde.
Da bei weitem noch nicht alle Treiber auf Verwendung des neuen Device-Dateisystems umgestellt wurden, ist es zweckmäßig, den devfsd zu starten, der automatisch benötigte Gerätedateien nach altem Schema im Device-Dateisystem erstellt. Hierzu muss dieses jedoch gemountet sein. Alternativ könnten Sie solche Einträge auch per Hand erstellen, falls Sie nichts besseres zu tun haben...
Warnung: Der Umstieg ist alles andere als trivial und kann Ihr System im schlimmsten Fall unbrauchbar machen.
Wie anfangs angedeutet, haben die aktuellen Distributionen in ihren Kerneln die Unterstützung für das Device-Dateisystem deaktiviert. Sie kommen um die Konfiguration eines neuen Kernels nicht umhin.
Hierzu muss zunächst unter Code maturity level options die Option Prompt for development and/or incomplete code/drivers aktiviert werden, um die notwendigen Auswahlen freizuschalten.
Im Menü File systems muss mindestens die Option /dev file system support (EXPERIMENTAL) angeschaltet werden
(Abbildung 8). Das Dateisystem automatisch vom Kernel mounten zu lassen (Automatically mount at boot) muss nicht immer eine
gute Idee sein. Nämlich dann nicht, wenn Sie die Rechte an Einträgen ändern und diese einen Reboot überdauern
sollen. Den Mountvorgang können Sie ebenso gut in einem Startskripte oder gar in der /etc/fstab
unterbringen.
Die Option für erweiterte Debug-Ausgaben sollten Sie nicht aktivieren, es sei denn Sie mögen etwas Aktivität auf
der Konsole.
Abbildung 8: Kerneloption für das Device-Dateisystem
Da das Device-Dateisystem die Pseudoterminals (/dev/pts) selbst verwaltet, sollten sie die Option /dev/pts file system for Unix98 PTYs entweder deaktivieren oder einfach dessen Mounten verhindern, indem Sie den Eintrag aus /etc/fstab entfernen.
|
root@sonne> grep devpts /etc/fstab #devpts /dev/pts devpts mode=0620,gid=5 0 0 |
Da die Zugangskontrolle fü den Systemverwalter root heute meist über die Pluggable Authentication Modules realisiert ist und PAM ein Problem mit symbolischen Links hat, muss die Datei /etc/securetty um Einträge ergänzt werden, die den direkten Zugriff auf die Gerätedateien ermöglichen (anstatt über Links):
|
root@sonne> vi /etc/securetty # # This file contains the device names of tty lines (one per line, # without leading /dev/) on which root is allowed to login. # tty1 tty2 ... tty6 # for devfs: vc/1 vc/2 ... vc/6 |
Das weitere Vorgehen ist ziemlich trickreich und funktioniert erst mit Kerneln ab Version 2.4.0.
Wir nehmen an, dass sich mit hoher Wahrscheinlichkeit in Ihrem System noch ältere Treiber tummeln, auf deren Verwendung Sie angewiesen sind. Da für etliche Gerätedateien die Rechte anzupassen sind, um sie für den »normalen« Benutzer verfügbar zu machen, wären Sie sicherlich nicht ganz unglücklich, wenn solche Änderungen einen Neustart des Systems überdauern würden. D.h. nichts anderes als das die Modifikationen auf die Festplatte gespeichert werden müssen. Doch wohin?
Nach /dev! Dieses Verzeichnis existiert ja weiterhin, es wird nur durch das Mounten von devfs unsichtbar. Aber mit der Bind-Eigenschaft neuerer Versionen des Virtuellen Dateisystems kann der Zugang zum »alten« Inhalt bewahrt werden.
Der Trick ist nun, dass wir den Zugriff auf den alten Inhalt erhalten, indem wir das Verzeichnis /dev vor dem Mounten des Device-Dateisystems an eine andere Position im Dateisystem via bind mounten. Erst anschließend wird das Device-Dateisystem auf /dev eingehangen und der Device Mangement Daemon gestartet. Der Daemon wird nun seine Änerderungen permanent an der neuen Mountposition speichern.
Die soeben beschriebenen Schritte sollten so früh wie möglich während des Bootprozesses vorgenommen werden. Welches Skript dafür in Frage kommt, differiert bei den verschiedenen Distributionen. Schauen Sie hierzu in der Datei /etc/inittab nach (bei aktuellen SuSE-Distributionen ist es die Datei /etc/rc.d/boot). Ergänzen Sie das Skript um folgende Einträge:
|
# Beispiel gilt nur für SuSE 8.2! root@sonne> vi /etc/rc.d/boot # ...ziemlich zu Beginn des Skripts mkdir -p /dev-state mount --bind /dev /dev-state mount -t devfs none /dev devfsd /dev ... |
Die Konfiguration erfolgt in der Datei »/etc/devfsd.conf«. Die im Paket ausgelieferte Version sollte alle relevanten Einträge umfassen, nur sind sie zum Teil auskommentiert.
Eine Zeile der Konfigurationsdatei umfasst stets drei Spalten:
| Ereignis Device Aktion |
Die reservierten Bezeichner für Ereignis sind zumeist selbsterklärend. Mögliche Werte sind REGISTER, UNREGISTER, CREATE, DELETE, CHANGE, RESTORE und LOOKUP. Das Ereignis LOOKUP tritt ein, wenn irgendein Prozess einen Eintrag aus dem Device-Dateisystem öffnet.
Die zweite Spalte benennt die Devices, für die die Zeile relevant ist. Hier dürfen auch Reguläre Ausdrücke Verwendung finden.
In Spalte drei steht die Aktion, die beim Eintreten des Ereignissen für die angegebenen Devices auszuführen ist. Eingeleitet wird eine Aktion durch ein Schlüsselwort. Für verschiedene Ereignisse sind verschiedene Schlüsselworte zulässig. Manche Schlüsselworte erfordern weitere Argumente, bspw. irgendwelche Kommandoaufrufe. Wegen der Fülle der erlaubten Einträge verzichten wir auf eine detaillierte Vorstellung und verweisen auf die folgenden Beispiele.
Die folgenden Fragmente aus der Datei sind Empfehlungen. Wir erlätern ihren Sinn jeweils am Anschluss.
|
REGISTER .* MKOLDCOMPAT UNREGISTER .* RMOLDCOMPAT REGISTER .* MKNEWCOMPAT UNREGISTER .* RMNEWCOMPAT |
Mit diesen Anweisungen wird zu jedem Treiber, der sich am Device-Dateisystem registriert, automatisch vom devfsd eine Gerätedatei nach alten Stil erzeugt (also bspw. /dev/hda falls sich der IDE-Treiber registriert). Beim Entfernen eines Treibers wird diese Gerätedatei ebenfalls gelöscht. Diese Zeilen helfen letztlich bei der Migration zum Device-Dateisystem, da Sie am Anfang kaum wissen können, welche der installierten Programme die alten Gerätedateien benötigen. So sollten sie wie gewohnt arbeiten.
| LOOKUP .* MODLOAD |
Mit diesem Eintrag wird der Device Management Daemon automatisch die notwendigen Module laden, wenn ein Prozess eine Datei des Device-Dateisystems öffnet und der betreffende Treiber noch nicht registriert ist. Intern wird »modprobe <Eintrag>« gerufen. Dieser Eintrag ist der Name der Gerätedatei, die der Prozess versucht zu finden. Damit ein Modul gefunden werden kann, muss ein entsprechender Alias in einer Datei /etc/modules.devfs existieren. Die Syntax der Datei entspricht exakt der der Datei /etc/modules.conf. Angenommen, ein Prozess versucht /dev/cdrom/cdrom0 zu öffnen, dann sollte die Datei »modules.devfs« einen Eintrag analog zu diesem enthalten:
|
user@sonne> grep '/dev/cdrom/cdrom0' /etc/modules.devfs alias /dev/cdrom/cdrom0 <mein_cdrom_modul> |
Sie könnten obige Zeile auch direkt in die Datei /etc/modules.conf aufnehmen, allerdings könnte das Probleme geben, falls Sie Ihr System einmal ohne das Device-Dateisystem starten. Die Datei »modules.devfs« bindet »modules.conf« ohnehin mittels des Include-Befehls ein, sodass für devfsd-spezifische Ergänzungen »modules.devfs« die sauberere Lösung ist.
|
REGISTER ^pt[sy]/.* IGNORE CHANGE ^pt[sy]/.* IGNORE REGISTER .* COPY /dev-state/$devname $devpath CHANGE .* COPY $devpath /dev-state/$devname CREATE .* COPY $devpath /dev-state/$devname |
Letztere Einträge stellen das Überleben von Änderungen bei einem Systemneustart sicher. Die Pseudoterminals werden ignoriert. Die REGISTER-Zeile kopiert bei der Registrierung eines Treibers den gespeicherten Eintrag aus »/dev-state« nach »/dev«. »devname« und »devpath« sind Platzhalter, die jeweils den Namen des Devices, so wie er im Namensraum des Device-Dateisystems steht, bzw. den vollständigen Pfadnamen enthalten. Bei Erzeugung oder Änderung werden diese durch Kopieren ins Verzeichnis »/dev-state« auf Platte gesichert.
| REGISTER ^cdrom/cdrom0$ CFUNCTION GLOBAL symlink cdroms/cdrom0 cdrom UNREGISTER ^cdrom/cdrom0$ CFUNCTION GLOBAL unlink cdrom |
Die beiden letzten Beispiele zeigen, wie Links bei Registrieren erzeugt und beim Entfernen des Treibers wieder gelöscht werden können. Vermutlich müssen Sie Einträge für eine Reihe von Geräten ergänzen, da etliche Prozesse diese Links anstatt der realen Gerätedateien verwenden.
| Einrichten eines Dateisystems |
|
Bevor ein Speichermedium Daten aufnehmen kann, muss dieses dafür eingerichtet werden (Ausnahme ist die Verwendung von Programmen wie tar, die auf unformatierte Medien schreiben können). Während Linux nahezu jedes Dateisystem einbinden kann, stehen zum Formatieren nur Hilfsmittel für bestimmte Dateisysteme zur Verfügung. Zu jeder Standardinstallation gehören Werkzeuge zum Anlegen von ext2/ext3-, SCO-, bfs-, Minix- und FAT-Dateisystemen. Darüber hinaus liegt dem Paket des ReiserFS ein eigenes Werkzeug bei. Auch das Einrichten einer Swap-Partition und -Datei soll in diesem Zusammenhang diskutiert werden.
Zum Erzeugen eines Dateisystems dient das Kommando mkfs, dem der konkrete Typ als Argument -t Dateisystemtyp mitzuteilen ist. Fehlt die Angabe, wird immer ext2 angelegt. mkfs ist nur ein Frontend und ruft seinerseits die dateisystemspezifischen Kommandos (z.B. mkfs.ext2) auf. In den Beispielen werden wir nur diese verwenden. Auch spezifizieren wir das zu formatierende Dateisystem über seine Gerätedatei (Device).
| Aufruf: mke2fs [OPTIONEN] DEVICE [BLÖCKE] |
DEVICE ist das zu formatierende Gerät (aus /dev/) und BLÖCKE ist nur anzugegeben, wenn die Kapazität des Mediums nicht erkannt werden kann oder falls Sie - aus welchem Grund auch immer - weniger Blöcke als möglich sind anzulegen gedenken.
Schon wichtiger sind die Optionen -c zum vorherigen Überprüfen des Speichermediums und -l Datei zur Angabe einer Datei, die die Nummern fehlerhafter Blöcke enthält (siehe auch unter Prüfen eines Dateisystems).
Sowohl Inode-Anzahl als auch die Blockgröße versucht mke2fs automatisch anhand der Kapazität zu kalkulieren. Interessant ist hierbei die Verwendung der Option -T Verwendungszweck, die dem Kommando weitere Informationen über die Art der vornehmlich zu speichernden Daten liefert. Derzeit wird einzig »news« unterstützt (Newsartikel haben die Eigenschaft sehr kurz zu sein (< 1k), so dass eine kleine Blockgröße bei einer hohen Inodedichte angebracht erscheint). Ihnen Anwender steht selbstverständlich frei, sämtliche Parameter selbst zu bestimmen. So setzt -N Anzahl die Anzahl der Inodes, -b Blockgröße die Größe der einzelnen Datenblöcke (1024, 2048 oder 4096) und -i Anzahl weist »mke2fs« an, auf einem x Bytes großen Medium x/Anzahl Inodes zu erzeugen.
Von den zahlreichen Optionen benötigen Sie in der Praxis am ehestens noch -n, das die Formatierung nur simuliert, das Medium selbst aber unbehelligt lässt. Weiterhin unterdrückt ein -q sämtliche Ausgaben (wichtig in Skripten); -m Prozent setzt die prozentuale Größe an reserviertem Speicherplatz, der nur von Root verwendet werden kann (Schutzmaßnahme vor Überlauf des Dateisystems!) und -S schreibt letztlich nur Superblock und die Gruppendeskriptoren neu.
Als Beispiel formatieren wir eine Diskette mit dem ext2, wobei die Reservierung für den Administrator abgeschaltet wird. Da wir weniger als 100 Dateien zu speichern gedenken, beschränken wir die Inode-Anzahl diesbezüglich:
|
root@sonne> mke2fs -N 100 -m 0 /dev/fd0 mke2fs 1.26 (3-Feb-2002) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) 104 inodes, 1440 blocks 0 blocks (0.00%) reserved for the super user First data block=1 1 block group 8192 blocks per group, 8192 fragments per group 104 inodes per group Writing inode tables: done Writing superblocks and filesystem accounting information: done |
Da ext3 eine Erweiterung zum ext2-Dateisystem darstellt, fügten die Entwickler einfach zum Kommando »mke2fs« einige neue Optionen hinzu anstatt ein eigenständiges Programm zu schreiben. Die unter »Anlegen eines ext2-Dateisystems« beschriebenen Parameter von »mke2fs« stehen somit auch für das ext3-System zur Verfügung.
Verwenden Sie für »mke2fs« die Option -j, so wird automatisch ein ext3-Dateisystem mit Journal und Voreinstellungen (Journalgröße in Abhängigkeit von der Dateisystemgröße) generiert:
|
root@sonne> mke2fs -j /dev/ram0 mke2fs 1.26 (3-Feb-2002) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) 16000 inodes, 64000 blocks 3200 blocks (5.00%) reserved for the super user First data block=1 8 block groups 8192 blocks per group, 8192 fragments per group 2000 inodes per group Superblock backups stored on blocks: 8193, 24577, 40961, 57345 Writing inode tables: done Creating journal (4096 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 21 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override. |
Existieren auf Ihrem System ext2-Dateisysteme, so können Sie diesen ohne Probleme die Fähigkeiten des Journaling beibringen und in ein ext3 wandeln.
Voraussetzungen sind, das zum Einen der Kernel ext3 unterstützt und zum Anderen noch »ausreichend« Speicherplatz zum Anlegen des Journals zur Verfügung steht.
Der für das Journal mindestens erforderliche Speicherplatz richtet sich nach der verwendeten Blockgröße. Das Minimum liegt bei 1024 und das Maximum bei 102400 Blöcken. Im Falle von 1k-Blöcke benötigen Sie also mindesten 1MByte freie Kapazität; bei 4k-Blöcken sind es schon 4MByte.
Folgender Aufruf konvertiert ein ext2-Dateisystem (auf /dev/hda1) nach ext3 bei Verwendung der Standardoptionen:
|
root@sonne> tune2fs -j /dev/hda1 tune2fs 1.28 (31-Aug-2002) Creating journal inode: done This filesystem will be automatically checked every 100 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override. |
Die tatsächliche Größe des Journals richtet sich neben der Blockgröße nach dem bei der Konvertierung vorhandenem Speicherplatz. Beabsichtigen Sie dessen Größe selbst festzulegen, müssen Sie auf anstatt »-j« die Option »-J size=Gröszlig;e« verwenden.
Für den Fall, dass der Speicherplatz auf der zu konvertierenden Partition nicht mehr ausreicht, können Sie für das Journal eine eigene Partition verwenden. Diese Partition muss zuvor als Journal eingerichtet worden sein. Ihre Blockgröße muss der der zu konvertierenden Partition entsprechen!
|
root@sonne> mke2fs -0 journal_dev /dev/hdb7 mke2fs 1.28 (31-Aug-2002) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) 0 inodes, 12360 blocks ... root@sonne> tune2fs -J device=/dev/hdb7 /dev/hda1 ... |
Auch die Wandlung eines ext3- in ein ext2-Dateisystem ist möglich. Das zu konvertierende Dateisystem ist hierzu abzuhängen oder als nur-lesend einzuhängen (Letzteres demonstriert das Beispiel).
|
root@sonne> umount /dev/hda1 root@sonne> mount /dev/hda1 /mnt -o ro root@sonne> tune2fs -O ^has_journal /dev/hda1 tune2fs 1.28 (31-Aug-2002) |
| Aufruf: mkfs.minix [OPTIONEN] DEVICE |
Das Anlegen eines Minix-Dateisystems könnte höchstens für Disketten von Vorteil sein, da der Speicherverbrauch durch die Verwaltungsstrukturen geringer ausfällt als beim "ext2", so dass effektiv geringfügig (<30 kByte) mehr Kapazität zur Aufnahme der Daten zur Verfügung steht.
Im Falle von Disketten kann ein vorheriger Test des Mediums nicht schaden. Die Option -c gibt eine Liste fehlerhafter Blöcke aus, die beim anschließenden Formatieren ausgeblendet werden. Diese Blöcke lassen sich auch in einer Datei speichern, so dass ein nächster Durchlauf die Informationen über -l Datei aus dieser entnehmen könnte.
In der Voreinstellung gestattet Minix 30 Zeichen lange Dateinamen, dies kann mit der Option -n Länge auf 14 Zeichen beschränkt werden. Andere Längen sind nicht zulässig.
Die Anzahl anzulegender Inodes wird anhand des verfügbaren Speicherplatzes berechnet. Minix kalkuliert mit 3 Datenblöcken (immer 1k groß) für eine Datei, so dass die Anzahl Inodes für die meisten Fälle viel zu hoch gegriffen ist und mittels -i Anzahl reduziert werden kann. Als Beispiel formatieren wir eine Diskette:
|
root@sonne> mkfs.minix -c
/dev/fd0 480 inodes 1440 blocks Firstdatazone=19 (19) Zonesize=1024 Maxsize=268966912 160 ...320 ...480 ...640 ...800 ...960 ...1120 ...1296 ... |
| Aufruf: mkfs.bfs [OPTIONEN] DEVICE |
Aus Gründen der Vollständigkeit soll auch dieses Dateisystem beschrieben sein, das standardmäßig in SCO-Unix Verwendung findet. Als Option ist nur -N Anzahl interessant, um die automatische Kalkulation der Inode-Anzahl auszusetzen. Zulässige Werte liegen dabei zwischen 48 und 512. Das Kommando selbst tätigt nur im Fehlerfall Ausgaben, es muss erst mit -v zu etwas mehr Auskunft überredet werden.
Das folgende Beispiel legt auf einer Diskette ein SCO-Dateisystem mit 100 Inodes an:
| root@sonne> mkfs.bfs -N 100 -v
/dev/fd0 Device: /dev/fd0 Volume: < > FSname: < > BlockSize: 512 Inodes: 100 (in 13 blocks) Blocks: 2880 Inode end: 6911, Data end: 1474559 |
| Aufruf: mkdosfs [OPTIONEN] DEVICE [BLÖCKE] |
Aus Effizienzgründen wird man wohl niemals ein FAT-Dateisystem als echtes Medium für eine Linux-Installation in Betracht ziehen, aber im Falle des Datenaustauschs mit einem Windows-System (vornehmlich NT, da es mit dem Beschreiben von Ntfs arge Probleme gibt) kann eine FAT-formatierte Partition oder Diskette durchaus nützlich sein.
Wie bereits bei ext2 und Minix beschrieben, versteht auch das Kommando mkdosfs die Optionen -c und -l Datei, um eine Überprüfung auf fehlerhafte Blöcke vorzunehmen bzw. um die Liste defekter Sektoren aus einer Datei zu lesen.
Um ein FAT32-System zu erzeugen, muss dem Kommando die Größe der File Allocation Table explizit mitgeteilt werden -F 32, anderenfalls werden in Abhängigkeit des Mediums 12 Bit (z.B. Disketten) oder 16 Bit (Festplatten) veranschlagt. Per Voreinstellung werden zwei FATs pro System abgelegt (falls eine zerstört wird, kann die zweite verwendet werden), mit -f Anzahl kann die Anzahl modifiziert werden (derzeit sind nur 1 oder 2 zulässig).
Schließlich kann die Anzahl von möglichen Einträgen im Wurzelverzeichnis modifiziert werden, was bei großen Festplatten (Voreinstellung 512) durchaus erforderlich sein könnte: -r Anzahl. Wie viele Sektoren einem Cluster zugeordnet werden, regelt die Option -s Anzahl, wobei nur Werte 2x, x=0,1,2,... gestattet sind.
Das Beispiel verwendet wieder die Diskette, wobei diese mit FAT32 bei nur einer Tabelle formatiert wird. Als Label soll das Dateisystem "DOS" erhalten. Die erweiterte Ausgabe bringt erst die Option -v ans Licht:
|
root@sonne> mkdosfs -F 32 -v -f 1 -n DOS
/dev/fd0 mkdosfs 0.4, 27th February 1997 for MS-DOS/FAT/FAT32 FS /dev/fd0 has 2 heads and 18 sectors per track, using 0xf0 media descriptor, with 2880 sectors; file system has 1 32-bit FAT and 1 sector per cluster. FAT size is 23 sectors, and provides 2825 clusters. Volume ID is 3992a22e, volume label DOS . |
| Aufruf: mkreiserfs [ OPTIONEN ] DEVICE [ ANZAHL_BLÖCKE ] |
Die Werkzeuge zur Handhabung des ReiserFS liegen derzeit den wenigsten Distributionen (bei SuSE ab Version 6.4) bei, deswegen sollte man sich sowohl das Paket der Utilities (reiserfs-version) als auch den notwendigen Kernelpatch aus dem Internet besorgen. Der nächste Schritt ist das Einspielen des Patches in die Kernelsourcen und die Erzeugung desselben mit Unterstützung für das ReisferFS.
Da derzeit als Blockgröße einzig 4 kByte unterstützt werden, reduzieren sich die Optionen auf eine optionale Angabe der Anzahl anzulegender Blöcke (das macht eigentlich wenig Sinn, da mkreiserfs diese anhand der Partitionsgröße selbstständig berechnen kann) und eines Hash-Namens, der zur Sortierung der Dateinamen eingesetzt wird. Bei letzterem sind allerdings auch nur "tea" oder "rupasov" zulässig.
Zusammengefasst, reduziert sich die Liste der Argumente in den meisten Fällen auf den Namen des Devices (aufgrund der Größe des Journals erfordert ReiserFS eine mindestens 10MByte große Partition):
|
root@sonne> mkreiserfs /dev/hdb3 <-----------MKREISERFS, 2000-----------> ReiserFS version 3.5.23 Block size 4096 bytes Block count 69048 First 16 blocks skipped Super block is in 16 Bitmap blocks are : 17, 32768, 65536 Journal size 8192 (blocks 18-8210 of device 0x3:0x43) Root block 8211 Used 8214 blocks Hash function "tea" ATTENTION: ALL DATA WILL BE LOST ON '/dev/hdb3'! (y/n)y Initializing journal - 0%....20%....40%....60%....80%....100% Syncing.. ReiserFS core development sponsored by SuSE Labs (suse.com) Journaling sponsored by MP3.com. To learn about the programmers and ReiserFS, please go to http://www.devlinux.com/namesys Have fun. |
Sowohl der Kernel als auch die Daten des Bootmanagers dürfen nicht auf einer mit ReiserFS formatierten Partition liegen, da der Bootmanager dieses nicht lesen kann!
Jedes Programm, das von Linux abgearbeitet werden soll, muss in den Arbeitsspeicher (RAM) geladen werden. Linux führt aber zahlreiche Programme quasi parallel aus und jedes dieser Programme muss somit im RAM seinen Platz finden. Irgendwann wird der Arbeitsspeicher knapp... Und nun?
"Kein Speicher - kein Programm", so einfach ist die Regel und Linux weist jeden weiteren Programmstart mit dem Ausspruch Out of virtual memory. ab. Uns als Administratoren bleiben nun mehrere Möglichkeiten offen:
Erstere Variante scheidet schon aus, da unser System möglichst problemlos ohne Aufsicht laufen soll. Vermutlich benötigen wir auch alle anderen Prozesse, so dass wir keinen "abschießen" mögen...
Die zweite Möglichkeit scheitert meist am Geld... und in 99% der Fälle genügt ja der installierte Arbeitsspeicher... Muss ich wirklich nur für die seltenen Situationen diesen aufstocken?
Die Lösung: Wir verwenden einfach einen Teil der Festplatte als "Verlängerung" des RAM. Linux trägt nun selbst Sorge, dass die Daten des jeweils benötigten Prozesses im physischen RAM liegen und Speicherseiten, die im Augenblick keine Verwendung finden, im Bereich des "virtuellen RAM" auf der Festplatte gehalten werden.
Meist wurde während der Installation bereits eine eigene Swap-Partition erzeugt, so dass ein nachträgliches Einrichten nicht notwendig wird. Was aber, wenn Sie feststellen, dass sich die "Out of virtual memory" häufen?
Steht Ihnen noch eine freie Partition auf einer Festplatte zur Verfügung, können Sie diese für den virtuellen Swap verwenden. Allerdings darf die Größe einer einzelnen Partition 2GB (bei Kerneln <2.1.117 128MB) nicht übersteigen (im Abschnitt Installation finden Sie nähere Informationen).
Das folgende Beispiel demonstriert die Schritte zum Einrichten einer Swap-Partition. Es wird angenommen, dass die Partition »/dev/hdb1« (100 MB) frei ist. Vorsicht: Der Inhalt der Partition wird rigoros überschrieben, vergewissern Sie sich, dass die von Ihnen auserwählte Partition tatsächlich nicht andersweitig verwendet wird!
|
root@sonne> mkswap /dev/hdb1 Swapbereich Version 0 mit der Größe 104857600 Bytes wird angelegt |
| root@sonne> swapon /dev/hdb1 |
| /dev/hdb1 none swap sw 0 0 |
| root@sonne> swapoff /dev/hdb1 |
Eine Swap-Datei sollte nur als Notlösung in Betracht gezogen werden, wenn bspw. keine Partition für den Swap mehr zur Verfügung steht. Ein Zugriff auf eine Datei erfordert immer den Umweg über das Dateisystem und ist somit langsamer als ein Zugriff auf eine Swap-Partition. Zunächst müssen Sie eine Datei der gewünschten Größe anlegen:
| root@sonne> dd if=/dev/zero
of=mein_swap_file bs=1024 count=102400 1024+0 records in 1024+0 records out |
Im Beispiel wird mit Hilfe von dd eine 100MB große Datei »mein_swap_file« angelegt und mit Nullen beschrieben. Mit dieser Datei ist nun wie bei einer Swap-Partition beschrieben zu verfahren. Ersetzen Sie in den jeweiligen Zeilen den Device- durch den Datei-Namen.
| Prüfen eines Dateisystems |
|
In diesem Zusammenhang möchte ich mit einer Überprüfung der physischen Unversehrtheit des Speichermedium beginnen, da zumeist ein beschädigter Block Ursache für einen Fehler im Dateisystem ist.
Um »schlechte« Blöcke auf einer Diskette oder Festplatte festzustellen, verwendet man das Kommando badblocks.
| Aufruf: badblocks [ OPTIONEN ] DEVICE BLÖCKE [STARTBLOCK] |
DEVICE steht dabei für den Gerätenamen des Mediums und mit BLÖCKE ist die Anzahl der zu untersuchenden Datenblöcke auf dem Medium anzugeben. Optional kann mit STARTBLOCK der erste zu testende Block spezifiziert werden.
Mit der Option -b Blockgröße kann die Anzahl Bytes je Block angegeben werden. Dies ist nur notwendig, wenn beim Einrichten des Dateisystems eine von der Voreinstellung abweichende Größe gewählt wurde. Mit -o Datei wird die Liste der beschädigten Blöcke in eine Datei geschrieben, die von einigen Programmen zum Einrichten eines Dateisystems verwendet werden kann. Des Weiteren kann das Fortschreiten der Überprüfung mit der Option -s beobachtet werden und -w nimmt gleichzeitig einen Schreibtest auf den Blöcken vor. Wenden Sie letzte Option nur auf unformatierte Medien an, eventuell darauf befindliche Daten sind anschließend pfutsch!
Als Beispiel soll eine 1.44MB-Diskette überprüft werden. Das Ergebnis des Tests wird in einer Datei »kaputt« gespeichert:
|
root@sonne> badblocks -s -o kaputt
/dev/fd0 1440 Checking for bad blocks (read-only test): done |
Untersuchen und - mit Einschränkungen - Reparieren lassen sich derzeit (aus Linux heraus) nur die Dateisysteme ext2, Minix und ReiserFS. Für beide erstere ist fsck zu verwenden, das wiederum ein Frontend ist und die Aufrufe der Kommandos fsck.ext2 und fsck.minix in Abhängigkeit vom verwendeten Dateisystem veranlasst. fsck sucht die Kommandos allerdings zunächst in bestimmten Verzeichnissen und befolgt nur falls dort es nicht fündig wird die Regeln der PATH-Variablen. Ein ReiserFS überprüft das Kommando reiserfsck. Laut dessen Manual ist der Einsatz wegen des Journals ohnehin nicht notwendig und zum anderen - auch auf Grund mangelnder Erfahrungen - mit Vorsicht zu genießen. Wir werden darauf nicht näher eingehen.
fsck sollte immer auf nicht-gemountete oder read-only gemountete Dateisysteme angewendet werden, da das Programm mitunter das Dateisystem modifiziert, ohne dass das System dies realisiert. Ein Systemabsturz könnte die Folge sein...
Eine defektes Dateisystem beschwört eine Menge Ärger herauf. Kein Wunder also, dass es zu den Gepflogenheiten zählt, während des Startvorgangs den Status der Dateisysteme zu überprüfen.
Die verschiedenen Distributionen haben den Aufruf
| fsck -a -A |
in einem der Startskripte eingebaut (Debian "/etc/init.d/checkfs.sh", RedHat "/etc/rc.d/rc.sysinit", SuSE "/etc/rc.d/boot"). Die Option -A veranlasst das Kommando, alle in der Datei /etc/fstab als "zu testen" gekennzeichneten Dateisysteme zu überprüfen. -a bewirkt, eine Reparatur ohne Interaktion mit dem Benutzer - sofern die Mängelbeseitigung keinen manuellen Eingriff bedingt.
Wohl jeder Linuxer ist während des Bootens schon einmal auf eine der folgenden Ausgaben gestoßen:
|
/dev/hda2 was not cleanly unmounted, check forced. /dev/hda2 has reached maximal mount count, check forced. /dev/hda2 has gone too long without beeing checked, check forced. |
Solche Ausgaben sind ärgerlich, weil der nachfolgende Test doch einige Zeit in Anspruch nimmt, aber unkritisch, denn es handelt sich um reine Vorsichtsmaßnahmen.
Als Ursache der ersten Ausgabe entpuppt sich meist ein vorangegangenes Abschalten des Systems, ohne das Dateisystem korrekt per "umount" abgemeldet zu haben. Hier hilft nur, in Zukunft mit dem Abdrehen der Stromzufuhr zu warten, bis Linux das vollständige Herunterfahren signalisiert hat.
Mit der zweiten Ausschrift kündigt fsck an, dass das System schon sehr häufig gemountet wurde und sicherheitshalber eine Untersuchung vorgenommen wird. Der konkrete Wert der maximal erlaubten Mountvorgänge ohne zwischenzeitliche Überprüfung ist im Superblock des ext2 gespeichert und kann bei Bedarf modifiziert werden.
Ebenso eine reine Vorsichtsmaßnahme ist die Überprüfung, die die dritte Ausschrift ankündigt. Hier liegt der Zeitpunkt des letzten Tests schon weiter zurück, als es laut Informationen im Superblock zulässig ist. Da dieser Wert in der Voreinstellung allerdings ein halbes Jahr beträgt, werden die wenigsten Anwender in den Genuss (oder Frust) dieser Mitteilung gelangen.
e2fsck überprüft das Dateisystem in fünf Phasen:
Manchmal kommt es dann doch vor, dass fsck die zu treffenden Maßnahmen nicht allein entscheiden kann. Aber auch nach dem manuellen Start (ohne Argument »-a«) werden Reparaturen erst nach Bestätigung durch den Administrator ausgeführt.
Um einen Ernstfall zu simulieren, wurden mehrere Dateien auf eine ext2-formatierte Diskette kopiert und diese während des Schreibvorgangs entnommen. Der anschließende Testlauf von »e2fsck« ist im nachstehenden Listing dargestellt (die einzelnen Phasen wurden farblich markiert):
|
root@sonne> e2fsck /dev/fd0 e2fsck 1.18, 11-Nov-1999 for EXT2 FS 0.5b, 95/08/09 /dev/fd0 was not cleanly unmounted, check forced. Pass 1: Checking inodes, blocks, and sizes Inode 13 has illegal block(s). Clear<y>?[Enter]yes Illegal block #-1 (808796998) in inode 13. CLEARED. Illegal block #-1 (1010704950) in inode 13. CLEARED. Illegal block #-1 (1699626562) in inode 13. CLEARED. Illegal block #-1 (1702328948) in inode 13. CLEARED. Illegal block #-1 (1394633586) in inode 13. CLEARED. Illegal block #-1 (1701340009) in inode 13. CLEARED. Illegal block #-1 (1768253554) in inode 13. CLEARED. Illegal block #-1 (1110391924) in inode 13. CLEARED. Illegal block #-1 (1714371646) in inode 13. CLEARED. Illegal block #-1 (1047817839) in inode 13. CLEARED. Illegal block #-1 (1046556476) in inode 13. CLEARED. Too many illegal blocks in inode 13. Clear inode<y>?[Enter]yes Restarting e2fsck from the beginning... /dev/fd0 was not cleanly unmounted, check forced. Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Entry 'linuxfibel.tar.gz' in / (2) has deleted/unused inode 13. Clear<y>?[Enter]yes Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information Block bitmap differences: -117 -118 -119 -120 -121 -122 -123 -124 -125 -126 -127 -1 145 -146 -147 -148 -149 -150 -151 -152 -153 -154 -155 -156 -157 -158 -159 -160 -161 -162 -163 -164 -165 -166 -167 -168 -169 -170 -171 -172 -173 -174 -175 -176 -177 -178 -179 -180 -181 -182 -183 -184 -185 -186 -187 -188 -189 -190 -191 -192 -193 -194 -195 -196 -197 -198 -199 -200 -201 -202 -203 -204 -205 -206 -207 -208 -209 -210 -211 -212 -213 -214 -215 -216 -217 -218 -219 -220 -221... fix<y>?[Enter] yes Free blocks count wrong for group #0 (941, counted=1321). Fix<y>?[Enter] yes Free blocks count wrong (941, counted=1321). Fix<y>?[Enter] yes Inode bitmap differences: -13 Fix<y>?[Enter] yes Free inodes count wrong for group #0 (170, counted=171). Fix<y>?[Enter] yes Free inodes count wrong (170, counted=171). Fix<y>?[Enter] yes /dev/fd0: ***** FILE SYSTEM WAS MODIFIED ***** /dev/fd0: 13/184 files (0.0% non-contiguous), 119/1440 blocks |
Was tun, wenn e2fsck die Reparatur verweigert?
Bevor Sie weiter experimentieren, empfiehlt sich dringend ein Backup der entsprechenden Partition (mit einem Low-Level-Werkzeug wie dd).
Wir gehen nachfolgend von einer intakten Partitionstabelle aus; bzw. für den Fall deren Beschädigung, dass Sie diese exakt reproduzieren können. Des Weiteren ist zu vermuten, dass e2fsck nicht wegen einiger fehlerhafter Datenblöcke oder Inodes die Segel strich, sondern wegen Zerstörung einer oder mehrerer Gruppen (und damit der wichtigen Informationen zu Superblock und Gruppendeskriptoren). Die Struktur des ext2 ist zum Glück so angelegt, dass diese immens wichtigen Informationen redundant zu Beginn einer jeden Gruppe abgelegt sind. Es geht also darum, diese Blöcke zu restaurieren.
Ihr erster Versuch sollte sein, e2fsck explizit einen alternativen Superblock vor die Nase zu setzen:
| root@sonne> fsck -b 8193 /dev/hda1 |
Obige Blocknummer entspräche dem Superblock der zweiten Gruppe bei 1k Blockgröße. Demzufolge läge die nächste Kopie bei 16385 usw. Bei 4k-Blöcken wäre die erste Kopie bei Blocknummer 32769 zu finden. Sie können mit den Werten getrost experimentieren, da e2fsck mit einem Fehler endet, falls keine gültigen Superblockinformationen im angegebenen Block gefunden wurden. Im Erfolgsfall ersetzt das Kommando abschließend den korrupten Superblock mit der angegebenem Kopie.
Versagt oberes Vorgehen, sollten Sie die exakten Formatierungsdaten der fehlerhaften Partition kennen. Haben Sie bei der Einrichtung des Dateisystems dem Kommando mke2fs die Berechnung der Parameter überlassen, können Sie dieses nun anweisen, einzig die Superblöcke und Gruppendeskriptoren neu zu schreiben:
| root@sonne> mke2fs -S /dev/hda1 |
Bei ursprünglicher Vorgabe eigener Werte (Anzahl Inodes...) sind diese zusätzlich als Kommandozeilenparameter anzugeben!
| Optimieren des ext2/ext3 |
|
Der DOS/Windows9X-Umsteiger denkt hier vermutlich in erster Linie an ein zur Defragmentierung analoges Vorgehen. Tatsächlich existiert ein Defragmentierungswerkzeug für »ext2«, jedoch haben Messungen gezeigt, dass der erzielte Leistungsgewinn den Nutzen ad absurdum führt. Die Strategie des »ext2« beim Anlegen neuer Dateien minimiert den Grad der Fragmentierung erstaunlich gut.
Dennoch lassen sich einzelne Parameter des ext2 mit Hilfe des Kommandos tune2fs manipulieren. Betrachten wir zuerst die Informationen, die »tune2fs« einem ext2-Dateisystem zu entlocken vermag:
|
root@sonne> tune2fs -l /dev/fd0 tune2fs 1.18, 11-Nov-1999 for EXT2 FS 0.5b, 95/08/09 Filesystem volume name: <none> Last mounted on: <not available> Filesystem UUID: 5a101826-f249-4a60-baad-ccfe2d66f0ed Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: filetype sparse_super Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 184 Block count: 1440 Reserved block count: 72 Free blocks: 1321 Free inodes: 171 First block: 1 Block size: 1024 Fragment size: 1024 Blocks per group: 8192 Fragments per group: 8192 Inodes per group: 184 Inode blocks per group: 23 Last mount time: Tue Oct 3 09:09:13 2000 Last write time: Tue Oct 3 09:15:58 2000 Mount count: 0 Maximum mount count: 20 Last checked: Tue Oct 3 09:15:58 2000 Check interval: 15552000 (6 months) Next check after: Sun Apr 1 09:15:58 2001 Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 128 |
Alle Informationen gewinnt »tune2fs« aus dem Superblock des Dateisystems. Die änderbaren Einträge wurden farblich hervorgehoben, deren Bedeutung/Änderung wir uns nachfolgend zuwenden.
sparse_super ist ein Flag, das erst ab Kernel > 2.1 bekannt ist. Ist dieses gesetzt, speichert das Dateisystem »dünn besetzte« Dateien - diese enthalten Blöcke, die nur aus 0-Bytes bestehen - optimiert, indem diese »0-Blöcke« keinen physikalischen Speicherplatz belegen (das Dateisystem merkt sich nur die Position solcher Blöcke). Das Flag kann mittels tune2fs -s <Device> umgeschalten werden. Da dies aber keinen Nutzen bringt, ist davon abzuraten.
Wenn beim Dateisystemcheck ein Fehler erkannt wurde, regelt der unter Errors behavior eingestellte Modus das weitere Vorgehen. Zulässig sind »continue« zum Fortfahren mit dem »normalen« Vorgehen, »remount-ro« zum nur-lesenden Mounten des Dateisystem oder »panic« zum Stoppen mit einer »kernel panic«.
| root@sonne> tune2fs -e remount-ro /dev/hda2 |
Üblich ist, das Root-Dateisystem mit »remount-ro« und alle nicht zwingend notwendigen Dateisysteme mit »continue« zu versehen.
Reserved block count bezeichnet Datenblöcke, die einzig Root vorbehalten sind. D.h. aus Sicht jedes »normalen« Anwenders ist das Dateisystem um die Anzahl reservierter Blöcke kleiner als es die tatsächliche Speicherkapazität ist. Der Grund ist, dass zumindest Root noch mit dem Dateisystem arbeiten können muss, wenn es - warum auch immer - in seiner Kapazität erschöpft ist (um die Ursache zu beheben):
|
# Setzen der Anzahl reservierter Blöcke root@sonne> tune2fs -r 100 /dev/fd0 # Setzen des prozentualen Anteils reservierter Blöcke (10%) root@sonne> tune2fs -m 10 /dev/hda2 |
Mount count gibt die Anzahl der Mountvorgänge seit der letzten Dateisystemüberprüfung an und Maximum mount count beinhaltet die Anzahl Mountvorgänge, die ohne eine zwischenzeitliche Überprüfung zulässig sind (letzterer Wert ist sicherlich die sinnvollste »Optimierung« des ext2 uuml;berhaupt):
|
# Setzen der Anzahl Mountvorgänge root@sonne> tune2fs -C 10 /dev/fd0 # Setzen der Anzahl maximal erlaubter Mountvorgänge root@sonne> tune2fs -c 100 /dev/hda2 |
Check interval ist die zeitliche Spanne, die maximal zwischen zwei Überprüfungen verstreichen darf:
|
# Maximal 100 Tage root@sonne> tune2fs -i 100d /dev/fd0 # Maximal 10 Wochen root@sonne> tune2fs -i 10w /dev/hda2 # Maximal 12 Monate root@sonne> tune2fs -i 12m /dev/hda2 |
Die letzten hier vorgestellten Modifikationen bestimmen die Benutzer Reserved blocks uid bzw. Gruppe Reserved blocks gid, die die reservierten Blöcke verwenden dürfen. Beide Werte dürfen sowohl symbolisch als auch numerisch angegeben werden:
Die Journaling-Funktionalität garantiert die Datenkonsistenz. Somit sind die ext2-typischen Dateisystemprüfungen nicht notwendig und können abgeschaltet werden:
|
# Dateisystemprüfung deaktivieren root@sonne> tune2fs -c 0 -i 0 /dev/hda2 |
|
# Gruppen 100 und root root@sonne> tune2fs -g 100 -g root /dev/fd0 # Benutzer tux, user, root root@sonne> tune2fs -u tux -u user -u root /dev/hda2 |
| Mounten eines Dateisystems |
|
Bevor ein Dateisystem unter Unix verwendet werden kann, muss es in die Verzeichnisstruktur integriert werden. Man bezeichnet diesen Vorgang als Mounten.
Wenn Linux bootet, benötigt der Kernel verschiedene Programme, um bspw. Tests und Initialisierungen vornehmen zu können oder verschiedene Dienste zu aktivieren. Diese Programme sind in einem Dateisystem auf einem permanenten Medium (meistens die Partition einer lokalen Festplatte) gespeichert. Um sie verwenden zu können, »mountet« der Kernel das Medium (also die Partition) als Rootverzeichnis.
Meist wird man allerdings das System nicht auf einer einzigen Festplattenpartition installiert haben, sondern es ist auf mehrere Partitionen oder Festplatten verteilt. Vielleicht sind Teile des Systems gar auf einem anderen Rechner im Netz gespeichert? Um auf das Dateisystem einer solchen Partitionen zugreifen zu können, muss ein im Rootverzeichnis vorhandener Verzeichniseintrag mit einer solchen Partition verbunden werden. Diese Verbindung stellt das Kommando mount her.
Es sollte klar sein, dass die Verwaltung der Dateisysteme allein dem Administrator obliegt; der Aufruf von mount Bedarf also immer Rootrechte mit einer Ausnahme, falls Root für bestimmte Dateisysteme (z.B. um den Zugriff auf Disketten oder CDROMs zu gestatten) den Benutzern das Mounten gestattet (siehe /etc/fstab).
| Aufruf: mount [OPTIONEN] Gerät Mountpunkt |
Dem Kommando wird im Normalfall mitgeteilt, »was« zu mounten ist (Gerät) und in welchem Verzeichnis dieses eingehangen werden soll (Mountpunkt). Die Angabe der Optionen kann entfallen, wenn
»Entsprechender Eintrag« heißt, dass in der Datei eine Zeile existiert, die die Parameter zum Mounten dieses Gerätes auf diesen Mountpunkt beschreibt. Unter den beschriebenen Voraussetzungen ist es sogar zulässig, die Argumente von mount auf das Gerät oder den Mountpunkt zu beschränken.
Der Aufruf von mount ohne Argumente bringt alle momentan gemounteten Dateisysteme zum Vorschein:
|
user@sonne> mount /dev/hdb3 on / type ext2 (rw) proc on /proc type proc (rw) /dev/hdb4 on /opt type ext2 (rw) /dev/hdb1 on /boot type ext2 (rw) /dev/hda2 on /home type ext2 (rw,usrquota) devpts on /dev/pts type devpts (rw,gid=5,mode=0620) |
Die wichtigsten Optionen, die mount für jeden Dateisystemtyp unterstützt, sind:
-a
-r
-w
-t vstype
-o Optionen
Eigenschaften wie das Dateisystem zu mounten ist, werden durch »-o« eingeleitet. Bei vorangestelltem »no« (»noauto«, »nodev«...) werden die Eigenschaften negiert (es gibt aber kein »noremount«, »noro« und »norw«!). Die wichtigsten Angaben sind:
-o async
-o atime
-o auto
-o defaults
-o dev
-o exec
-o remount
-o ro
-o rw
-o suid
-o sync
-o user
Im Zusammenhang mit dem Network File System und mit Samba werden Sie einige dateisystemspezifische Optionen des Kommandos kennen lernen. An dieser Stelle möchten wir nur auf das Mapping der Nutzerkennungen auf Windows- und DOS-Laufwerken hinweisen. Da diese die Unix-Rechte nicht kennen, werden in der Voreinstellung sowohl die Benutzerkennung als auch die Gruppenkennung aller Dateien eines solchen Dateisystems auf den Wert der Rechte des Prozesses gesetzt, der den »mount«-Befehl ausführt (startet Root das Kommando, erhält der Prozess dessen Rechte...). Um dennoch allen Benutzern das Schreiben auf einer solchen Partition zu gestatten, muss als Option "umask=000" angegeben werden. Um das Schreiben einem bestimmten Benutzer/Gruppe zu gestatten, lassen sich die Dateien mit "uid=<UID_des_Nutzer>" bzw. "gid=<GID_der_Gruppe>" dem Benutzer/der Gruppe gezielt zuordnen.
In neueren Kernelversionen unterstützt das Mount-Kommando weitere nützliche Optionen:
--bind <Altes_Verzeichnis> <Neues_Verzeichnis>
Ab Kernel 2.4.0 ist es möglich Teile eines Dateisystem zusätzlich an eine belibige andere Position im Dateisystem zu mounten. Das Verfahren hat gegenüber einem (symbolischen) Link vor allem einen Vorteil: Nach dem Unmount des Dateisystems bleibt kein ins Nichts zeigender Link übrig.
|
# Rootverzeichnis zusätzlich unter /mnt einhängen: root@sonne> mount --bind / /mnt root@sonne> mount | grep mnt / on /mnt type none (rw,bind) |
--rbind <Altes_Verzeichnis> <Neues_Verzeichnis>
--move <Altes_Verzeichnis> <Neues_Verzeichnis>
| Die Datei /etc/fstab |
|
Die Datei /etc/fstab enthält Parameter über das (permanente) Dateisystem. Hier werden die schon beim Systemstart zu mountenden Dateisysteme aufgeführt und alle Dateisysteme, die z.B. auch von einem normalen Nutzer zum System hinzugefügt bzw. aus dem System entfernt werden dürfen.
Jedes Dateisystem wird durch eine eigene Zeile beschrieben; anhand einer typischen /etc/fstab betrachten wir die wichtigsten Einträge (mit einem Doppelkreuz beginnende Zeilen sind Kommentare):
|
user@sonne> cat /etc/fstab # Root-Dateisystem /dev/hda1 / ext2 defaults 1 1 # Das Verzeichnis /usr erhält eine eigene Partition /dev/hdb2 /usr ext2 defaults 1 2 # Die Swap-Partition /dev/hda3 swap swap defaults 0 0 # ATAPI-Cdrom und Disketten-LW /dev/hdc /cdrom iso9660 ro,noauto,user 0 0 /dev/fd0 /floppy auto noauto,user 0 0 # Das Prozessdateisystem proc /proc proc defaults 0 0 # Ein NFS-Verzeichnis erde.galaxis.de:/home/nfs /mnt/nfs nfs defaults 0 0 |
Drei der Einträge dieser Beispieldatei sind für alle Systeme zu empfehlen:
| Zeile 1: | Betrifft das Root-Dateisystem (notwendig) |
| Zeile 3: | Einbinden einer Swap-Partition (optional) |
| Zeile 8: | Einbinden des Prozessdateisystems (notwendig) |
Alle weiteren Zeilen sind optional. Jede Zeile besteht aus 6 Spalten, die im Einzelnen folgende Bedeutung besitzen:
| Device Mountpunkt Type Options Dump Check |
Die Einträge bedeuten:
Device
Mountpunkt
Type
Options
Dump
Check
Mit den Optionen kann der Mount-Vorgang gesteuert werden (Auswahl):
defaults
noauto
user
ro, rw
exec
sync
| Die Datei /etc/mtab |
|
Alle momentan gemounteten Dateisysteme sind in der Datei /etc/mtab gespeichert:
|
user@sonne> cat /etc/mtab /dev/hda5 / ext2 rw 0 0 proc /proc proc rw 0 0 /dev/hda4 /opt ext2 rw 0 0 /dev/hda3 /usr ext2 rw 0 0 /dev/hda7 /home ext2 rw 0 0 devpts /dev/pts devpts rw,gid=5,mode=0620 0 0 |
Bei vorhandenem Prozessdateisystem wird die Information zusätzlich in der Datei "/proc/mounts" gehalten. Das Kommando "mount" wertet jedoch nur "/etc/mtab" aus.
| Der Automounter |

|
Die Flexibilität des Unix-Mount-Konzepts offenbart sich dem Administrator spätestens, wenn er dem expandierenden System eine neue Platte spendiert und Teile der bestehenden Installation nachträglich auf diese auslagert. Sicherlich erfordert eine solche Maßnahme fundierte Kenntnisse und trickreiche Kniffe, aber so ist es möglich, einem vollgestopften System ohne Neuinstallation Freiraum zur Arbeit zu verschaffen.
Andererseits vermisst der Linux-Neuling die einfache Handhabung beim Zugriff auf eine Diskette oder CDROM wohl schmerzlich. Diskette rein, Laufwerk mounten, ins betreffende Verzeichnis wechseln, Datei bearbeiten, Verzeichnis verlassen, Diskette unmounten - und das ganze Prozedere wiederholt sich mit der nächsten Magnetscheibe.
Aber der umständlichen Verfahrensweise mit Wechselmedien entsprang weniger die Motivation zur Entwicklung des Kernel-Automounters, der bei Bedarf, sprich beim Zugriff auf ein Dateisystem, dieses »im Hintergrund« mountet und - bei Nichtverwendung und Ablauf einer konfigurierbaren Zeitspanne auch wieder selbsttätig abhängt. Wichtigster Grund war wohl die beschränkte Anzahl gleichzeitig gemounteter Dateisysteme, die in großen Netzwerken rasch zu Engpässen führt(e). Im Zusammenhang mit dem Import von NFS-Verzeichnissen ist das automatische Unmounten bei Nichtbedarf ein positiver Nebeneffekt, um unnütze Mounts nach einem Server- oder Netzwerkcrash zu entfernen.
Die beiden Voraussetzungen zur Verwendung des Automounters sind das installierte Paket
(autofs-version-nummer.rpm) und die Unterstützung durch den Kernel
(Filesystems![]() Kernel
automounter support).
Kernel
automounter support).
|
root@sonne> vi /etc/auto.master # Unterhalb von /mnt sollen das lokale CDROM und das Floppy gemountet werden; beide sollen nach 60 Sekunden automatisch abgehangen werden /mnt /etc/auto.local --timeout 60 # Unterhalb von /home sollen die Heimatverzeichnisse erscheinen /home /etc/auto.homes |
| <Name des Mountpunkts> <Mount-Optionen> [Rechner]:<Device> |
|
root@sonne> vi /etc/auto.local cdrom -fstype=iso9660,ro,user :/dev/cdrom floppy -fstype=auto,rw,user :/dev/fd0 |
|
root@sonne> vi /etc/auto.home tux -fstype=nfs,rw,no_squash_all erde:/home/tux user -fstype=nfs,rw,no_squash_all erde:/home/user |
|
root@sonne> /sbin/init.d/autofs
start Starting service automounter done |
|
root@sonne> /sbin/init.d/autofs
status Checking for service autofs: OK Configured Mount Points: ------------------------ automount -t 300 /mnt file /etc/auto.local -timeout 60 automount -t 300 /home file /etc/auto.homes Active Mount Points: -------------------- automount -t 300 /mnt file /etc/auto.local -timeout 60 |
Ein erster Blick in das Verzeichnis »/mnt« bringt nichts zu Tage:
| user@sonne> ls /mnt |
Zu jenem Zeitpunkt kennt (hoffentlich) der Kernel zwar die Mountpunkts, aber das Anhängen des Dateisystems geschieht erst mit dem ersten Zugriff auf dieses selbst:
|
user@sonne> ls /mnt/floppy linuxfibel.tar.gz TODO.txt Automount.gz user@sonne> ls /mnt floppy |
Der Sinn des Automounters liegt ja gerade darin, dass er ein Dateisystem nur im Falle des Zugriffs mountet. Allerdings bringt dies auch Probleme mit sich:
Mit jedem Zugriff auf ein vom Automounter verwaltetes Dateisystem wird ein zugehöriger Timer neu gestartet. Erreicht dieser einen bestimmten Wert, so versucht der Automounter, das Dateisystem selbsttätig abzuhängen. In der Voreinstellung steht die Zeitspanne auf 5 Minuten, wird aber häufig in den Konfigurationsdateien und/oder im »autofs«-Skript auf einen geringeren Wert gesetzt.
Es kann allerdings vorkommen, dass ein Benutzer binnen kürzerer Zeit die Diskette wechseln will, was ein manuelles »Unmounten« dieser bedingt. Prinzipiell ist dies auf drei Wegen möglich:
Anmerkung: Ein Unmounten ist nicht möglich, wenn sich irgend jemand innerhalb des abzuhängenden Dateisystems befindet oder eine Datei aus diesem eröffnet hat.