

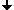
Struktur des Netzwerkes |
| Übersicht |
|
Die Komplexität eines Netzwerks wächst mit der Anzahl zu verbindender Komponenten. Zwei Rechner lassen sich einfach mittels eines gekreuzten Kabels verbinden. Kommt jedoch noch ein dritter hinzu, so bieten sich als Lösungen der Einsatz eines Hubs, eines Switches oder aber die Bestückung eines Rechner mit zwei Netzwerkkarten an.
Hängen nun gar tausend Rechner an einem Strang, spielen plötzlich Faktoren wie Netzwerkbandbreite oder Ausfallsicherheit eine Rolle, die im privaten Versuchsnetzwerk niemals zu einem Problem erwachsen. Schon stellt sich die Frage, ob es überhaupt sinnvoll ist, eine größere Anzahl Computer in einem einzigen Netzwerk zu vereinen. Aber ja doch! Das Internet ist doch auch nur ein Netzwerk und da tummeln sich schließlich Millionen von Rechnern! Wie sollten da die 1000 Rechner in meinem Netz ein Problem darstellen?
Stellen Sie sich vor, Sie säßen mit 999 anderen Leuten in einem großen Raum. Allmählich bilden sich kleine Diskussionrunden zu je zwei Teilnehmern. Je mehr Gespräche in Gang kommen, desto höher wird die Lautstärke. Bald wird der Geräuschpegel eine Schwelle überschreiten, bei dem Sie ihrem Gegenüber nur noch unvollständig folgen können. »Wie bitte?« wird Ihre wichtigste Botschaft.
Ebenso verhält es sich in der Computerwelt. Drängeln sich zu viele Rechner um die Bandbreite eines Netzwerkes, wird es irgendwann zu einer Sättigung kommen, wo ein beachtlicher Teil der Kommunikation einzig dazu dient, fehlerhafte Daten erneut auszutauschen, weil einzelne Pakete durch gleichzeitiges Senden mehrerer Rechner kollidierten und damit unbrauchbar wurden. Die wiederholte Datensendung bedeutet allerdings zusätzliche Netzwerklast; eine Verschärfung der Situation ist vorprogrammiert.
Jetzt ist es unmöglich, eine pauschale Grenze anzugeben, wie viele Rechner in einem Netzwerk integriert sein sollten. Das hängt ebenso stark vom Nutzungsprofil ab, wie auch von der Bandbreite des Übertragungsmediums und von weiteren Faktoren.
Dieser Abschnitt soll deshalb zunächst einen Abriss vermitteln, welche Technik heute in welchem Umfeld zum Einsatz gelangt. Er soll Begriffe erläutern, eingesetzte Techniken benennen und auch Alternativen präsentieren. Aber neben all der Theorie spannen Fakten zu IP-Adressen, Subnetzen und zur Paketvermittlung den Bogen zur Praxis.
| LAN, WAN und andere Begriffe |
|
LAN (Local Area Network) hat sich im Sprachgebrauch als Begriff für das lokale Netz etabliert. Was aber bedeutet lokal?
Lokal hat zunächst einmal etwas mit der räumlichen Ausdehnung zu tun. Genauso wie sich mancher Mitbürger kaum mehr vorstellen kann, dass Distanzen über 5 Kilometer durchaus mit den eigenen Füßen überbrückt werden können, während der Leistungswanderer erst jenseits der 50km eine Beanspruchung verspürt, genauso weit gestreut ist die Definition von der Ausdehnung eines lokales Netzwerks. Es reicht von wenigen Metern bis zu 10km, wobei die Grenzen fließend sind.
Wohl eindeutiger hinsichtlich der Abgrenzung zu WANs (Wide Area Networks) ist der Erklärungsversuch bez. der Übertragungsgeschwindigkeit. Hier geht man von 10..100 (1000) Mbit/Sekunde aus, wobei der geklammerte Ausdruck die noch gering verbreitete Technik des Gigabit-Ethernets repräsentiert.
Drittes Kriterium eines lokalen Netzes ist sein homogener Aufbau, da (fast immer) alle Rechner durch ein und dieselbe Technologie miteinander verbunden sind. Wichtigster Vertreter der LAN-Technik ist das Ethernet, aber auch Token Ring, Fiber Distributed Data Interface (FDDI), Asynchron Transfer Mode (ATM), Funknetze, Myrinet oder Scalable Coherent Interface (SCI) gliedern sich in diese Sparte ein.
Die Weitverkehrsnetze (WAN) hingegen verbinden mehrere lokale Netze. Der Wirkungsbereich der dahinter stehenden Betreiber beschränkt sich zumeist auf ein Land, häufig existieren mehrere WANs parallel und überschneiden sich in ihrer Ausdehnung.
Aus Kostengründen werden im WAN nicht annähernd solche Übertragungsraten angeboten wie es in lokalen Netzen der Fall ist. Typische Raten liegen bei unter 2 MBit/Sekunde. Durch Bündelung von Kapazitäten findet man aber auch Angebote von wesentlich mehr als 100 MBit/Sekunde (ISDN H12 = 140 MBit/Sekunde).
Als Techniken zur Datenübertragung dominieren nach wie vor Telefonnetz und ISDN. Das deutsche Forschungsnetz (DFN) basiert auf X.25. Aber auch Funklösungen sind im Einsatz.
I.A. muss für die Benutzung von WAN-Angeboten eine Gebühr entrichtet werden. Entweder in Form einer Leitungsmiete oder durch Verrechnung des produzierten Datenaufkommens.
Ein GAN (Global Area Network) ist eher ein abstrakter Begriff. Hinter ihm steht nicht wirklich eine Technik, sondern es bezeichnet nur die Verbindung mehrere LANs und WANs. Das Internet ist der bekannteste Vertreter dieser Zunft.
| Topologien |
|
Die Topologie beschreibt die logische Verbindungsstruktur eines Netzwerks. In der Theorie scheint die Klassifizierung eindeutig. Praktisch finden sich allerdings häufig Mischformen, deren eindeutige Zuordnung zu einer Topologie eine Frage der Betrachtungsweise ist.
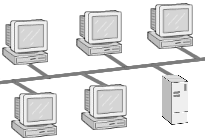
Abbildung 1: Die Busstruktur
Fakt ist, dass die Busstruktur (Abbildung 1) das verbreitetste Schema der Rechnerverbindung darstellt. Alle Rechner eines Netzwerks teilen sich denselben Bus, genauso wie es rechnerintern Prozessor, Speicher und Peripherie handhaben. Analog zum Systembus eines Computers ist auch die mögliche Anzahl der Rechner an einem Netzwerk-Bussystem begrenzt. Kritisch bei Bussystemen ist die Zugangssteuerung zum Verbindungsmedium, da zu einem Zeitpunkt stets nur eine Verbindung aktiv sein kann. Die Verfahren reichen von vorsorglicher Vermeidung konkurrierender Zugriffe bis hin zur Erkennung von Kollissionen. Der typische Vertreter bez. LANs ist das Ethernet.
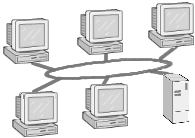
Abbildung 2: Die Ringstruktur
Vor allem mit Token Ring hat bei lokalen Netzwerken die Ring-Topologie als Vertreter der so genannten Punkt-zu-Punkt-Verbindungen eine gewisse Verbreitung erlangt. Ein Rechner kann (theoretisch) nur mit seinen unmittelbaren Nachbarn kommunizieren. Eine Verbindung zu weiteren Rechnern im Ring gelingt nur unter Verwendung der Zwischenrechner als »Vermittlerstationen«. »Theoretisch« deutet bereits eine weitere Einschränkung an, da in praktischen Vermittlungsverfahren in Ringstrukturen die Kommunikation nur in eine Richtung funktioniert, d.h. ein Rechner kann bspw. direkt zu seinem rechten Nachbarn senden, benötigt aber alle weiteren Rechner, um dem linken Nachbarn ein Paket zukommen zu lassen. Ring-Netzwerke arbeiten ausschließlich mit »Token«, einem Rahmen, der fortwährend im Ring kreist und in den ein Rechner - insofern das Token nicht belegt ist - seine Nachricht platzieren kann. Der Zielrechner entnimmt dem Token die Daten und markiert dieses wieder als frei, sodass ein anderer sendewilliger Rechner das Token nun belegen kann. Dieses Token-Verfahren kann ebenso auf reinen Bussystemen angewendet werden.
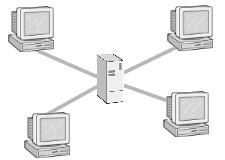
Abbildung 3: Die Sternstruktur
Die Beschreibung der Sternstruktur ist simple: Jeder Rechner im Netzwerk ist direkt mit der zentralen Komponente verbunden, welche im einfachsten Fall auf einer Leitung eintreffender Daten diese auf alle anderen Leitungen durchreicht. Betrachtet man die Struktur realer Ethernet- und Token-Ring-Netzwerke, wird man immer wieder auf Analogien zur Sternstruktur stoßen.
Ein auf Ethernet basierendes LAN größeren Umfangs besteht nur selten aus einem einzelnen Bussystem. I.d.R. werden mehrerer solcher Busse gekoppelt, häufig gar in einer zentralen Komponente (allgemein als »Sternkoppler« bezeichnet) , sodass tatsächlich eine Sternstruktur resultiert. Je nach »Intelligenz« der Komponente fügt sie die einzelnen Stränge des Netzes zu einem großen Bussystem zusammen, indem sie alle Daten ohne Rücksicht auf deren Zieladresse in jeden Anschluss einspeist oder aber sie »filtert« die Pakete und reicht sie nur in den Teil des Netzwerks weiter, in dem der Empfängerrechner liegt.
Auch bei Token-Ring-Netzwerken mit mehreren Teilnehmern werden keine kilometerlangen Leitungen verlegt. Der Ring selbst ist in einem einzelnen Hardwarebaustein (»Ringleitungsverteiler«) realisiert, von welchem aus Stränge zu den einzelnen Rechnern gehen. Rein optisch gleicht es somit einem Stern.
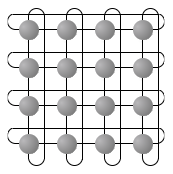
|
|
Abbildung 4: 2D-Torus |
Abbildung 5: Hypercube (3. Dimension) |
Sind hiermit alle Topologien genannt? Mitnichten! Einzig die für lokale Netzwerke relevanten Strukturen wurden erwähnt. Verbindungsnetzwerke gänzlich anderer Art finden sich in zahlreichen Parallelrechnern. Gerade dort kommt es auf kürzeste Signalwege bei maximaler Bandbreite an. Während Bus- und Ringstrukturen nur bei kleineren Modellen (< 64 Prozessoren) von praktischen Nutzen sind, gelangen bei so genannten massiv-parallelen Rechnern Gitterstrukturen, Tori (Gitter, deren Außenknoten miteinander gekoppelt sind), Hypercubes oder Baumstrukturen u.a.m. zum Einsatz. Auch dynamisch erzeugte Verbindungen (Kreuzschienenverteiler, Delta-Netzwerke) sind eine Domäne der Parallelrechentechnik.
| Die Elemente eines Netzwerks |
|
Um die einzelnen Endgeräte (Computer, Terminals, Netzwerkdrucker etc.) miteinander zu koppeln, gelangen verschiedenste Komponenten zum Einsatz. Eine grobe Unterteilung erfolgt anhand der Signalbehandlung. Für Bauteile, die Signale unverändert weiterreichen, wird oft der Begriff der passiven Komponente angewandt. Demzufolge sind aktive Komponenten Elemente, die eine Signalaufbereitung vornehmen. Den Aufgaben der wichtigsten Verteter beider Gruppen soll sich die folgende Abhandlung widmen.

Abbildung 6: Verbreitete Steckverbindungen
Zu den passiven Bauelementen zählen die Steckverbindungen und Kabel. Erstere werden in lokalen Netzwerken in den Ausführungen BNC und RJ45 angeboten.
BNC wird im Zusammenhang mit 10base2 (»Ethernet-Jargon« für Koaxial-Kabel) benutzt. Die Anbindung einer Station erfolgt entweder durch Auftrennung des Kabels und Einfügen eines BNC-T-Stücks (Abbildung 6) oder auch ohne Unterbrechung des Leiters (»Vampirstecker«). Im Falle dieser klassischen Bus-Topologie müssen alle freien Enden durch einen Abschlusswiderstand »geschlossen« werden, da Pakete ansonsten an diesen reflektiert werden und nachfolgende Pakete damit verwischen würden (Abbildung 7).
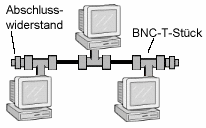
Abbildung 7: Koax-Netz
RJ45 ist die zum 10BaseT ([Un]shieled Twisted Pair) Anschluss passende Verbindung. Im Zusammenhang mit
Ethernet bedingen Twisted-Pair-Kabel den Einsatz von aktiven Verteilerelementen (Bridges), um die einzelnen
Stationen miteinander zu verbinden (daraus resultiert eine Sternstruktur).
Die Leistungsdaten eines Netzwerks werden durch die Kabel bestimmt, die Ausführung der
Steckverbindungen ist letztlich irrelevant.

Abbildung 8: Verkabelungstechnik
Die einzusetzende Kabeltechnik hängt vor allem von zwei Faktoren ab. Zum einen von der Anzahl der Teilnehmer im Netz und somit von der benötigten Bandbreite und zum zweiten vom finanziellen Budget, das der Chef zur Verkabelung zur Verfügung stellt.
In beider Hinsicht die Höchstnoten verdienen sich Lichtwellenleiter, wobei Monomode-Leiter die Daten schneller übertragen und die Kosten rasanter in die Höhe katapultieren als die technisch einfacher herzustellenden - weil dickeren - Multimode-Leiter. Je dünner das Medium, desto geradliniger muss ein Lichtstrahl hindurch. Und die Gerade ist bekanntlich die kürzeste Verbindung zwischen zwei Punkten. Ein nicht unwesentlicher Kostenfaktor sind die notwendigen Umsetzer, die die elektrischen Signale in Lichtimpulse und umgekehrt wandeln. Wohl wegen der Kosten finden sich Lichtwellenleiter vorwiegend in so genannten Backbones, also Hochgeschwindigkeits-Verbindungen zwischen räumlich getrennten Teilen eines Netzwerks. Ein anderes Anwendungsfeld erschließt sich durch dessen Unempfindlichkeit gegenüber elektromagnetischer Einflüsse.
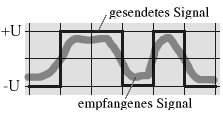
Abbildung 9: Störeinflüsse auf die Signalübertragung
Wegen fehlender Unterstützung von Hochgeschwindigkeitstechnologien nimmt die Verbreitung des Einsatzes von Koaxial-Kabeln weiterhin ab. Die »dickere« Ausführung (Thick Koax) ist gar noch seltener anzutreffen als das »schlankere« Thin Koax. Thick Koax ermöglicht theoretisch den Anschluss von mehr Stationen (ca. 100) pro Kabelsegment als Thin Koax (32) und auch größere Segmentlängen (bis zu 500m gegenüber 185m). Allerdings bedingt Thick Koax auch eine aufwändigere Abschirmung, um das Signal über die weiten Wege stabil zu halten und das spiegelt sich im Preis wider. Auch zeigte die Praxis, dass der Aufbau von Netzwerken, die aus vielen »kleinen« Segmenten bestehen, sowohl den möglichen Durchsatz als auch die Ausfallsicherheit erhöht (vergleiche: Entkopplung durch Bridges). Bei beiden Typen von Koaxialkabeln ist die Übertragungsgeschwindigkeit auf maximal 16 MBit/s begrenzt.
Obwohl die Eigenschaften der Koaxial-Kabel prinzipiell höhere Übertragungsgeschwindigkeiten als Twisted-Pair-Kabel (»verdrillte Vierdrahtleitung«) zulassen, genügt letztere Verkabelungstechnik vollkommen zum Aufbau eines 100 MBit-Ethernets. Und auch hier erwies sich, dass die teureren geschirmten Twisted-Pair-Kabel den günstigeren ungeschirmten gegenüber kaum Vorteile bringen.
Die wichtigste Komponente, um einen Rechner in ein Netzwerk zu integrieren, ist die Netzwerkkarte (oft als Network Interface Card NIC bezeichnet). Für jeden Netzwerktyp existieren eigene Karten, die den Zugang zum Medium ermöglichen; die Karte muss also zum Netzwerk »passen«. Die Aufgaben der Netzwerkkarte bestehen im Senden und Empfangen von Daten.
In Netzen größerer Ausdehnung (wobei »größer« von Netzwerktyp, Verkabelung usw. abhängig ist) ist ggf. eine Signalverstärkung notwendig, um die Daten auch über weite Distanzen unverfälscht übertragen zu können. Repeater verbinden hierzu zwei Kabelstränge miteinander und leiten die elektrischen Impulse verstärkt vom jeweils einen Kabelsegment in das andere. Um Routingprobleme zu verhindern, sind beim Einsatz von Reaptern einige Regeln zu beachten. So darf es zwischen zwei Stationen nur exakt einen Weg durch das Netz geben. Um ein stabiles Signal zu gewährleisten, dürfen zwischen zwei Empfangsstationen maximal 4 Repeater geschaltet sein; auch dürfen maximal 3 der 5 Segmente mit Koax-Kabeln realisiert werden.
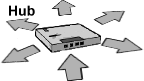
Für Repeater mit mehr als zwei angeschlossenen Segmenten hat sich der Begriff des Hub etabliert. Ein Hub leitet das in einem Anschluss ankommende Signal verstärkt auf alle anderen Anschlüsse (oft 5, 8 oder 16) weiter. Ein Port des Hubs ist als so genannter Uplink-Port ausgelegt, der zum Anschluss weiterer Hubs dient. Auf diese Art und Weise lassen sich große Netze aufbauen.
Hubs gibt es in Ausführungen mit Bandbreiten zu 10 MBit, 100 MBit und 10/100 MBit. Nur bei letzterer Variante können in einem Netz Rechner mit 10 MBit-Netzwerkkarten und solche mit 100 MBit-Karten kombiniert eingesetzt werden, wobei allerdings die Bandbreite für alle Stationen auf 10 MBit sinkt.
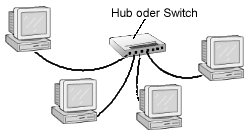
Abbildung 10: Hubs oder Switches verbinden Teilnetze
Quasi »intelligente Repeater« stellen Bridges (Brücken) dar, indem sie das Signal nicht nur verstärken, sondern für eine Lastentkopplung zwischen den beiden angeschlossenen Segmenten sorgen. Brigdes speichern hierzu die ankommenden Pakete, werten sie aus und leiten sie erst anschließend weiter (»Store&Forward«) und zwar nur, wenn der Empfänger im anderen Segment liegt. Intern halten sich Brücken hierzu Tabellen mit Hardwareadresse und zugehörigem Segment (nicht bei Token Ring); zum Standard gehört es unterdessen, dass die Brücken diese Tabelle dynamisch anpassen um auch auf Änderungen in der Netzkonfiguration reagieren können. Neben selbstlernenden Brücken lassen sich die »besseren« zusätzlich manuell konfigurieren (bspw. als einfacher Adressfilter).
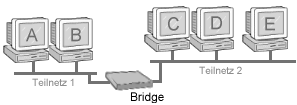
Abbildung 11: Brücke
Beispiel: Die Bridge aus Abbildung 11 wird alle Pakete aus Teilnetz 1 nach Teilnetz 2 leiten, wenn ihr Ziel der Rechner C, D oder E ist. Ein Paket von A an B bzw. B an A hingegen wird von der Bridge ignoriert. Pakete werden vom Teilnetz 2 in Teilnetz 1 vermittelt, wenn und nur wenn der Empfänger Rechner A oder B ist.
Durch den Einsatz von Brücken entfällt auch die Einschränkung herkömmlicher Repeater, dass es nur eine Verbindung zwischen zwei Empfängerstationen geben darf. Hierzu fungiert bei redundanten Strukturen eine Brücke als Master. Um welche es sich handelt, klären die Brücken in gegenseitiger Kommunikation. Ausgehend von der Masterbrücke werden Verbindungen gesucht, die zu weiteren Brücken führen. Ausgehend von jenen Brücken erfolgt wiederum die Suche nach weiteren bislang nicht erfassten Brücken. Der Algorithmus endet, wenn alle Brücken gefunden wurden. Per Software werden nachfolgend alle Verbindungen eliminiert, die im Suchergebnis zum wiederholten Male zu einer entfernten Brücke führten, sodass letztlich zwischen zwei Stationen nur genau ein Weg für den Datentransport übrig bleibt. Das Verfahren wird als Spanning Tree Algorithmus bezeichnet.
Des Weiteren führen moderne Brücken zusätzlich eine Überprüfung der Pakete auf Korrektheit durch. Da notwendige Zwischenspeicherung und Prüfung Zeit beanspruchen, gehört der Durchsatz »Datenpakete pro Sekunde« zu den Kenndaten einer Bridge. Arbeitet eine Brücke mindestens so schnell wie das angeschlossene Interface, wird sie als wirespeed bezeichnet.
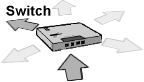
Bei Switches handelt es sich um Multiport-Brücken. Äußerlich gleichen Switches somit den Hubs, jedoch bieten sie die Funktionalität einer Bridge. Die herausragende Eigenschaft von Switches ist die Bereitstellung der vollen Bandbreite unabhängig von der Zahl der angeschlossenen Rechner.
Indem der Hub ein einkommendes Signal an einem Port auf alle ausgehenden Ports legt, erscheinen alle angebundenen Stationen in einem einzigen großen Netz. Diese Stationen müssen sich die verfügbare Übertragungskapazität teilen.
 |
 |
|
Abbildung 12: Datentransport im Hub |
Abbildung 13: Datentransport im Switch (nach Lernphase) |
Ein Switch hingegen leitet das Paket nur an den Port weiter, in dessen Segment sich auch der Empfänger befindet. Switches mit entsprechender Leistung können parallel mehrere »virtuelle« Verbindungen zwischen verschiedenen Ports gleichzeitig aufbauen, wobei für jede Verbindung die volle Übertragungsbandbreite zur Verfügung steht.
Wie auch Hubs lassen sich Switches über einen Uplink-Port kaskadieren.
Während alle bisher genannten Komponenten typisch für ein lokales Netzwerk sind, dient ein Router vorrangig zur Verbindung mehrerer unabhängiger Netzwerke. Ein Router entscheidet anhand der in einem IP-Paket enthaltenen Empfängeradresse und seiner (dynamisch aktualisierten) Routing-Tabelle, in welches der angeschlossenen Netzwerke die Daten weiterzuleiten sind. Dabei ist ein Router auch in der Lage, Netzwerke unterschiedlicher Topologie miteinander zu koppeln. Während vor einigen Jahren ausschließlich teure Spezialhardware als Router zum Einsatz gelangte, wird heute auch gern ein (Linux)Rechner mit dieser Aufgabe betraut. Bei geringem zu erwartenden Datenaufkommen genügt ein älterer Prozessor (Pentium I, K5) durchaus; für stark frequentierten Knotenpunkte ist selbst ein schneller Bolide deutlich preiswerter als ebenbürtige Spezialhardware.
LAN-Router gleichen ihre internen Tabellen mit denen benachbarter Router über das Routing Information Protocol (RIP) oder mittels des neueren Open Shortest Path First (OSPF) ab. WAN-Router verständigen sich über Exterior Gateway Protocol (EGP) oder das Border Gateway Protocol (EGP) . Eine spezielle Ausführung - so genannte B-Router - vereinen die Funktionen von Bridge und Router und arbeiten, je nach eintreffendem Paket, als das eine oder das andere. In Netzwerken größerer Dimension kann sich der Einsatz von Routern anstatt von Brücken auszahlen, da Router die Pakete über den »best möglichen« Weg weiter leiten. Während Bridges zu große Pakete verwerfen, fragmentieren Router diese bei Bedarf. Auch bieten Router einen einfachen Schutz gegen »Broadcast-Stürme«.
Verbindet ein Rechner gar Netzwerke unterschiedlicher Technologie (bspw. IP und IPX), so wird eine Protokollumsetzung (des IP-Protkollstacks) notwendig. Für diese über die Aufgaben eines normalen Routers hinausgehenden Aufgaben gelangen Gateways zum Einsatz. Dass Linux auch als Gateway betrieben werden kann, sollte kaum mehr verwundern...
| Ethernet |
|
1972 startete Xerox in Pala Alto die Experimente mit einem Vorläufer des heutigen Ethernets, dem Alto Aloah Network, deren erste Ergebnisse erst 1976 der Öffentlichkeit vorgestellt wurden. Auf Basis dieser Arbeit entwickelte eine Gruppe aus DEC, Intel und Xerox, die sich 1979 zusammengefunden hatte, eine erste Spezifikation Ethernet V 1.0 (1980). Der Name Ethernet - ein Kunstgefüge aus Äther und Netz - wurde gewählt, um die prinzipielle Unterstützung jedes Computertyps durch die Technologie zu untermauern.
Der IEEE diente diese Spezifikation maßgeblich als Vorlage für einen Standard für LAN's, der 1982 als 802.3-Standard (10Base5) verabschiedet wurde. Die Weiterentwicklung Ethernet V. 2.0 (1985) wurde schließlich in den ISO-8802.3-Standard überführt.
Weitere Standards legten die Richtlinien für 10Base2 und das kaum verbreitete 10BroadT (1985) fest. 1988 wurde Ethernet in Verbindung mit Twisted-Pair eingeführt, was den noch heute weit verbreiteten Standard 10BaseT (1991) formulierte. Schließlich hielt 1995 mit 100BaseT ein Standard Einzug, der wohl eher unter dem Begriff Fast Ethernet geläufig ist.
Während Produkte des Gigabit-Ethernets über Glasfaserkabel (802.3z, 1998) und über Kupferleitungen (802.3ab, 1999) trotz der langen Verfügbarkeit nur selten anzutreffen sind, steht der nächste Standard des 10 Gigabit-Ethernets bereits zur Debatte.
Und was hat es mit den Bezeichnungen 10Base5... auf sich? Die erste Zahl gibt die Bandbreite in MBit/s an, Base steht für Basisband- und Broad für Breitbandübertragung. "2" bzw. "5" geben in Zusammenhang mit Koaxialkabel die maximale Segmentlänge in 100m-Einheiten an; ein "T" kennzeichnet eine Twisted-Pair-Verkabelung. Seltener wird man ein "F" vorfinden, was auf ein Ethernet auf Basis von Lichtwellenleitern hinweist.
Jede Station in einem Ethernet arbeitet unabhängig von den anderen; es existiert keine zentrale Instanz, die die Kommunikation auf dem gemeinsamen Medium regelt (Medium soll hier allgemein für das Verbindungssystem stehen, bspw. Twisted-Pair-Kabel).
Signale werden bitweise übertragen, wobei jede am Medium angeschlossene Station jedes Signal empfängt. Wünscht eine Station zu senden, so »lauscht« sie zunächst auf dem Medium, ob zur Zeit eine Übertragung im Gange ist. Trifft dies zu, wartet die Station eine zufällige Zeitspanne und lauscht dann erneut. Ist die Leitung frei, schickt die Station das Paket, verpackt in einen definierten Rahmen (Ethernet Frame) auf die Reise. Nach Abschluss einer jeden Übertragung müssen sich stets alle sendewilligen Stationen neu um den Zugang zum Medium bewerben. So ist sichergestellt, dass der Zugang zum Medium fair abläuft und keine Station »verhungert«, weil andere permanent Daten durch das Netz schicken.
Nun kostet jede Übertragung bekanntlich Zeit. Und weil eine Station soeben ihr Paket versendet, da sie das Medium als frei erkannte, könnte zur gleichen Zeit eine andere Station genau zu demselben Schluss gelangt sein und schickt ihrerseits Daten auf die Strecke. Eine Kollision der Pakete und damit die Unbrauchbarkeit ihrer Inhalte sind die Folge. Um für solche Situationen gewappnet zu sein, definiert das CSMA/CD-Protokoll (Carrier Sense Multiple Access with Collision Detection) exakte Regeln für den Medienzugriff.
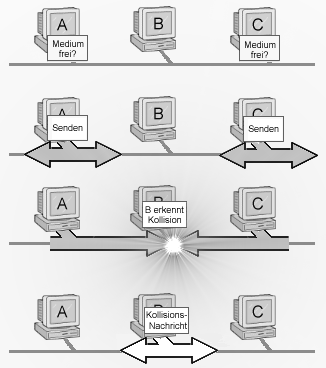
Abbildung 14: Prinzip des CSMA/CD-Verfahrens
Nach CSMA/CD lauschen alle beteiligten Stationen permanent auf dem Medium. Das müssen sie ja auch, um für sie bestimmte Daten erkennen zu können.
Gedenkt eine Station nun zu senden, so wartet sie, bis das Medium frei ist (Carrier Sense). Nach einer Zeitspanne von 9,6 Mikrosekunden beginnt die Station mit der Übertragung. Diese Zeitspanne entspricht genau dem vorgeschriebenen Mindestabstand zwischen zwei Ethernetpaketen.
Mit Beginn des Sendevorgangs hört die Station weiterhin das Medium ab, um eine eventuelle Kollision mitzubekommen (Collision Detection). Trat keine Kollision auf, erkennt die Zielstation anhand der im Paket vermerkten Adresse die für sie bestimmten Daten, empfängt sie und die Übertragung ist somit beendet.
Da aber der Zugang zum Medium im Ethernet für alle Stationen gleichberechtigt ist (Multiple Access), sind Kollisionen nicht ausgeschlossen, weil zwei oder mehrere Stationen nahezu zeitgleich den Sendevorgang anstrengten und das Medium als frei erkannten. In dem Fall wird durch Überlagerung der Signale der Inhalte der Pakete zerstört. Die Station, die die Kollision zuerst registrierte, schickt deshalb ein spezielles »Überlagerungssignal« aus, worauf die sendenden Stationen mit sofortiger Einstellung ihrer Übertragung reagieren.
Die Stationen, deren Senden mit einer Kollision endete, wiederholen den Sendevorgang nach Ablauf einer (relativ) zufälligen Wartezeit. Kommt es wiederholt zu einer Kollision, so wird die »Auszeit« stetig erhöht.
CSMA/CD vermeidet also keine Kollisionen, minimiert jedoch durch die interne Verfahrensweise (flexible Wartezeiten) die Wahrscheinlichkeit ihres Auftretens.
Daten, die über ein Ethernet übertragen werden, werden nochmals in einen Rahmen verpackt. Die Rahmen können geringfügig zwischen den verschiedenen Ethernet-Standards differieren; über eine Präambel, die Ziel- und Absenderadresse sowie über eine Prüfsumme verfügen sie jedoch alle, sodass die Darstellung aus Abbildung 15 (Ethernet V2.0) durchaus repräsentativen Charakter besitzt.

Abbildung 15: Ethernet-Frame
Die Präambel enthält die Bitfolge "010101...01". Sie ermöglicht den Stationen, den Beginn eines Pakets zu erkennen. Bei Ethernet nach IEEE 802.3 wird das 8. Byte »Start Frame Delimiter« genannt; wobei dessen Wert sich nicht vom 8.Byte des Ethernet-Frames nach V2.0 unterscheidet.
Die Adressen des Empfängers und Absenders umfassen jeweils 48 Bit. Die »oberen« 24 Bit dieser so genannten MAC-Adresse werden einem potentiellen Kartenhersteller vom IEEE zugewiesen; die »unteren« 24 Bit vergibt der Hersteller, wobei er jede Adresse nur einmalig an eine Karte vergibt. Die gesamte Hardwareadresse ist fest in die Firmware der Karte »eingebrannt«. Bei manchen Karten kann sie umkonfiguriert werden, wobei beachtet werden muss, dass sie im lokalen Netz stets eindeutig ist.
Der Typ kennzeichnet das eingebettete Protokoll; zumeist wird hier 2048 als Kennzeichnung des IP-Protokolls stehen. Nach 802.3-Standard steht hier stattdessen die Länge des Pakets ohne Präambel.
Zwischen 46 und 1500 Bytes Nutzdaten können in den Rahmen eingebettet werden, sodass ein Ethernet-Paket eine Gesamtlänge von maximal 1526 Bytes besitzt.
Eine über das Gesamtpaket gebildete Prüfsumme (CRC) ermöglicht dem Empfänger, Übertragungsfehler zu erkennen.
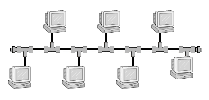
Abbildung 16: Busstruktur des 10Base2
Als Vertreter der klassischen Busstruktur des Ethernets hat sich einzig 10Base2 bis in heutige Zeit gehalten. Das Argument für den Einsatz der Technik - die Ersparnis der Kosten für eine zentrale Kopplerkomponente - hat sich jedoch mit sinkenden Hardwarepreisen verflüchtigt, was kurz über lang wohl auch für 10Base2 selbst zutreffen wird.
Als Verbindungsmedium gelangt ausschließlich Koaxial-Kabel zum Einsatz, an das mittels BNC-T-Steckern die Stationen angeschlossen werden. Die Enden des Kabel müssen mit einem Endwiderstand (»Terminator«) abgeschlossen werden. Maximal 32 Stationen lassen sich an einem Kabelsegment betreiben, wobei der Mindestabstand zweier Anschlüsse 0.5m und der maximale Abstand 185m beträgt.
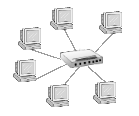
Abbildung 17: Sternstruktur des 10BaseT
Die physische Struktur heutiger Ethernet-Installationen gleicht zumeist einem Stern. 10BaseT war die erste Realisierung eines Ethernets, die zum Anschluss der Stationen auf eine zentrale Komponente (Hub oder Switch) setzte. Zur Verbindung dient zumeist Twisted-Pair-Kabel, wobei die Auslegung des zentralen Koppelelements die maximale Anzahl zu verbindender Stationen bestimmt. Typische Hubs verfügen über 5, 8 oder 16 Anschlüsse; aber auch Ausführungen mit 150 und mehr Anschlüssen sind erhältlich. Die maximale Kabellänge zwischen Station und Koppelkomponente darf 100m nicht übersteigen.
Zum Aufbau größerer Netzwerke lassen sich mehrere Koppelelemente miteinander verbinden.
Beide Typen unterscheiden sich vom 10BaseT einzig hinsichtlich des Übertragungsmediums und der Schnittstellenadapter; d.h. auch ihre Grundstruktur formt einen Stern.
Um die Übertragungsraten von 100 MBit zu erzielen, gelangt bei 100BaseT ein aufwändiger verarbeitetes Twisted-Pair-Kabel (»Typ 5«; ein Typ legt die elektrischen Eigenschaften fest) zum Einsatz, als es für 10Base2 (»Typ 3«) erforderlich ist; auch die Netzwerkkarte muss für die hohen Datenraten gewappnet sein. Aktuelle Karten, die 100 MBit unterstützen, beherrschen i.d.R. ebenso den 10 MBit-Datentransfer; so dass sie ggf. die Geschwindigkeit anpassen, falls ihr »Gegenüber« nur die gemächlichere Korrespondenz beherrscht.
Datenraten von 1000 MBit/Sekunde im Gigabit-Ethernet werden entweder über Glasfaserleitungen oder über geschirmte Twisted-Pair-Kabel erzielt. Vor allem wegen der extrem teuren Netzhardware (Hubs, Repeater) sind Gigabit-Lösungen heute fast ausschließlich im Backbone-Bereich zur Kopplung separater Netzwerke zu finden.
| Token Ring |
|
Neben Ethernet hat sich lange Zeit einzig IBM's Token Ring als LAN-Technologie durchsetzen können, wenn auch bei weitem nicht mit dem durchschlagenden Erfolg, der dem Ethernet beschieden war. Dabei entstand das Konzept des »kreisenden« Tokens bereits Anfand der 70er Jahre (Willemjin) bei IBM. Vielleicht ließ sich IBM mit der Vorstellung eines ersten Prototypen (1983) einfach zu viel Zeit; als IEEE802.5 endlich als Standard anerkannt wurde (1985), dominierte Ethernet schon längst den Markt.
Die ersten Realisierung mit ihrer »IBM Typ 1«-Verkabelung (Shield Twisted Pair) arbeitete gerade mal mit einer maximalen Datenrate von 4MBit/Sekunde. Einigermaßen Verbreitung hat die Unshield-Twisted-Pair-Verkabelung mit 16MBit/Sekunde Übertragungsrate gefunden. Standards für »Fast Token Ring« (100 MBit/Sekunde) und »Gigabit Token Ring« existieren zwar seit Jahren, haben sich aber nicht durchsetzen können. Die Vermutung liegt nahe, dass Token Ring in naher Zukunft gänzlich an Bedeutung verliert.
In einer Hinsicht ist Token Ring dennoch dem Ethernet überlegen. Es hat weit weniger mit Reichweitenbeschränkungen zu kämpfen; selbst Netzwerke mit mehreren Kilometern Ausdehnung ohne zusätzliche Koppelhardware sind möglich.
Warum wir es dennoch erwähnen, liegt an dem besonderen Verfahren der Regelung des Medienzugangs, das eine »faire« Behandlung aller Stationen bei Vermeidung von Kollisionen garantiert.
Die logische Struktur eines jeden Token-Ring-Netzwerkes ist der Ring; physisch wird sogar ein Doppelring eingesetzt (Abbildung 19). Zwar könnte jeder der Ringe für die Datenübertragung herhalten, jedoch wird in der Praxis der zweite Ring nur als Backuplösung verwendet, der sich selbsttätig zuschaltet, wenn der andere Ring unterbrochen wird.
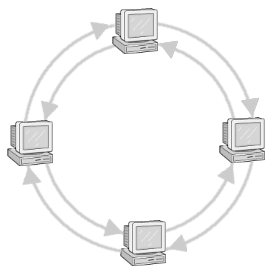
Abbildung 19: Typisch für Token Ring ist der Doppelring
Für die Praxis hat obige Anordnung jedoch entscheidende Nachteile. Da jeder Rechner doppelt mit seinen beiden Nachbarn verkabelt wäre, ließe sich ein solches Netzwerk nur aufwändig erweitern. Auch wären enorm lange Kabel zur Verbindung erforderlich. Deshalb ähneln Token-Ring-Installationen eher einer Sterntopologie. Der Ring ist in einem so genannten Ringverteilungsleiter realisiert, von dem aus sternförmig die Stränge zu den Client verlaufen.
Die Steckverbindungen im Ringverteilungsleiter zum Anschluss der Clients sind so konzipiert, dass sie den Ring selbstständig schließen, sollte der Client abgeschlossen oder die Verbindung zu diesem gestört sein. Damit wird der zweite Strang, der formals als BAckuplösung angedach war frei. Er dient nun der Verbindung mehrerer Ringverteilungsleiter untereinander, um auch größere Netzwerke realisieren zu können.
Im Ring kreist ständig eine spezielle Signalfolge - das Token - dessen Aufbau Abbildung 20 zeigt.
Abbildung 20: Tokenformat
Framestart und Frameende sind dabei Bitmuster, die von der eigentlichen elektrischen Bitkodierung des Token Rings abweichen (indem der Pegelsprung bewusst verlegt wird) und somit das Token eindeutig als solches identifizieren. Das Token selbst beinhaltet einen 3-stelligen Prioritätswert. Ein sendewillige Station darf das Token nur dann vom Ring nehmen und durch ein Datenpaket ersetzen, wenn ihre Daten eine gleichwertige oder höhere Priorität besitzen. Die nächste Priorität kann von einer Station gesetzt werden, um die Priorität der übernächsten Runde zu bestimmen. Die übernächste deshalb, weil nach einer Datenübertragung stets eine Runde mit Priorität 0 folgt. Somit wird sichergestellt, dass auch Stationen mit »weniger wichtigen Daten« zum Zuge kommen.
Das mit T gekennzeichnete Bit gibt an, ob es sich um ein Token oder um ein Datenpaket handelt (bei letzterem unterscheiden sich die folgenden Bytes). M ist das Monitorbit (siehe Abschnitt »Was ist bei Verlust des Tokens?«).
In den beiden letzten Bits des Frameende-Bytes sind der Erkennung gesplitteter Datenpakete (Bit ist gesetzt, wenn das Gesamtpaket aus mehreren Teilen besteht; bei leerem Token ist das Bit stets 0) und die Fehleranzeige kodiert.
Die drei beschriebenen Bytes tauchen mit identischer Bedeutung auch bei einem Datenpaket auf, dessen Aufbau Abbilungs 21 zeigt.

Abbildung 21: Token-Ring Datenpaket
Quell- und Zieladresse sind letzlich Hardwareadressen, die i.d.R. einer Karte fest zugeordnet und, da sie vom Hersteller vergeben wurden, eindeutig sind. Der Adresstyp (Geräte-, Broadcast-, ...Adresse) ist in den ersten Bits einer jeden Adresse kodiert.
Die beiden ersten Bits der Framekontrolle kennzeichnen den Typ des Pakets (Token-Ring-Steuerpaket oder Datenpaket). Zwei weitere Bits werden nicht verwendet, während die letzten Bits Informationen zur Pufferung der Daten enthalten.
Über das gesamte Paket mit Ausnahme des Frame Status wird eine Prüfsumme gebildet und im entsprechenden Feld abgelegt.
Im Byte Framestatus hinterlegt der Empfänger eine Quittung. Erkennt er, das ein Paket für ihn bestimmt ist, setzte der Empfänger die Bits 0 und 4. War der Empfang korrekt, setzt er ebenso die Bits 1 und 5. Die Doppelung soll die Fehleranfälligkeit verringern, da Framestatus nicht durch die Prüfsumme erfasst ist.
Der Verlust des Tokens wäre wohl der schlimmeste offensichtliche Fehlerfall. Aber er ist bei weitem nicht der Einzige. Die Erkennung und BehebungFolgender Fehler muss im Ring gewährleistet sein:
Um solcher Fehler zu erkennen, wird eine Station zum so genannten Monitor ernannt. Diese Station ist fortan für das (Rück)Setzen des Monitorbits im Frame verantwortlich.
Ein Auswahlverfahren im Token Ring stellt sicher, dass zu einem Zeitpunkt nur eine Station die Monitorfunktion ausführt.
Eine sendewillige Station, die das Token erhält, initialisiert das Monitorbit mit 0. Die Station, die die Monitorfunktion ausübt, setzt beim Durchlauf des Paketes dessen Monitorbit auf 1. Kommt das Paket erneut beim Sender an, muss dieser dieses vom Ring nehmen (selbst wenn der Empfäger es nicht angenommen hat). Ist der Sender aber ausgefallen, erreicht das Paket die Monitorstation erneut. Sie erkennt anhand des gesetzten Monitorbits den wiederholten Durchlauf, beginnt mit der Neuinitialisierung des Token Rings und erzeugt anschließend ein neues Token. Um den Verlust des Tokens selbst zu erkennen, startet die Monitorstation bei jedem Durchlauf einen Timer. Läuft dieser ab, gilt das Token als verloren und die erneute Initialisierung startet.
| Asynchron Transfer Mode |
|
| Andere Technologien |
|
Bei Bluetooth handelt es sich um eine Funktechnologie, um verschiedenste Geräte über Distanzen bis zu maximal 100m zu vernetzen. Bluetooth verwendet hierfür ein frei zugängliches Frequenzband (2.4GHz).
Während der verschlüsselten Übertragung erfolgt 1600 mal pro Sekunde eine Frequenzsprung. Das garantiert zum Einen eine relativ verlässliche Abhörsicherheit und zum Anderen eine Konfliktvermeidung mit anderen Bluetoothgeräten der näheren Umgebung, da die Wahrscheinlichkeit, dass diese dieselbe Frequenz benutzen, gegen Null geht.
Übertragungsraten bis reichlich 700 kByte/s können mit der Technologie erreicht werden.
| IP-Adressen |
|
Um am Datenaustausch in TCP/IP-basierten Netzwerken teilzunehmen, benötigt der Rechner eine in seinem Netzwerk eindeutige IP-Adresse. Für jeden Teilnehmer im Internet folgt damit, dass seine Adresse weltweit eindeutig sein muss. Dass dies bei dem knappen 32-Bit Adressraum schon heute nicht mehr praktikabel ist, führte zu Techniken der Maskierung, wobei ein Rechner, der über eine offizielle IP-Adresse verfügt, stellvertretend für andere Rechner aus seinem Verwaltungsbereich im Internet auftritt. Aber derartige Belange sollen uns erst an anderer Stelle interessieren.
Mit 32 Bit Adressen ließen sich theoretisch 232 (4294967296) Rechner ansprechen. Praktisch ist es allerdings kaum zu realisieren, dass ein Rechner wahllos aus dem Pool der Adressen eine freie zugewiesen bekommt (zur Paketvermittlung müssten dann zumindest einige Rechner im Netz mit definiertem Standort die Adressen aller Teilnehmer verwalten). Ähnlich zu einer Telefonnummer, bei der das Ziel durch Länderkode, Ortswahl und Teilnehmernummer lokalisiert wird, werden IP-Adressen in Netzwerk- und Rechnernummer unterteilt. Die (klassische) Interpretation der 32 Bit ist abhängig vom ersten auf 0 gesetzten Bit (von links):
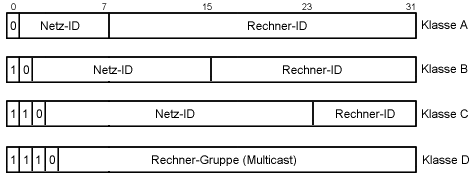
Abbildung 19: Adressklassen nach IPv4
Klasse A
Klasse B
Klasse C
Klasse D
Klasse E
Die 32 Bit einer IP-Adresse werden als Quadrupel zu je 8 Bits angegeben, wobei die dezimale Schreibweise bevorzugt angewendet wird. Bezugnehmend auf die ersten 8 Bit bedeutet dies für eine Adresse:
Die Klassenstruktur der IP-Adressen ist historisch bedingt, schien doch zu jener Zeit der Adressraum von 32 Bit als ungemein groß. Um die Suche nach dem Empfänger eines Pakets in vertretbarem (Zeit)Rahmen zu realisieren, bewertete ein Router eine Adresse nur anhand des Netzwerkteils; anstatt sich bspw. die 65535 Adressen eines beliebigen Klasse-B-Netzwerks zu merken, genügt dem Router somit ein einziger Eintrag für das Netz selbst, um den folgenden Empfänger eines Datenpakets auf dem Weg zu dessen Ziel zu identifizieren. Bei dem damaligen Stand der Rechentechnik war dies eine signifikante Erleichterung.
Aus heutiger Sicht erweisen sich die 32 Bit der IP-Adresse nicht nur als viel zu klein (und Abhilfe ist mit der 128 Bit-Adresse aus IPv6 bereits geschaffen worden), sondern das 3-Klassen-Schema zur allgemeinen Adressierung als zu starr. Die wenigen Klasse-A-Netzwerke beinhalten eigentlich zu viele Hostadressen, um sie direkt auf eine Netzwerkstruktur abzubilden; dementgegen sind die 256 Rechner aus den unzähligen Klasse-C-Netzen schon für die kleineren Organisationen oft zu wenig, sodass vor allem Klasse-B-Adressen lange Zeit heiß umworben waren. Doch auch ihre Zahl war schon bald erschöpft, womit neue Möglichkeiten der Adressinterpretation gefunden werden mussten.
Die Vergabe von Netzwerkadressen erfolgt heutzutage in zusammenhängenden Adressblöcken an Internet Service Provider (ISP). Die ISP reichen aus diesem Fundus Adressen an ihre Kunden weiter. Ein Router im Internet speichert nun für einen solchen Adressbereich nur noch eine einzige Adresse; an die alle Pakete mit Adressen aus dem Bereich geleitet werden. Die Router im Verantwortungsbereich des ISP nehmen dann die weitere Vermittlung vor. Technisch wird eine solche Paketvermittlung mittels einer Bitmaske realisiert, anhand derer die 32 Bit in Netzwerk- und Hostteil unterteilt werden. Das Prinzip gleicht somit dem nachfolgend beschriebenen Verfahren der Subnetz-Bildung.
Die obigen Angaben zu adressierbaren Netzwerken und Rechnern sind etwas zu optimistisch, denn so mancher Adresse eines bestimmten Schemas kommt eine besondere Bedeutung zu.
Zunächst einmal stehen die Adressen mit erstem Byte größer als 223 (Multicast und Experimental) nicht für die eigentliche IP-Adressierung zur Verfügung.
Aus jedem der Klassen A, B und C ist ein Adressbereich als so genannter privater Bereich ausgewiesen. Solche Adressen werden vom keinem Router im Internet vermittelt, womit sie sich zum Aufbau lokaler Netzwerke eignen (theoretisch kann jede Adresse hierfür heran gezogen werden, jedoch nur, wenn das lokale Netz über keine direkte Verbindung zum Internet verfügt). Die Bereiche sind 10.0.0.0 - 10.255.255.255 (Klasse A), 172.16.0.0 - 172.31.255.255 (Klasse B) und 192.168.0.0 - 192.168.255.255 (Klasse C).
Die Adresse 0.0.0.0 wird als Standardroute bezeichnet und wird für die Weiterleitung von Adressen mit unbekannter Route verwendet.
Das Loopback-Netzwerk umfasst die Adressen 127.0.0.0-127.255.255.255. Über derartige Adressen ist es Netzwerkprogrammen möglich, den lokalen Rechner auf gleiche Art und Weise wie entfernte Rechner zu adressieren.
Jede IP-Adresse, deren Hostteil nur aus Nullen besteht, bezeichnet das Netzwerk selbst (Netzwerkadresse). Rechner, die ihre IP-Adresse zum Bootzeitpunkt nicht kennen (können), verwenden bspw. diese Adresse, um via DHCP oder BOOTP diese von einem Server zu erfahren.
Ein komplett aus Einsen bestehender Rechnerteil adressiert alle im Netzwerk befindlichen Rechner auf einmal und wird als Broadcastadresse bezeichnet.
| Subnetze |
|
Die Administration von Netzwerken mit nahezu 64000 (Klasse B) oder gar 16 Millionen von Rechnern (Klasse A) erweist sich als nicht praktikabel. Zum einen kann keine heutige Technologie einen befriedigenden Durchsatz bei einer solchen Menge von Teilnehmern in einem einzigen Netz garantieren. Zum anderen wäre wohl jeder Administrator mit einem solch gigantischen Verantwortungsbereich überfordert. Aus diesem Grund wird die Struktur der IP-Adresse - genau genommen, deren Hostteil - zumindest in Klasse-A- und Klasse-B-Netzwerken - in selteneren Fällen auch bei Klasse-C-Netzwerken - lokal »geeignet interpretiert«.
Subnetzwerke ermöglichen die Strukturierung großer Netzwerke nach topologischen oder auch organisatorischen Gesichtspunkten. So könnten die Rechner eines Gebäudes in einem Teilnetzwerk organisiert und gleichzeitig die Verantwortung für einen solchen abgegrenzten Bereich an eine andere Zuständigkeit delegiert sein. Manchmal erfordert bereits die räumliche Ausdehnung der zu vernetzenden Teilnehmer die Unterteilung in Teilnetze, da alle Netzwerktechnologien eine maximal zulässige Entfernung zwischen den Stationen vorschreiben. Ein Nebeneffekt der Strukturierung, bedingt duch »intelligente« Koppelelemente, ist eine Datenfilterung zwischen den Subnetzen, sodass die Last im gesamten Netzwerk merklich sinkt. Subnetzbildung ist aber auch die einzige Möglichkeit, verschiedene Netzwerktechnologien (bspw. Ethernet und Token Ring) in einem einzigen IP-Netzwerk zu vereinen.
Die Bits des Hostteils einer IP-Adresse werden bei der Subnetzbildung nochmals in zwei Teile untergliedert. Die führenden Bits repräsentieren lokal die Adresse des Subnetzwerks; die verbleibenden Bits adressieren einen Rechner eindeutig innerhalb eines solchen Teilnetzes.
Realisiert wird die Abbildung durch Bitmasken. Bei einem gesetzten Bit dieser Maske wird das korrespondierende Bit der IP-Adresse als Netzwerkbit interpretiert; bei einem nicht gesetzten Bit gehört das entsprechende Bit der IP-Adresse zur Hostadresse. Da letztlich einzig die Anzahl gesetzter Bits und nicht deren relative Lage innerhalb der Maske das Verhältnis von Anzahl Subnetzen zu Anzahl Hosts bestimmt, werden die gesetzten Bits stets »linksbündig« angeordnet.
Beispiel: Die Netzwerkmaske zu einem Klasse-B-Netz ist 255.255.0.0 (in Bitdarstellung entspräche dies 16 gesetzten Bits, gefolgt von 16 nicht gesetzten Bits). Zu einem Klasse-B-Netz gehören maximal 65536 Hosts (wir lassen die speziellen IP-Adressen einmal außen vor). Der Administrator entscheidet nun, diese Rechner lokal in 64 Subnetzen zu je 1024 Hosts zu organisieren. Dazu muss er den Hostteil der IP-Adresse so splitten, dass die höherwertigen 6 Bits (26=64) das Subnetzwerk und die »restlichen« 10 Bits die Rechneradresse repräsentieren. In der Subnetzmaske müssen daher die ersten 22 Bits auf "1" stehen, was in dezimaler Darstellung 255.255.252.0 entspricht.
Zur einfachen Lesbarkeit hat sich eine abweichende Schreibweise für IP-Adressen in Subnetzwerken etabliert. Anstatt die Subnetzmaske getrennt anzugeben, werden die relevanten (also die gesetzten) Bits der IP-Adresse nachgestellt. Liegt bspw. 162.168.100.12 in einem Subnetz mit der Maske 255.255.240.0, so ist die Angabe von 162.168.100.12/20 gebräuchlich.
Eine Subnetzmaske wirkt nur im lokalen Netz, d.h. »außerhalb« unseres Netzes wird die IP-Adresse »ganz normal« interpretiert und anhand der durch die Adressklasse vorgegebenen Netzwerkadresse vermittelt. Erst die Rechner im lokalen Netz betrachten die Subnetzmaske und verteilen Pakete anhand der berechneten Subnetzadresse.
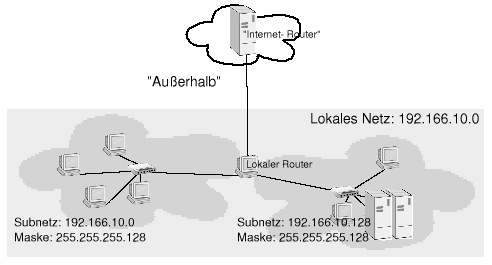
Abbildung 20: Paketvermittlung im Subnetz
Unser lokales Netz mit der Netzwerkadresse 192.166.10.0 (Klasse-C) soll in zwei Teilnetze gesplittet werden. Hierfür genügt ein Bit des Hostteils, woraus sich als Subnetzmaske 255.255.255.128 ergibt. Durch diese Maske gehören alle Rechner mit IP-Adressen 192.166.10.1/25 bis 102.166.10.127/25 zu dem einen und alle Rechner mit IP-Adressen 192.166.10.129/25 bis 102.166.10.254/25 zum anderen Subnetz. Beachten Sie, dass es sich bei 192.166.10.0 und 192.166.10.128 um die Subnetzwerkadressen selbst und bei 192.166.10.128 bzw. 192.166.10.255 um die Broadcastadressen handelt.
Jeder Rechner im gesamten lokalen Netzwerk kennt nun sowohl seine eigene Adresse als auch die Subnetzmaske. Um herauszufinden, ob der Empfänger eines Datenpakets sich im selben Subnetz befindet, muss der Rechner sowohl seine eigene IP als auch die des Adressaten bitweise UND verknüpfen. Sind beide Ergebnisse gleich, befindet sich der Empfänger im selben Teilnetz und das Paket kann direkt an diesen gesendet werden. Andererseits muss das Paket in das andere Subnetz geleitet werden.
Das Koppelglied (Router oder Gateway) zwischen den einzelnen Subnetzen ist Mitglied beider Netze; es besitzt also mehrere Netzwerkschnittstellen mit unterschiedlichen IPs. In der Beispielabbildung stellt ein Router gleichzeitig die Verbindung zur »Außenwelt« her; die auf dieser Schnittstelle verwendete IP-Adresse kann allerdings im Subnetzwerk nicht nochmals vergeben werden.
»Subnetting« bedingt also gleichzeitig ein »Routing«. Um die Problematik der Paketvermittlung soll es im nächsten Abschnitt gehen.
| Routing |

|
Allgemein bezeichnet Routing das Verfahren der Ermittlung des Weges, den ein Paket vom Quell- zum Zielrechner zurückzulegen hat. Routing-Entscheidungen werden einzig anhand von Netzwerkadressen getroffen, indem die Netzwerkmaske auf die eigene IP-Adresse angewendet wird. Im lokalen Netzwerk sind damit die Regeln der Routenfindung für die einzelnen Rechner sehr einfach:
Für die meisten Netzwerkadministratoren hört hier die Arbeit eigentlich schon auf, da das Gateway meist nur eine Route zu einem Gateway eines ISP's (Internet Services Provider) besitzt und die komplexeren Mechanismen der Routenfindung dem Einflussbereich des ISP obliegen.
Große Netzwerke mit mehreren Subnetzwerken - und somit auch mehreren integrierten Gatewayrechnern - können jedoch auch im lokalen Netz den Aufwand des Einrichtens eines Routing-Protokolls rechtfertigen. Fast schon notwendig werden dynamische Routingverfahren, wenn mehrere Gateways des lokalen Netzes eine Anbindung an die »Außenwelt« realisieren und somit unterschiedliche Wege zu einunddemselben Ziel existieren. Auch hier könnte eine statische Route Pakete stets über einundasselbe Gateway leiten, jedoch würde ein solches Verfahren nicht auf Änderungen im Netz (bspw. Ausfall eines Gateways) reagieren können und dem Sinn mehrerer Routen zuwider laufen.
Bevor wir die verschiedenen Möglichkeiten zum Setzen von Routen kennenlernen, betrachten wir den Aufbau der internen Routingtabellen des Linux-Kernels. Ein geeignetes Kommando ist netstat:
|
user@sonne> netstat -rn Kernel IP Routentabelle Ziel Router Genmask Flags MSS Fenster irtt Iface 192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 0.0.0.0 192.168.100.2 0.0.0.0 UG 0 0 0 eth0 |
Unsere Beispieltabelle umfasst zwar nur Einträge, aber sie genügt zur Erläuterung vollauf.
Anhand der Zieladresse wird entschieden, ob ein Eintrag für das aktuelle Routing in Frage kommt. Die Suche in der Tabelle endet nach dem ersten passenden Eintrag!
Bei den Zieladressen kann es sich sowohl um Adressen einzelner Rechner (bspw. ein Rechner am Ende einer Punkt-zu-Punkt-Verbindung) als auch um Netzwerkadressen handeln. Ein mit einer Netzwerkadresse beginnender Eintrag der Routingtabelle passt somit auf alle Adressen aus diesem Netzwerk. Schließlich gilt eine so genannten Defaultadresse (»0.0.0.0«) für jede Adresse.
Router (in manchen Versionen von netstat steht hierfür auch Gateway) ist die Adresse, an die das Paket als nächstes zu senden ist. »0.0.0.0« meint hier, dass die Zieladresse direkt angesprochen wird. Im Beispiel werden somit alle Pakete an Rechner aus dem Netz »168.129.100.0« direkt über die Schnittstelle eth0 an die Rechner gesendet, während Pakete mit anderen Zielen zum Rechner »192.168.100.2« weiter geleitet werden (in der Hoffnung, dass dieser sich darum kümmert).
Der Begriff statisch deutet die Natur dieser Art der Routingkonfiguration bereits an: sie wird vom Systemadministrator vorgegeben und passt sich Änderungen im Netzwerk auch nicht an.