Compression of the BoxTree data structure
Bounding Boxes, in this case the BoxTree, can significantly speed up collision detection, at the cost of having to store the boxes in memory. This cost can be a big disadvantage on systems with limited, or contested resources. As such this thesis improves the memory usage of the BoxTree boxes, by dynamically compressing them during creation, based on the properties of the supplied geometry.
Description
The current BoxTree implementation is focused on speed and not memory usage. In order to not inflate the efficiency of compression, the BoxTree structure was first optimized for size in the optimization phase. This included merging leafs and nodes, switching to indexes instead of pointers and removing duplicated information. This brought the size down from 56 to 16 Bytes, as well as reducing the number of boxes by around 30%.

To eliminate the indexes to the next node, positioning the child-nodes predictively, based on the parent index was tested. Because the BoxTree generates a lot of nodes with only one child for performance reasons, this sadly resulted a lot of unnecessarily allocated space for empty subtrees, making this approach not worth pursuing.
Traversing the BoxTree might only require comparisons against the first few boxes. As such, compression should also be able to decompress only the required nodes to achieve minimal overhead, ruling out the typical compression algorithms for nodes this small. To compress nodes efficiently, only the actually necessary bits for each field are stored. This is possible, because the amount of nodes can be heuristically predetermined at the start of the build process, allowing for a one pass build process. Decompression is also always possible, if the size information is kept and relatively cheap to do, as it only requires shifting and masking of the members.
Only the floats, representing the cuts, can not be compressed this way. In comparison to the unique indexes, they can however be deduplicated, as depending on the size and complexity of the geometry, only around 8-70%, of the floats are actually unique. This means, only compressable indexes to an array of unique floats have to be stored in the nodes.
Results
During optimization, the size of each node has been reduced by ~64%, resulting in a ~82% reduction in overall size, when combined with the reduction of overall nodes from merging leaves into nodes.
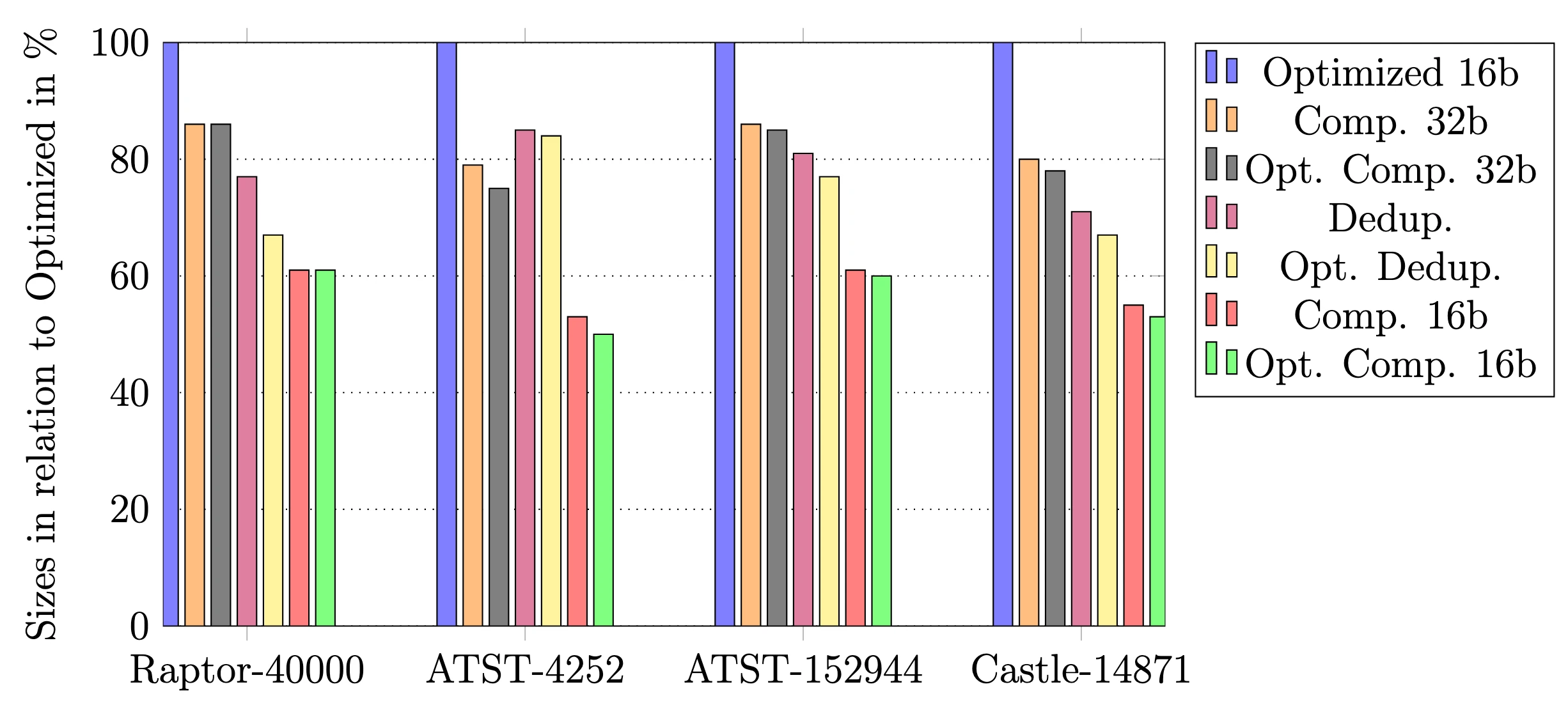
Using this optimized implementation as a new baseline, the maximal compression achievable can be up to 50%. In comparison to the original, this would be ~90%. Notably, the heuristics used to estimate structure member sizes, is almost on par with the optimally achievable. The deduplication of floats for very small objects can however even result in slightly larger size, when compared to the equally precise version without it.

The overhead from decompressing the BoxTree nodes, compared to the optimized implementation is around 40-50%, which is itself around 10% slower, than the performance oriented original.
Files
Full version of the bachelor's thesis (English only)
References
[1] G. Zachmann, “The boxtree: Exact and fast collision detection of arbitrary polyhedra,” 03 2001.
License
This original work is copyright by University of Bremen.
Any software of this work is covered by the European Union Public Licence v1.2.
To view a copy of this license, visit
eur-lex.europa.eu.
The Thesis provided above (as PDF file) is licensed under Attribution-NonCommercial-NoDerivatives 4.0 International![]()
![]()
![]()
![]() .
.
Any other assets (3D models, movies, documents, etc.) are covered by the
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
To view a copy of this license, visit
creativecommons.org.
If you use any of the assets or software to produce a publication,
then you must give credit and put a reference in your publication.
If you would like to use our software in proprietary software,
you can obtain an exception from the above license (aka. dual licensing).
Please contact zach at cs.uni-bremen dot de.