

Netzwerk-Diagnose |
| Übersicht |
|
Das eine oder andere hier aufgeführte Kommando finden Sie auch an anderen Stellen des Buches. Der hiesige Schwerpunkt liegt auf Netzwerkdiagnose, d.h. auf der Verwendung der Kommandos zur Analyse von Netzwerkproblemen. Deshalb finden sie zu Kommandos, die auch für andere Zwecke eingesetzt werden können, im folgenden Abschnitt einzig die zur Inspektion der Netzwerkfunktionalität relevanten Optionen.
Die Fehlersuche gestaltet sich zumeist schwierig. Sie erfordert eine gewisse Methodik, um sich aus der Masse der Möglichkeiten zur wahrscheinlichsten Ursache vorzuarbeiten. Die Reihenfolge der Beschreibung der Ihnen als Administrator zur Seite stehenden Werkzeuge spiegelt die von uns bevorzugte Herangehensweise ab. Wir hangeln uns vom Allgemeinen ins Detail, beginnend bei einfacher Funktionsprüfung bis hin zu Maßnahmen der Optimierung.
| Das Kommando ping/ping6 |
|
Funktional besteht kein Unterschied zwischen ping (IPv4) und ping6 (IPv6), sodass wir in nachfolgender Beschreibung auf eine Unterscheidung verzichten. Verwenden Sie ping in traditionellen IPv4-Netzwerken und ping6 in Netzwerken, die unter IPv6 laufen.
Sollten Sie dennoch einmal einem der Kommandos die »falsche« IP-Adresse unterschieben, so wird dieses den Dienst mit »unknown host« quittieren:
|
user@sonne> ping ::1 ping: unknown host :1 user@sonne> ping6 ::1 PING ::1 (::1): 56 data bytes 64 bytes from ::1: icmp_seq=0 ttl=64 time=0.054 ms 64 bytes from ::1: icmp_seq=1 ttl=64 time=0.052 ms ... |
Das Kommando ping greift auf Systemressourcen zu, die i.d.R. nur für root zugänglich sind. Um dem »normalen« Benutzer dennoch seine Anwendung zu ermöglichen, ist zumeist das setuid-root Flag gesetzt.
ping dient vorrangig zum Testen, Messen und Administrieren von Netzwerken. Es erhöht die Netzwerklast, womit sein Einsatz in automatischen Skripten in Produktionsumgebungen zu vermeiden ist.
»Ping« wurde nach dem Klang von Sonar-Ortungssystemen benannt, wo niederfrequenter Schall in die Tiefen des Ozeans ausgesandt wird, um anhand von Reflexionen den Standort von Objekten zu kalkulieren. Im übertragenen Sinne arbeitet »Ping« analog zu einem Sonar, da es eine Anforderung ins Netzwerk entlässt und anhand der Art und Weise der Reaktion (»Reflexion«) verschiedene Rückschlüsse zu ziehen vermag. Welche das sein können, werden Sie nachfolgend kennen lernen.
Intern arbeitet ping über das ICMP-Protokoll, indem es ein ICMP ECHO_REQUEST (Typ 8) an den entfernten Rechner im Netzwerk sendet, um (hoffentlich) ein ECHO_RESPONSE (Typ 0) als Antwort zu erhalten.
Wichtigste Erkenntnis aus einem ECHO_RESPONSE ist sicherlich, dass die Gegenseite arbeitet und erreichbar ist. Aussagen zur Qualität der Erreichbarbeit lassen sich ebenso ableiten.
Zumindest der Zielrechner ist beim Aufruf des Kommandos als Parameter anzugeben. Ohne weitere Optionen werden ständig ECHO_REQUEST's ausgesendet, d.h. der Zielrechner wird ohne Unterlass »angepingt«. Dies können Sie nur durch Eingabe von [Ctrl][C] unterbrechen. ping schreibt abschließend eine kurze Zusammenfassung auf die Standardausgabe:
|
user@sonne> ping localhost PING localhost (127.0.0.1) from 127.0.0.1 : 56(84) bytes of data. 64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.143 ms 64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.124 ms 64 bytes from localhost (127.0.0.1): icmp_seq=3 ttl=64 time=0.123 ms [Ctrl][C] --- localhost ping statistics --- 3 packets transmitted, 3 received, 0% loss, time 1998ms rtt min/avg/max/mdev = 0.123/0.130/0.143/0.009 ms |
[Ctrl][C] bewirkt das Senden des Signals SIGINT an den Prozess, das im Falle von ping zum Beenden des Programms führt. ping reagiert ebenso auf ein Signal SIGQUIT, womit die Statistik erscheint, ohne das Programm zu beenden. SIGQUIT wird durch keinen Tastencode erzeugt.
Das Ausgabeformat der Statistik ist zum Großteil selbsterklärend. Eine erste Zeile enthält die Anzahl ausgesendeter und empfangener Pakete sowie den Verlustfaktor (in Prozent). Ein letzter Wert gibt die Gesamtzeit des Programmlaufs an.
Die zweite Zeile umfasst vier Zeitwerte. Erster beschreibt die kürzeste Zeitspanne, nach der eine Antwort auf ein ausgesendetes Paket eintraf. Der zweite Wert enthält die längste gemessener Dauer. Dritter Wert ist die durchschnittliche Zeitdauer und Wert Nummer 4 beschreibt die gemittelte Abweichung vom durchschnittlichen Wert.
Etliche Optionen von ping lassen sich nach funktionalen Aspekten gruppieren. Aber eben nicht alle. Die nach unserem Schema nicht »qualifizierbaren« Optionen fassen wir deshalb als »allgemeine« Optionen zusammen. Diese Einteilung ist rein willkürlich!
Die weiter oben beschriebene Anwendung des Kommandos eignet sich nicht zur Verwendung in Skripten, da es zum Beenden eine Interaktion mit dem Benutzer erfordert. Zwei Optionen steuern deshalb das Programmende:
-c Anzahl
-w Sekunden
In Verbindung mit beiden Optionen steht Ihnen zur Auswertung der Rückgabewert des Kommandos ping zur Verfügung. Hierbei bedeutet:
0
1
2
Zwei Beispiele zur Auswertung des Rückgabewertes:
|
user@sonne> ping -c 1 localhost PING localhost (127.0.0.1) from 127.0.0.1 : 56(84) bytes of data. 64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.158 ms --- localhost ping statistics --- 1 packets transmitted, 1 received, 0% loss, time 0ms rtt min/avg/max/mdev = 0.158/0.158/0.158/0.000 ms user@sonne> echo $? 0 |
|
user@sonne> for host in server1 server1; > do > ping -c 1 $host 2>&1 > /dev/null || echo "Rechner $host nicht erreichbar!" > done |
Eher formalen Charakter besitzen folgende Optionen:
-a
-n
-q
In der Voreinstellung versendet ping seine Anforderungen im Sekundentakt. Die Optionen zur Manipulation des Zeitverhaltens erfordern teils Rootrechte, da sie zu extremer Erhöhung der Netzwerklast missbraucht werden könnten.
-i Sekunden
-f
-l Anzahl
-t TimeToLive
|
# Falls 3 Router auf dem Weg liegen... user@sonne> ping -c 1 rechner.irgendwo.foo PING rechner.irgendwo.foo (192.168.99.125) from 192.168.239.100 : 56(84) bytes of data. 64 bytes from rechner.irgendwo.foo (192.168.99.125): icmp_seq=1 ttl=252 time=3.92 ms --- rechner.irgendwo.foo ping statistics --- 1 packets transmitted, 1 received, 0% loss, time 0ms rtt min/avg/max/mdev = 3.926/3.926/3.926/0.000 ms |
Der TTL-Wert in der Endstatistik (obiges Beispiel) wird von dem Rechner gesetzt, der »angepingt« wurde. Die Interpretation des Wertes gestaltet sich schwierig, da es keine feste Regeln gibt, nach denen ein Rechner das Feld belegt. Manche Implementierungen schreiben dort einen Wert, der 255 minus der Anzahl der durchlaufenen Router beträgt. Wiederum andere Rechner verändern den Wert auf 255 oder auf einen Wert, der durch ein übergeordnetes Protokoll des TCP/IP-Protollstacks vorgegeben wird (bspw. arbeitet Telnet mit einen TTL-Wert von 60 oder 30).
Theoretisch ist es also möglich, dass ein Rechner per ping erreichbar ist, der Kontakt via Telnet aber scheitert (wegen des zu geringen TTL-Wertes von Telnet). Praktisch wird ein solcher Fall kaum auftreten, da eine Vermittlung über mehr als 30 Router ein sicheres Indiz für eine Fehlkonfiguration ist (eine Schleife).
Im Abschnitt Netzwerkprotokolle finden Sie eine Beschreibung des Aufbaus eines ICMP-Protokollkopfes. Uns interessiert im Folgenden das in der dortigen Skizze als »Optionale Daten« bezeichnete Feld. Dessen Gröszlig;e findet sich in der Ausgabe des ping-Kommandos wieder:
|
user@sonne> ping -c 1 localhost | head -1 PING localhost (127.0.0.1) from 127.0.0.1 : 56(84) bytes of data. |
Per Voreinstellung verpackt ping 56 Bytes Daten in ein Paket. Dieser Wert trägt auch zur zweiten, in Klammern stehenden Angabe bei. Diese 84 Bytes im Beispiel errechnen sich aus den 20 Bytes des IP-Protokollkopfes, aus 8 Bytes, die Laufzeitinformationen des Pakets enthalten und eben den 56 Datenbytes.
Die Paketgröße ist konfigurierbar:
-s Paketgröße
Die Option eignet sich insbesondere zur Diagnose von Netzwerkproblemen, die auf Probleme mit der Paketgröße hindeuten.
|
user@sonne> ping -c 1 -s 0 localhost | head -1 PING localhost (127.0.0.1) from 127.0.0.1 : 0(28) bytes of data. root@sonne> ping -c 1 -s 65508 localhost | head -1 WARNING: packet size 65508 is too large. Maximum is 65507 ping: local error: Message too long, mtu=16436 |
In letztem Beispiel provozierten wir einen Überlauf, indem wir ein für IP zu großes Datenpaket verwendeten (das Maximum ist fest im Programm implementiert, da hilft auch keine Änderung an der MTU).
Selbst das Muster der Testdaten kann per Option eingestellt werden:
-p Muster
|
user@sonne> ping -p xx localhost ping: patterns must be specified as hex digits. user@sonne> ping -p ff -c 1 localhost | head -1 PATTERN: 0xff |
Ein ausbleibendes ECHO_REQUEST muss nicht den Ausfall des Zielrechners bedeuten. Ebensogut könnte einer der Vermittlerstellen (Router, Gateway,...) streiken. Die Aufzeichnung der Wegstrecke, die ein Paket passierte, kann unter Umständen weiter helfen:
-R
|
user@sonne> ping -c 2 -R lkap1073 PING lkap1073.meine-firma.de (191.0.9.104) from 187.0.34.197 : 56(124) bytes of data. 64 bytes from lkap1073.meine-firma.de (191.0.9.104): icmp_seq=1 ttl=127 time=1.35 ms NOP RR: lkcp38.meine-firma.de (187.0.34.197) zsnr2-if17-vl10.meine-firma.de (191.0.100.10) lkap1073.meine-firma.de (191.0.9.104) lkcr2.meine-firma.de (187.0.34.10) lkcp38.meine-firma.de (187.0.34.197) 64 bytes from lkap1073.meine-firma.de (191.0.9.104): icmp_seq=2 ttl=127 time=1.35 ms NOP (same route) --- lkap1073.meine-firma.de ping statistics --- 2 packets transmitted, 2 received, 0% loss, time 1002ms rtt min/avg/max/mdev = 1.350/1.351/1.352/0.001 ms |
Die Erreichbarkeit aller Rechner eines Netzwerks kann mit einem Broadcast erreicht werden:
-b
Da alle Rechner einunddasselbe Paket erhalten, entstehen Duplikate bei der Antwort, die ping durch ein nachgestellten DUP! in der Ausgabe kennzeichnet:
|
user@sonne> ping -b -c 2 187.0.34.0 WARNING: pinging broadcast address PING 187.0.34.0 (187.0.34.0) from 187.0.34.197 : 56(84) bytes of data. 64 bytes from 187.0.34.197: icmp_seq=1 ttl=64 time=0.049 ms 64 bytes from 187.0.34.236: icmp_seq=1 ttl=255 time=0.163 ms (DUP!) 64 bytes from 187.0.34.206: icmp_seq=1 ttl=255 time=0.211 ms (DUP!) 64 bytes from 187.0.34.196: icmp_seq=1 ttl=255 time=0.213 ms (DUP!) 64 bytes from 187.0.34.181: icmp_seq=1 ttl=255 time=0.220 ms (DUP!) 64 bytes from 187.0.34.174: icmp_seq=1 ttl=255 time=0.243 ms (DUP!) 64 bytes from 187.0.34.133: icmp_seq=1 ttl=255 time=0.245 ms (DUP!) 64 bytes from 187.0.34.159: icmp_seq=1 ttl=255 time=0.247 ms (DUP!) 64 bytes from 187.0.34.134: icmp_seq=1 ttl=255 time=0.368 ms (DUP!) 64 bytes from 187.0.34.167: icmp_seq=1 ttl=255 time=0.371 ms (DUP!) 64 bytes from 187.0.34.164: icmp_seq=1 ttl=255 time=0.373 ms (DUP!) 64 bytes from 187.0.34.11: icmp_seq=1 ttl=255 time=0.432 ms (DUP!) 64 bytes from 187.0.34.10: icmp_seq=1 ttl=255 time=0.435 ms (DUP!) 64 bytes from 187.0.34.194: icmp_seq=1 ttl=255 time=0.471 ms (DUP!) 64 bytes from 187.0.34.132: icmp_seq=1 ttl=255 time=0.494 ms (DUP!) 64 bytes from 187.0.34.130: icmp_seq=1 ttl=255 time=0.496 ms (DUP!) 64 bytes from 187.0.34.7: icmp_seq=1 ttl=255 time=0.523 ms (DUP!) 64 bytes from 187.0.34.135: icmp_seq=1 ttl=255 time=0.525 ms (DUP!) 64 bytes from 187.0.34.190: icmp_seq=1 ttl=255 time=0.527 ms (DUP!) 64 bytes from 187.0.34.20: icmp_seq=1 ttl=255 time=0.812 ms (DUP!) 64 bytes from 187.0.34.131: icmp_seq=1 ttl=255 time=0.953 ms (DUP!) 64 bytes from 187.0.34.152: icmp_seq=1 ttl=60 time=1.51 ms (DUP!) 64 bytes from 187.0.34.153: icmp_seq=1 ttl=60 time=1.73 ms (DUP!) 64 bytes from 187.0.34.17: icmp_seq=1 ttl=32 time=5.39 ms (DUP!) 64 bytes from 187.0.34.197: icmp_seq=2 ttl=64 time=0.046 ms --- 187.0.34.0 ping statistics --- 2 packets transmitted, 2 received, +23 duplicates, 0% loss, time 1010ms rtt min/avg/max/mdev = 0.046/0.682/5.393/1.038 ms |
| Das Kommando traceroute/tracepath |
|
»Ping« in Verbindung mit der Option »-R« erfüllt scheinbar dieselben Aufgaben wie »traceroute«. Jedoch existieren entscheidende Einschränkungen.
Zunächst vermag »Ping« nur maximal 9 Stationen (»Hops«), die ein Paket durchläuft, aufzuzeichen. Für mehr ist einfach kein Platz in einem ICMP-Request-Paket. Sie können das Verhalten leicht nachvollziehen, wenn Sie nur einen Zielrechner wählen, der »weit genug« entfernt ist:
|
user@sonne> ping -R -c 1 www.heise.de PING www.heise.de (193.99.144.71) from 145.254.78.131 : 56(124) bytes of data. 64 bytes from www.heise.de (193.99.144.71): icmp_seq=1 ttl=245 time=278 ms RR: dialin-145-254-078-131.arcor-ip.net (145.254.78.131) dre-145-253-16-118.arcor-ip.net (145.253.16.118) dre-145-254-6-14.arcor-ip.net (145.254.6.14) dre-145-254-6-34.arcor-ip.net (145.254.6.34) dre-145-254-17-10.arcor-ip.net (145.254.17.10) bln-145-254-18-58.arcor-ip.net (145.254.18.58) ams-ix.arcor-ip.net (193.148.15.123) pos-8-0.mpr1.ams1.nl.mfnx.net (208.184.231.181) pos1-0.mpr2.ams1.nl.mfnx.net (208.184.231.253) --- www.heise.de ping statistics --- 1 packets transmitted, 1 received, 0% loss, time 0ms rtt min/avg/max/mdev = 278.643/278.643/278.643/0.000 ms |
Erst »traceroute« zeigt die fehlenden Zwischenstationen auf:
|
user@sonne> /usr/sbin/traceroute www.heise.de traceroute to www.heise.de (193.99.144.71), 30 hops max, 40 byte packets 1 dre-145-253-1-105.arcor-ip.net (145.253.1.105) 158.395 ms 178.291 ms 188.181 ms 2 dre-145-253-16-97.arcor-ip.net (145.253.16.97) 208.099 ms 228.014 ms 247.940 ms 3 dre-145-254-6-9.arcor-ip.net (145.254.6.9) 277.870 ms 307.814 ms 347.706 ms 4 amd-145-254-16-238.arcor-ip.net (145.254.16.238) 397.616 ms 417.569 ms 447.458 ms 5 ge2-0.mpr1.ams1.nl.mfnx.net (193.148.15.122) 477.370 ms 507.330 ms 537.225 ms 6 pos-0-0.mpr2.ams1.nl.mfnx.net (208.184.231.182) 567.160 ms 587.022 ms 616.952 ms 7 pos2-0.cr2.ams2.nl.mfnx.net (208.184.231.254) 149.019 ms 178.923 ms 198.843 ms 8 so-1-1-0.cr2.fra1.de.mfnx.net (64.125.31.142) 228.753 ms 258.670 ms 288.616 ms 9 pos2-0.er1b.fra1.de.mfnx.net (216.200.116.141) 308.503 ms 328.437 ms 358.360 ms 10 plusline-gw2.fra1.above.net (216.200.116.222) 398.298 ms 428.218 ms 458.146 ms 11 c6.f.de.plusline.net (213.83.57.19) 478.057 ms 507.970 ms 537.914 ms 12 c22.f.de.plusline.net (213.83.19.83) 557.839 ms 587.735 ms 617.674 ms 13 www.heise.de (193.99.144.71) 149.010 ms 168.906 ms * |
Ist der Zielrechner nicht erreichbar, bleibt Ihnen »ping« eine Antwort schuldig. Mit »traceroute« hingegen können Sie mit einiger Sicherheit den Streckenabschnitt identifizieren, der das Problem verursacht.
Und schließlich ermöglicht erst »traceroute« eine Analyse der Laufzeiten der Pakete und die Identifikation eventueller Leistungsengpässe im Netz.
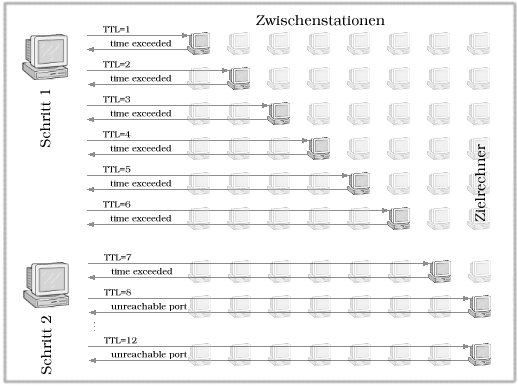
Abbildung 1: Die Arbeitsweise von Traceroute
Zwei Techniken kommen zum Einsatz. Zum einen ist dies die Variation des Time-to-live-Feldes der UDP-Testpakete. Erinnern Sie sich an die Aufgabe dieses TTL-Feldes, das verhindern soll, dass fehl geleitete Pakete ewig im Netz kursieren. Jeder Rechner, den ein Paket passiert, inkrementiert hierzu den Wert des Feldes. Sinkt der Wert auf Null, wird der aktuelle Rechner, insofern er nicht das Ziel markiert, das Paket verwerfen und eine Fehlermitteilung an den Absender initiieren (ICMP-Meldung »Time excceded«). »Traceroute« erzwingt eine solche Fehlernachricht von jeder Zwischenstation, die das Paket durchläuft.
Auf dem Zielrechner kontaktiert »Traceroute« den Port 33434. In der Regel wartet niemals ein Programm auf diesem Port, sodass der Rechner den Verbindungswunsch als Fehler interpretiert und seinerseits mir der ICMP-Mitteilung »Unreachable Port« antwortet. Hieran erkennt »Traceroute« das Erreichen des Ziels.
Aus Effizienzgründen sendet »Traceroute« zu einer Zeit gleich mehrere UDP-Pakete aus (im Beispiel aus Abbildung 1 sind es 6). Des Weiteren wird in der Voreinstellung jedes Paket genau drei Mal versandt, um zum Einen eine gewisse Resistenz gegenüber Fehlern zu wahren (bspw. darf ein Router bei Überlastung Pakete verwerfen, ohne entsprechende Fehlerpakete auszusenden) und zum Anderen mehrere Zeitmessungen vorzunehmen (um »Ausreißer« zu markieren). Fehlversuche kennzeichnet »Traceroute« mit einem Stern (*). Es ist durchaus mölgich, dass »Traceroute« einen Weg zum Ziel findet, obwohl ein Zwischenrechner scheinbar nicht erreichbar ist (nur Sterne in der Ausgabe). Ursachen sind zumeist Fehler in »Traceroute«-Implementierungen mancher Unix-Systeme, die dazu führen, dass die »Time exceeded« Fehlermitteilung den Absender nicht erreichen.
Anmerkung: Manche Netzwerkrouter können so konfiguriert werden, dass sie »Traceroute«-Pakete ignorieren, d.h. sie weiter leiten, ohne das TTL-Feld anzutasten. Deshalb muss die aufgezeichnete Route nicht vollständig sein (eine Option -R, um auch solche Router aufzuzeichnen, existiert zwar, ist jedoch in der aktuellen Version nicht implementiert).
-q <Anzahl>
|
user@sonne> /usr/sbin/traceroute -q 4 www.heise.de | head -4 traceroute to www.heise.de (193.99.144.71), 30 hops max, 40 byte packets 1 dre-145-253-1-103.arcor-ip.net (145.253.1.103) 119.121 ms 169.047 ms 188.981 ms 208.920 ms 2 dre-145-253-16-98.arcor-ip.net (145.253.16.98) 228.861 ms 248.794 ms 268.735 ms 288.668 ms 3 dre-145-254-6-13.arcor-ip.net (145.254.6.13) 318.605 ms 348.546 ms 368.478 ms 398.416 ms |
Anmerkung: In einigen (älteren) Programmversionen stürzt »Traceroute« bei hohen Werten mit einen Segmentation fault (Speicherschutzverletzung) ab oder es verweigert das Setzen des TTL-Wertes. Eine Aktualisierung auf die neueste Version behebt die Ursachen.
-w <Anzahl>
-N <Anzahl>
-f <Start-TTL>
-F
-m <max_hops>
|
user@sonne> /usr/sbin/traceroute -n -m 3 www.heise.de traceroute to www.heise.de (193.99.144.71), 3 hops max, 40 byte packets 1 145.253.1.105 119.031 ms 138.962 ms 168.899 ms 2 145.253.16.97 198.829 ms 228.763 ms 258.696 ms 3 145.254.6.9 288.624 ms 438.560 ms 448.500 ms |
-I <Interface>
-S <Quell-IP>
-g <Gateway>
-t <Type of Service>
-n
|
user@sonne> /usr/sbin/traceroute -n www.heise.de traceroute to www.heise.de (193.99.144.71), 30 hops max, 40 byte packets 1 145.253.1.105 189.075 ms 198.996 ms 218.929 ms 2 145.253.16.97 228.873 ms 248.803 ms 258.757 ms 3 145.254.6.9 288.675 ms 308.602 ms 338.519 ms 4 145.254.16.238 398.466 ms 428.395 ms 448.348 ms 5 193.148.15.122 488.293 ms 508.211 ms 528.148 ms 6 208.184.231.182 558.069 ms 598.005 ms 627.933 ms 7 208.184.231.254 429.692 ms 459.618 ms 479.550 ms 8 64.125.31.142 456.574 ms 486.505 ms 516.440 ms 9 216.200.116.141 469.589 ms 499.526 ms 529.455 ms 10 216.200.116.222 439.595 ms 469.529 ms 509.456 ms 11 213.83.57.19 457.729 ms 477.657 ms 507.585 ms 12 213.83.19.83 429.704 ms 459.633 ms 489.57 ms 13 193.99.144.71 449.649 ms 469.590 ms * |
-4
-6
Paketlänge
Anmerkung: Die Optionen -4 bzw. -6 erübrigen sich, wenn der Zielrechner als IP-Adresse angegeben wird. In dem Fall entscheidet »Traceroute« anhand des Adressformats, nach welchem Mechanismus vorzugehen ist.
Für Fälle, in denen es einzig um den Test des Routenverlaufs geht, ist »Traceroute« mit der Fülle seiner Optionen quasi überqualifiziert, zumal etliche Optionen die Rechte des Administrators bedingen. Oft genügt tracepath, das keine Optionen kennt und vom »jedem« Benutzer verwendet werden darf. Neben der Angabe der Zieladresse kann optional der zu verwendende Port vorgegeben werden. Ohne diesen wählt »Tracepath« zufällig einen Port aus einem definierten Pool (i.d.R.) ungültiger Portnummern aus.
|
user@sonne> /usr/sbin/tracepath www.heise.de 1?: [LOCALHOST] pmtu 1500 1: dre-145-253-1-105.arcor-ip.net (145.253.1.105) 658.744ms 2: dre-145-253-16-97.arcor-ip.net (145.253.16.97) 669.516ms 3: dre-145-254-6-9.arcor-ip.net (145.254.6.9) 667.342ms 4: amd-145-254-16-238.arcor-ip.net (145.254.16.238) asymm 7 689.634ms 5: ge2-0.mpr1.ams1.nl.mfnx.net (193.148.15.122) asymm 8 695.013ms 6: pos-0-0.mpr2.ams1.nl.mfnx.net (208.184.231.182) asymm 9 689.666ms 7: pos2-0.cr2.ams2.nl.mfnx.net (208.184.231.254) asymm 10 689.717ms 8: so-1-1-0.cr2.fra1.de.mfnx.net (64.125.31.142) asymm 10 688.892ms 9: pos2-0.er1b.fra1.de.mfnx.net (216.200.116.141) asymm 10 690.307ms 10: plusline-gw2.fra1.above.net (216.200.116.222) asymm 11 689.343ms 11: c6.f.de.plusline.net (213.83.57.19) asymm 9 689.566ms 12: c22.f.de.plusline.net (213.83.19.83) asymm 10 689.310ms 13: www.heise.de (193.99.144.71) asymm 11 689.836ms reached Resume: pmtu 1500 hops 13 back 11 |
| Das Kommando arp |
|
Während im Internet Pakete anhand ihrer IP-Adresse vermittelt werden, erfolgt in lokalen Netzen die Adressierung mittels Hardwareadressen. So besitzt jede Ethernetnetzwerkkarte eine (weltweit) eindeutige 48 Bit lange Adresse. Das Ermitteln der Hardwareadresse des Rechners zu einer gegebenen IP-Adresse erfolgt durch das Address Resolution Protocol.
Einmal ermittelte Zuordnungen speichert der Linuxkernel in einem internen Zwischenspeicher (»arp-Cache«), um wiederholte Anfragen ohne teure Rechercheoperationen bedienen zu können. In der üblichen Konfiguration stehen 256 Einträge im Cache zur Verfügung. Lange Zeit nicht verwendete Adressen werden nach einer maximalen Verweildauer oder bei Bedarf (voller Cache) entfernt.
Mit dem Kommando arp steht dem Administrator ein Werkzeug zur manuellen Inspektion und Manipulation des Arp-Caches zur Verfügung.
Für den Fall, dass ein Rechner via Netzwerk nicht erreichbar ist, kann ein Blick in den Arp-Cache helfen, um Probleme auf Hardwareebene auszuschließen. Vorhandene Einträge (die nicht manuell eingefügt wurden) sind sichere Anzeichen für eine funktionierende Anbindung.
|
user@sonne> arp Address HWtype HWaddress Flags Mask Iface pluto.galaxsis.de ether 00:A0:C9:FC:1F:45 C eth0 mars.galaxis.de ether 00:40:05:A1:A6:C4 C eth0 erde.galaxis.de ether 00:B0:15:AA:AA:11 C eth0 |
Eine an die arp-Implementierung auf BSD-Systemen angelehnte Form der Ausgabe vermag arp ebenso zu erzeugen.
-a
|
user@sonne> arp -a pluto.galaxsis.de (192.168.239.1) at 00:A0:C9:FC:1F:45 [ether] on eth0 mars.galaxsis.de (192.168.239.2) at 00:40:05:A1:A6:C4 [ether] on eth0 erde.galaxsis.de (192.168.109.2) at 00:B0:15:AA:AA:11 [ether] on eth0 |
Auch zur Ausgabe erweiterter Informationen und zur Anzeige numerischer Adressen anstatt Rechnernamen stehen Optionen zur Verfügung.
-n
-v
|
user@sonne> arp -vn Address HWtype HWaddress Flags Mask Iface 192.168.239.5 ether 00:02:B3:2E:65:AE C eth0 192.168.239.1 ether 00:A0:C9:FC:1F:45 C eth0 192.168.239.2 ether 00:40:05:A1:A6:C4 C eth0 192.168.239.12 ether 00:D0:B7:4D:D7:E1 C eth0 Entries: 4 Skipped: 0 Found: 4 |
-H Typ
-i <Schnittstelle>
| Das Kommando netstat |
|
| Das Kommando route |
|
| Das Kommando ifconfig |
|
| Das Kommando bing |
|
| Das Kommando nmap |

|